How IBM lost the cloud
 At first, Genesis still lacked support for the key virtual private cloud
technology that both engineers and salespeople had identified as important to
most prospective cloud buyers. This caused a split inside IBM Cloud: A group
headed by the former Verizon executives continued to work on the Genesis
project, while another group, persuaded by a team from IBM Research that
concluded Genesis would never work, began designing a separate infrastructure
architecture called GC that would achieve the scaling goals and include the
virtual private cloud technology using the original SoftLayer infrastructure
design. Genesis would never ship. It was scrapped in 2017, and that team began
work on its own new architecture project, internally called NG, that ran in
parallel to the GC effort. For almost two years, two teams inside IBM Cloud
worked on two completely different cloud infrastructure designs, which led to
turf fights, resource constraints and internal confusion over the direction of
the division.
At first, Genesis still lacked support for the key virtual private cloud
technology that both engineers and salespeople had identified as important to
most prospective cloud buyers. This caused a split inside IBM Cloud: A group
headed by the former Verizon executives continued to work on the Genesis
project, while another group, persuaded by a team from IBM Research that
concluded Genesis would never work, began designing a separate infrastructure
architecture called GC that would achieve the scaling goals and include the
virtual private cloud technology using the original SoftLayer infrastructure
design. Genesis would never ship. It was scrapped in 2017, and that team began
work on its own new architecture project, internally called NG, that ran in
parallel to the GC effort. For almost two years, two teams inside IBM Cloud
worked on two completely different cloud infrastructure designs, which led to
turf fights, resource constraints and internal confusion over the direction of
the division.How Can Artificial Intelligence Transform Software Testing?
The increase of automated testing has coincided with the acceptance of agile methodologies in software development. This allows the QA specialists group to deliver error-free and robust software in small batches. Manual test is restricted to business acceptance test merely. DevOps test along with Automation helps agile groups to ship a guaranteed product for SaaS/ cloud deployment through a Continuous Integration/ Continuous Delivery pipeline. In software testing, Artificial Intelligence is a blend of machine learning, cognitive automation, reasoning, analytics, and natural language processing. Cognitive automation leverages several technological approaches such as data mining, semantic technology, text analytics, machine learning, and natural language processing. For instance, Robotic Process Automation (RPA) is one such connecting link between Artificial Intelligence and Cognitive Computing.GriftHorse Money-Stealing Trojan Takes 10M Android Users for a Ride
 The creators of the apps have employed several novel techniques to help the
apps stay off the radar of security vendors, the analysis found. In addition
to the no-reuse policy for URLs mentioned above, the cybercriminals are also
developing the apps using Apache Cordova. Cordova allows developers to use
standard web technologies – HTML5, CSS3 and JavaScript – for cross-platform
mobile development – which in turn allows them to push out updates to apps
without requiring user interaction. “[This] technology can be abused to host
the malicious code on the server and develop an application that executes this
code in real-time,” according to Zimperium. “The application displays as a web
page that references HTML, CSS, JavaScript and images.” The campaign is also
supported with a sophisticated architecture and plenty of encryption, which
makes detection more difficult, according to the researchers. For instance,
when an app is launched, the encrypted files stored in the “assets/www” folder
are decrypted using AES.
The creators of the apps have employed several novel techniques to help the
apps stay off the radar of security vendors, the analysis found. In addition
to the no-reuse policy for URLs mentioned above, the cybercriminals are also
developing the apps using Apache Cordova. Cordova allows developers to use
standard web technologies – HTML5, CSS3 and JavaScript – for cross-platform
mobile development – which in turn allows them to push out updates to apps
without requiring user interaction. “[This] technology can be abused to host
the malicious code on the server and develop an application that executes this
code in real-time,” according to Zimperium. “The application displays as a web
page that references HTML, CSS, JavaScript and images.” The campaign is also
supported with a sophisticated architecture and plenty of encryption, which
makes detection more difficult, according to the researchers. For instance,
when an app is launched, the encrypted files stored in the “assets/www” folder
are decrypted using AES.
How to Decide in Self-Managed Projects - a Lean Approach to Governance
If the people in the project can make decisions themselves, we can call it self-managed. By “self-managed” (or self-organized), I mean that the project members can make decisions about the content of the work, and also who does what and by when. Self-managed groups have the advantage that those who do the work are closer to the decisions: decisions are better grounded in operations, and there is more buy-in and deeper insight from those who are going to carry out the tasks into how the tasks fit into the bigger picture. One step further would be to have a self-governed project. ... The trick is to use lean governance, intentionally and in our favor. The goal of governance in a new project is to provide just enough structure to operate well. Just enough team structure to have a clear division of labor. Just enough meeting structure to use our time well. Not more but also not less. That level of “just enough,” of course, depends on the phase of the project.Citi’s big idea: central, commercial banks use shared DLT for “digital money format war”
 The concept involves creating a blockchain with tiers and partitions, on
which central banks perform the same current role dealing with commercial
banks. On the same ledger, commercial banks and emoney providers perform
similar activities as they do now with their clients. Given this is how
things work today and most legislation is technology agnostic, it likely
wouldn’t require legislative changes and may dispense with the need for
CBDCs. In Mclaughlin’s view, the debates around central bank digital
currency (CBDC) frame the conversation as public versus private money. An
alternative perspective is to look at regulated versus unregulated money.
The concept also addresses bank coins or settlement tokens. “If we as
commercial banks think that the right thing to do is for each of us to
create our own coins, again, the regulated sector will be fragmented. And
that will not help in the contest between regulated money and non-regulated
money,” said Mclaughlin. Central bank money, commercial bank money and
emoney are all regulated and represent specific legal liabilities, no matter
their technical form.
The concept involves creating a blockchain with tiers and partitions, on
which central banks perform the same current role dealing with commercial
banks. On the same ledger, commercial banks and emoney providers perform
similar activities as they do now with their clients. Given this is how
things work today and most legislation is technology agnostic, it likely
wouldn’t require legislative changes and may dispense with the need for
CBDCs. In Mclaughlin’s view, the debates around central bank digital
currency (CBDC) frame the conversation as public versus private money. An
alternative perspective is to look at regulated versus unregulated money.
The concept also addresses bank coins or settlement tokens. “If we as
commercial banks think that the right thing to do is for each of us to
create our own coins, again, the regulated sector will be fragmented. And
that will not help in the contest between regulated money and non-regulated
money,” said Mclaughlin. Central bank money, commercial bank money and
emoney are all regulated and represent specific legal liabilities, no matter
their technical form.Major Quantum Computing Strategy Suffers Serious Setbacks
 The key to quantum computing is that, during the computation, you must avoid
revealing what information your qubits encode: If you look at a bit and say
that it holds a 1 or a 0, it becomes merely a classical bit. So you must
shield your qubits from anything that could inadvertently reveal their
value. (More strictly, decide their value — for in quantum mechanics this
only happens when the value is measured.) You need to stop such information
from leaking out into the environment. That leakage corresponds to a process
called quantum decoherence. The aim is to carry out quantum computing before
decoherence can take place, since it will corrupt the qubits with random
errors that will destroy the computation. Current quantum computers
typically suppress decoherence by isolating the qubits from their
environment as well as possible. The trouble is, as the number of qubits
multiplies, this isolation becomes extremely hard to maintain: Decoherence
is bound to happen, and errors creep in.
The key to quantum computing is that, during the computation, you must avoid
revealing what information your qubits encode: If you look at a bit and say
that it holds a 1 or a 0, it becomes merely a classical bit. So you must
shield your qubits from anything that could inadvertently reveal their
value. (More strictly, decide their value — for in quantum mechanics this
only happens when the value is measured.) You need to stop such information
from leaking out into the environment. That leakage corresponds to a process
called quantum decoherence. The aim is to carry out quantum computing before
decoherence can take place, since it will corrupt the qubits with random
errors that will destroy the computation. Current quantum computers
typically suppress decoherence by isolating the qubits from their
environment as well as possible. The trouble is, as the number of qubits
multiplies, this isolation becomes extremely hard to maintain: Decoherence
is bound to happen, and errors creep in.Apple Pay-Visa Vulnerability May Enable Payment Fraud
 The vulnerabilities were detected in iPhone wallets where Visa cards were
set up in "express transit mode," the researchers say. The transit mode
feature, launched in May 2019, enables commuters to make contactless mobile
payments without fingerprint authentication. Threat actors can use the
vulnerability to bypass the Apple Pay lock screen and illicitly make
payments using a Visa card from a locked iPhone to any contactless Europay,
Mastercard and Visa - or EMV - reader, for any amount, without user
authorization, the researchers say. Information Security Media Group could
not immediately ascertain the number of users affected by this
vulnerability. "The weakness lies in the Apple Pay and Visa systems working
together and does not affect other combinations, such as Mastercard in
iPhones, or Visa on Samsung Pay," the researchers note. The researchers, who
come from the University of Birmingham’s School of Computer Science and the
University of Surrey’s Department of Computer Science, found the flaw as
part of a project dubbed TimeTrust.
The vulnerabilities were detected in iPhone wallets where Visa cards were
set up in "express transit mode," the researchers say. The transit mode
feature, launched in May 2019, enables commuters to make contactless mobile
payments without fingerprint authentication. Threat actors can use the
vulnerability to bypass the Apple Pay lock screen and illicitly make
payments using a Visa card from a locked iPhone to any contactless Europay,
Mastercard and Visa - or EMV - reader, for any amount, without user
authorization, the researchers say. Information Security Media Group could
not immediately ascertain the number of users affected by this
vulnerability. "The weakness lies in the Apple Pay and Visa systems working
together and does not affect other combinations, such as Mastercard in
iPhones, or Visa on Samsung Pay," the researchers note. The researchers, who
come from the University of Birmingham’s School of Computer Science and the
University of Surrey’s Department of Computer Science, found the flaw as
part of a project dubbed TimeTrust.How much trust should we place in the security of biometric data?
 Whilst the collection of fingerprint data is very convenient for the border
control forces, how convenient is it for the asylum seekers themselves?
Could they be opening themselves up to greater risks by providing their
data? A potential issue here is the amount of trust that people place in
fingerprints. People assume that fingerprints are an infallible method of
identification. Whilst the chance of two people having matching fingerprints
is infinitesimally small, automated matching systems often do not make use
of the entire fingerprint. Different levels of detail can be used in
matching, with differing levels of reliability. When asked to provide your
fingerprints for identification purposes, how often do we consider how the
matching is performed? Whilst standards exist for the robustness of
fingerprint matching when used within the Criminal Justice System, can we
assume that the same standards apply to border control systems? Generally,
the fewer comparison points to be analyzed, the faster the matching system;
in a border control situation where a large quantity of people are being
processed, it is important to understand how much of a trade-off between
speed and accuracy has occurred.
Whilst the collection of fingerprint data is very convenient for the border
control forces, how convenient is it for the asylum seekers themselves?
Could they be opening themselves up to greater risks by providing their
data? A potential issue here is the amount of trust that people place in
fingerprints. People assume that fingerprints are an infallible method of
identification. Whilst the chance of two people having matching fingerprints
is infinitesimally small, automated matching systems often do not make use
of the entire fingerprint. Different levels of detail can be used in
matching, with differing levels of reliability. When asked to provide your
fingerprints for identification purposes, how often do we consider how the
matching is performed? Whilst standards exist for the robustness of
fingerprint matching when used within the Criminal Justice System, can we
assume that the same standards apply to border control systems? Generally,
the fewer comparison points to be analyzed, the faster the matching system;
in a border control situation where a large quantity of people are being
processed, it is important to understand how much of a trade-off between
speed and accuracy has occurred. The New Security Basics: 10 Most Common Defensive Actions
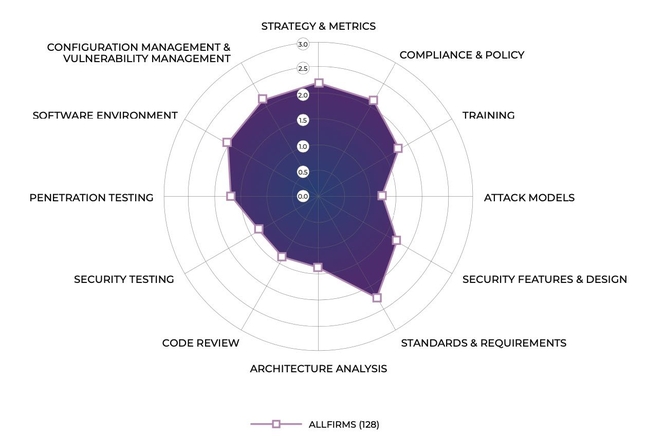 The current assessments found that the growing number of public incidents of
ransomware attacks and attacks on the software supply chain, such as the
compromise of remote management software maker Kaseya, have companies more
focused on activities designed to prevent or mitigate incidents. Over the
past two years, 61% more companies have actively sought to identify open
source — 74 this year versus 46 two years ago — while 55 companies have
begun to mandate boilerplate software license agreements, an increase of 57%
compared with two years ago. "Over the last 18 months, organizations
experienced a massive acceleration of digital transformation initiatives,"
said Mike Ware, information security principal at Navy Federal Credit Union,
a member organization of the BSIMM community, in a statement. "Given the
complexity and pace of these changes, it's never been more important for
security teams to have the tools which allow them to understand where they
stand and have a reference for where they should pivot next."
The current assessments found that the growing number of public incidents of
ransomware attacks and attacks on the software supply chain, such as the
compromise of remote management software maker Kaseya, have companies more
focused on activities designed to prevent or mitigate incidents. Over the
past two years, 61% more companies have actively sought to identify open
source — 74 this year versus 46 two years ago — while 55 companies have
begun to mandate boilerplate software license agreements, an increase of 57%
compared with two years ago. "Over the last 18 months, organizations
experienced a massive acceleration of digital transformation initiatives,"
said Mike Ware, information security principal at Navy Federal Credit Union,
a member organization of the BSIMM community, in a statement. "Given the
complexity and pace of these changes, it's never been more important for
security teams to have the tools which allow them to understand where they
stand and have a reference for where they should pivot next."Cycle Time Breakdown: Reducing Pull Request Pickup Time
There’s nothing worse than working hard for a day or two on a difficult piece of code, creating a pull request for it, and having no one pay attention or even notice. It’s especially frustrating if you specifically assign the Pull Request to a teammate. It’s a bother to have to remember to send emails or slack messages to fellow team members to get them to do a review. No one wants to be a distraction, but the work has to be done, right? So naturally, the conscientious Dev Manager will want to pay close attention to Pull Request Pickup Time (PR Pickup Time), the second segment of a project’s journey along the Cycle Time path. (Go here for the blog post about the first segment, Coding Time) She’ll want to make sure those frustrations described above don’t occur. Keeping Cycle Time “all green” is the goal, but this is often difficult because there are a lot of moving parts that go into managing Cycle Time, including PR Pickup Time.Quote for the day:
"Leaders must see the dream in their mind before they will accomplish the dream with their team." -- Orrin Woodward