Approaching Anomaly Detection in Transactional Data
Apache Kafka: Core Concepts and Use Cases
The initial point that each and every individual who works with streaming applications ought to comprehend is the concept, which is a diminutive piece of data. For instance, when a user registers within the system, an event is created. You can likewise ponder on an event like a message with data, which can be processed and saved at a certain place if at all required. This event is the message wherein the data regarding details such as the user’s name, email, password, and so forth can be added. This highlights that Kafka is the platform that works well when it comes to streaming events. Events are continually composed by producers. They are called producers since they compose events or data to Kafka. There are numerous sorts of producers. Instances of clients include web servers, parts of applications, whole applications, IoT gadgets, monitoring specialists, and so on. A new user registration event can be produced by the component of the site that is liable for client registrations.How to Build a Regression Testing Strategy for Agile Teams
Sam Newman on Information Hiding, Ubiquitous Language, UI Decomposition and Building Microservices
The ubiquitous language in many ways is the key stone of domain-driven design and it's amazing how many people skip it, and it's foundational. I think a lot of the reason that people skip ubiquitous language is because to understand what terms and terminology are used by the business side of your organization by the use of your software, it involves having to talk to people. It still stuns me how many enterprise architects have come up with a domain model by themselves without ever having spoken to anybody outside of IT. So this fundamentally, the ubiquitous language starts with having conversations. This is why I like event storming as a domain-driven design technique because it places primacy on having that kind of collective brainstorming activity where you get sort of maybe your non-developer, your non-technical stakeholders in the room and listen to what they're talking about and you're picking up their terms, their terminology, and you're trying to put those terms into your code.Technical architecture: What IT does for a living
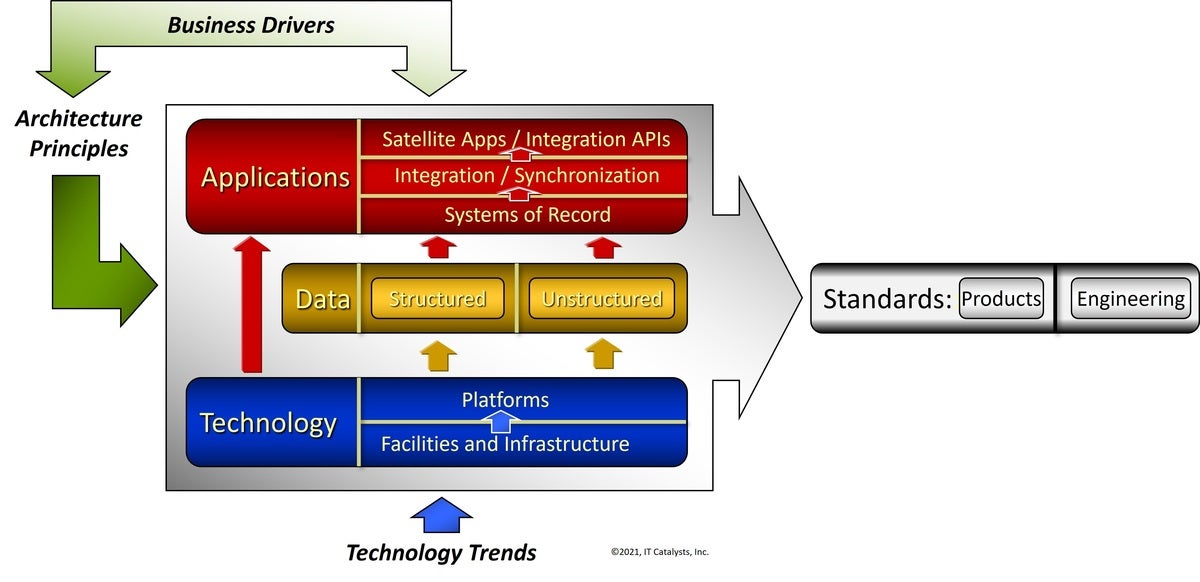 Technical architecture is the sum and substance of what IT deploys to support
the enterprise. As such, its management is a key IT practice. We talked about
how to go about it in a previous article in this series. Which leads to the
question, What constitutes good technical architecture? Or more foundationally,
What constitutes technical architecture, whether good, bad, or indifferent? In
case you’re a purist, we’re talking about technical architecture, not enterprise
architecture. The latter includes the business architecture as well as the
technical architecture. Not that it’s possible to evaluate the technical
architecture without understanding how well it supports the business
architecture. It’s just that managing the health of the business architecture is
Someone Else’s Problem. IT always has a technical architecture. In some
organizations it’s deliberate, the result of processes and practices that matter
most to CIOs. But far too often, technical architecture is accidental — a pile
of stuff that’s accumulated over time without any overall plan.
Technical architecture is the sum and substance of what IT deploys to support
the enterprise. As such, its management is a key IT practice. We talked about
how to go about it in a previous article in this series. Which leads to the
question, What constitutes good technical architecture? Or more foundationally,
What constitutes technical architecture, whether good, bad, or indifferent? In
case you’re a purist, we’re talking about technical architecture, not enterprise
architecture. The latter includes the business architecture as well as the
technical architecture. Not that it’s possible to evaluate the technical
architecture without understanding how well it supports the business
architecture. It’s just that managing the health of the business architecture is
Someone Else’s Problem. IT always has a technical architecture. In some
organizations it’s deliberate, the result of processes and practices that matter
most to CIOs. But far too often, technical architecture is accidental — a pile
of stuff that’s accumulated over time without any overall plan.Preparing for the 'golden age' of artificial intelligence and machine learning
 "Implementing an AI solution is not easy, and there are many examples of where
AI has gone wrong in production," says Tripti Sethi, senior director at Avanade.
"The companies we have seen benefit from AI the most understand that AI is not a
plug-and-play tool, but rather a capability that needs to be fostered and
matured. These companies are asking 'what business value can I drive with data?'
rather than 'what can my data do?'" Skills availability is one of the leading
issues that enterprises face in building and maintaining AI-driven systems.
Close to two-thirds of surveyed enterprises, 62%, indicated that they couldn't
find talent on par with the skills requirements needed in efforts to move to AI.
More than half, 54%, say that it's been difficult to deploy AI within their
existing organizational cultures, and 46% point to difficulties in finding
funding for the programs they want to implement. ... In recent months and years,
AI bias has been in the headlines, suggesting that AI algorithms reinforce
racism and sexism.
"Implementing an AI solution is not easy, and there are many examples of where
AI has gone wrong in production," says Tripti Sethi, senior director at Avanade.
"The companies we have seen benefit from AI the most understand that AI is not a
plug-and-play tool, but rather a capability that needs to be fostered and
matured. These companies are asking 'what business value can I drive with data?'
rather than 'what can my data do?'" Skills availability is one of the leading
issues that enterprises face in building and maintaining AI-driven systems.
Close to two-thirds of surveyed enterprises, 62%, indicated that they couldn't
find talent on par with the skills requirements needed in efforts to move to AI.
More than half, 54%, say that it's been difficult to deploy AI within their
existing organizational cultures, and 46% point to difficulties in finding
funding for the programs they want to implement. ... In recent months and years,
AI bias has been in the headlines, suggesting that AI algorithms reinforce
racism and sexism. Skilling in the IT sector for a post pandemic era – An Experts View
 “When there’s a necessity, innovations follow,” said Mahipal Nair (People
Development & Operations Leader, NielsenIQ). The company moved from
people-interaction-dependent learning to digital methods to navigate skilling
priorities. As consumer expectations change, leadership and social skills have
become a priority for workplace performance. “The way to solve this is not just
to transform current talent, but create relevant talent,” said Nilanjan Kar
(CRO, Harappa). Echoing the sentiment, Kirti Seth (CEO, SSC NASSCOM) added that
“learning should be about principles, and it should enable employees to make the
basics their own.” This will help create a learning organization that can
contextualize change across the industry to stay relevant and map the desired
learning outcomes. While companies upskill their workforce on these priorities,
the real question is what skills will be required? Anupal Banerjee (CHRO, Tata
Technologies) noted that “with the change in skills, there are multiple levels
to focus on. While one focus area is on technical skills, the second is on
behavioral skills. ...”.
“When there’s a necessity, innovations follow,” said Mahipal Nair (People
Development & Operations Leader, NielsenIQ). The company moved from
people-interaction-dependent learning to digital methods to navigate skilling
priorities. As consumer expectations change, leadership and social skills have
become a priority for workplace performance. “The way to solve this is not just
to transform current talent, but create relevant talent,” said Nilanjan Kar
(CRO, Harappa). Echoing the sentiment, Kirti Seth (CEO, SSC NASSCOM) added that
“learning should be about principles, and it should enable employees to make the
basics their own.” This will help create a learning organization that can
contextualize change across the industry to stay relevant and map the desired
learning outcomes. While companies upskill their workforce on these priorities,
the real question is what skills will be required? Anupal Banerjee (CHRO, Tata
Technologies) noted that “with the change in skills, there are multiple levels
to focus on. While one focus area is on technical skills, the second is on
behavioral skills. ...”.Re-evaluating Kafka: issues and alternatives for real-time
 By nature, your Kafka deployment is pretty much guaranteed to be a large-scale
project. Imagine operating an equally large-scale MySQL database that is used by
multiple critical applications. You’d almost certainly need to hire a database
administrator (or a whole team of them) to manage it. Kafka is no different.
It’s a big, complex system that tends to be shared among multiple client
applications. Of course it’s not easy to operate! Kafka administrators must
answer hard design questions from the get-go. This includes defining how
messages are stored in partitioned topics, retention, and team or application
quotas. We won’t get into detail here, but you can think of this task as
designing a database schema, but with the added dimension of time, which
multiplies the complexity. You need to consider what each message represents,
how to ensure it will be consumed in the proper order, where and how to enact
stateful transformations, and much more — all with extreme precision.
By nature, your Kafka deployment is pretty much guaranteed to be a large-scale
project. Imagine operating an equally large-scale MySQL database that is used by
multiple critical applications. You’d almost certainly need to hire a database
administrator (or a whole team of them) to manage it. Kafka is no different.
It’s a big, complex system that tends to be shared among multiple client
applications. Of course it’s not easy to operate! Kafka administrators must
answer hard design questions from the get-go. This includes defining how
messages are stored in partitioned topics, retention, and team or application
quotas. We won’t get into detail here, but you can think of this task as
designing a database schema, but with the added dimension of time, which
multiplies the complexity. You need to consider what each message represents,
how to ensure it will be consumed in the proper order, where and how to enact
stateful transformations, and much more — all with extreme precision.Climbing to new heights with the aid of real-time data analytics
 Enter hybrid analytics. The world of data management has been reimagined with
analytics at the speed of transactions made possible, through simpler processes,
and a single hybrid system breaking down the walls between transactions and
analytics. It’s possible through hybrid analytics to avoid the movement of
information from databases to data warehouses and allow simple real-time data
processing. This innovation enables enhanced customer experiences and a more
data-driven approach to decision making thanks to the deeper business insights
delivered through a hybrid system. Thanks to hybrid analytics, real-time allows
a faster time to insight. It’s also possible for businesses to better understand
their customers with no long, complex processes while the feedback loop is also
made shorter for increased efficiency. It’s this approach that delivers a
data-driven competitive advantage for businesses. Both developers and database
administrators can access and manage data far easier, only having to deal with
one connected system with no database sprawl.
Enter hybrid analytics. The world of data management has been reimagined with
analytics at the speed of transactions made possible, through simpler processes,
and a single hybrid system breaking down the walls between transactions and
analytics. It’s possible through hybrid analytics to avoid the movement of
information from databases to data warehouses and allow simple real-time data
processing. This innovation enables enhanced customer experiences and a more
data-driven approach to decision making thanks to the deeper business insights
delivered through a hybrid system. Thanks to hybrid analytics, real-time allows
a faster time to insight. It’s also possible for businesses to better understand
their customers with no long, complex processes while the feedback loop is also
made shorter for increased efficiency. It’s this approach that delivers a
data-driven competitive advantage for businesses. Both developers and database
administrators can access and manage data far easier, only having to deal with
one connected system with no database sprawl.Why DevSecOps fails: 4 signs of trouble
 When Haff says that some organizations make the mistake of not giving DevSecOps
its due, he adds that the people and culture component is most often the glaring
omission. Of course, it’s not actually “glaring” until you realize that your
DevSecOps initiative has fallen flat and you start to wonder why. One way you
might end up traveling this suboptimal path: You focus too much on technology as
the end-all solution rather than a layer in a multi-faceted strategy. “They
probably have adopted at least some of the scanning and other tooling they need
to mitigate various types of threats. They’re likely implementing workflows that
incorporate automation and interactive development,” Haff says. “What they’re
less likely paying less attention to – and may be treating as an afterthought –
is people and culture.” Just as DevOps was about more than a toolchain,
DevSecOps is about more than throwing security technologies at various risks.
“An organization can get all the tools and mechanics right but if, for example,
developers and operations teams don’t collaborate with your security experts,
you’re not really doing DevSecOps,” Haff says.
When Haff says that some organizations make the mistake of not giving DevSecOps
its due, he adds that the people and culture component is most often the glaring
omission. Of course, it’s not actually “glaring” until you realize that your
DevSecOps initiative has fallen flat and you start to wonder why. One way you
might end up traveling this suboptimal path: You focus too much on technology as
the end-all solution rather than a layer in a multi-faceted strategy. “They
probably have adopted at least some of the scanning and other tooling they need
to mitigate various types of threats. They’re likely implementing workflows that
incorporate automation and interactive development,” Haff says. “What they’re
less likely paying less attention to – and may be treating as an afterthought –
is people and culture.” Just as DevOps was about more than a toolchain,
DevSecOps is about more than throwing security technologies at various risks.
“An organization can get all the tools and mechanics right but if, for example,
developers and operations teams don’t collaborate with your security experts,
you’re not really doing DevSecOps,” Haff says.Quote for the day:
"Authentic leaders are often accused of being 'controlling' by those who idly sit by and do nothing" --John Paul Warren
No comments:
Post a Comment