Fintech is disrupting big banks, but here’s what it still needs to learn from them

As a general rule, fintech’s priorities lean more toward customer convenience than risk management. The sector’s value proposition is based largely on its ability to say yes where traditional finance would say no, allowing more people to take out loans, open credit cards, and open checking accounts than ever before. Just like tech startups that are funded by venture capital, fintechs also place a premium on growth, which makes turning down a potential customer due to credit risk (or any other factor) painful, but essential for sustainable growth. Though it’s definitely possible to grow while managing risk intelligently, it’s also true that pressure to match the “hockey-stick” growth curves of pure tech startups can lead fintechs down a dangerous path. Startups should avoid the example of Renaud Laplanche, former CEO of peer-to-peer lender Lending Club, who was forced to resign in 2016 after selling loans to an investor that violated that investor’s business practices, among other accusations of malfeasance. It’s not just financial risk that they may manage badly: the sexual harassment scandal that recently rocked fintech unicorn SoFi shows that other types of risky behavior can impact bottom lines, too.
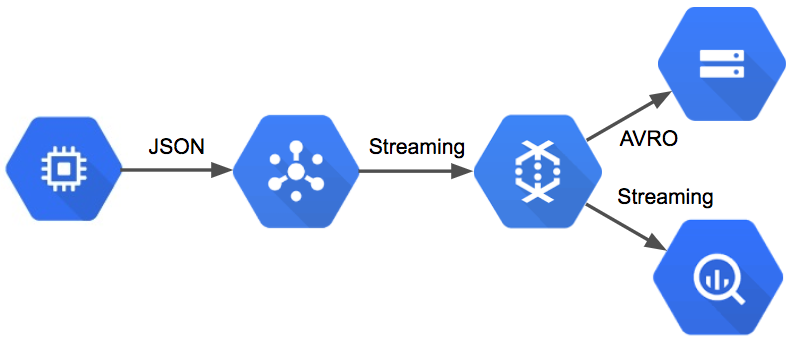
How to mitigate the complexity of microservice communication

"The biggest single challenge arises from the fact that, with microservices, the elements of business logic are connected by some sort of communication mechanism … rather than direct links within program code," said Randy Heffner, principal analyst at Forrester. This means there are more opportunities for errors in network and container configurations, errors in request or response, network blips, and errors in security configurations, configs and more. In other words, there are simply many more places where things can go wrong with microservice communication. It's also much more challenging to debug application logic that flows across multiple microservices. In a monolithic app, a developer can embed multiple debug and trace statements in code that will all automatically go into one log. With microservices, developers need to collect logs and other debugging outputs. They then need to correlate those logs and outputs into a single stream in order to debug a collection of microservices that interact. This is even harder to do when multiple streams of testing are active in an integration testing environment.
27 Incredible Examples Of AI And Machine Learning In Practice

With approximately 3.6 petabytes of data (and growing) about individuals around the world, credit reference agency Experian gets its extraordinary amount of data from marketing databases, transactional records and public information records. They are actively embedding machine learning into their products to allow for quicker and more effective decision-making. Over time, the machines can learn to distinguish what data points are important from those that aren’t. Insight extracted from the machines will allow Experian to optimize its processes. American Express processes $1 trillion in transaction and has 110 million AmEx cards in operation. They rely heavily on data analytics and machine learning algorithms to help detect fraud in near real time, therefore saving millions in losses. Additionally, AmEx is leveraging its data flows to develop apps that can connect a cardholder with products or services and special offers. They are also giving merchants online business trend analysis and industry peer benchmarking.
Skills shortage a major cyber security risk

Security industry leaders are increasingly putting emphasis on cyber resilience based on good detection and response capabilities, rather than relying mainly on defence technologies and controls. “These results reflect the difficulty in defending against increasingly sophisticated attacks and the realisation breaches are inevitable – it’s just a case of when and not if,” said Piers Wilson, director at the IISP. “Security teams are now putting increasing focus on systems and processes to respond to problems when they arise, as well as learning from the experiences of others.” When it comes to investment, the survey suggests that for many organisations, the threats are outstripping budgets in terms of growth. The number of businesses reporting increased budgets dropped from 70% to 64% and businesses with falling budgets increased from 7% up to 12%. According to the IISP, economic pressures and uncertainty in the UK market are likely to be restraining factors on security budgets, while the demands of the General Data Protection Regulation (GDPR) and other regulations such as Payment Services Directive (PSD2) and Networks and Information Systems Directive (NISD) are undoubtedly putting more pressure on limited resources.
Talos finds new VPNFilter malware hitting 500K IoT devices, mostly in Ukraine

While the researchers have said that such a claim isn't definitive, they have observed VPNFilter "actively infecting" Ukrainian hosts, utilising a command and control infrastructure dedicated to that country. The researchers also state VPNFilter is likely state sponsored or state affiliated. As detailed by the researchers, the stage 1 malware persists through a reboot, which normal malware usually does not, with the main purpose of the first stage to gain a persistent foothold and enable the deployment of the stage 2 malware. "Stage 1 utilises multiple redundant command and control (C2) mechanisms to discover the IP address of the current stage 2 deployment server, making this malware extremely robust and capable of dealing with unpredictable C2 infrastructure changes," the researchers wrote. The stage 2 malware possesses capabilities such as file collection, command execution, data exfiltration, and device management; however, the researchers said some versions of stage 2 also possess a self-destruct capability that overwrites a critical portion of the device's firmware and reboots the device, rendering it unusable.
AWS facial recognition tool for police highlights controversy of AI in certain markets

Amazon had also touted the ability to use Rekognition with footage from police body camera systems, though the ACLU notes that mentions of this type of interaction were scrubbed from the AWS website "after the ACLU raised concerns in discussions with Amazon," adding that this capability is still permissible under Amazon's terms of service. This change "appears to be the extent of its response to our concerns," according to the ACLU. Naturally, using cloud services to build a panopticon is likely to generate concern among residents of the localities that have deployed the technology. Under optimal circumstances, this would be implemented following a referendum or, at a minimum, a period of public comment about combining surveillance technology with mass facial recognition. The ACLU sought documents indicating that any such outreach was attempted, though no documents were discovered. It does, however, point out the existence of an internal email from a Washington County employee stating that the "ACLU might consider this the government getting in bed with big data."
DevOps is a culture, but here's why it's actually not

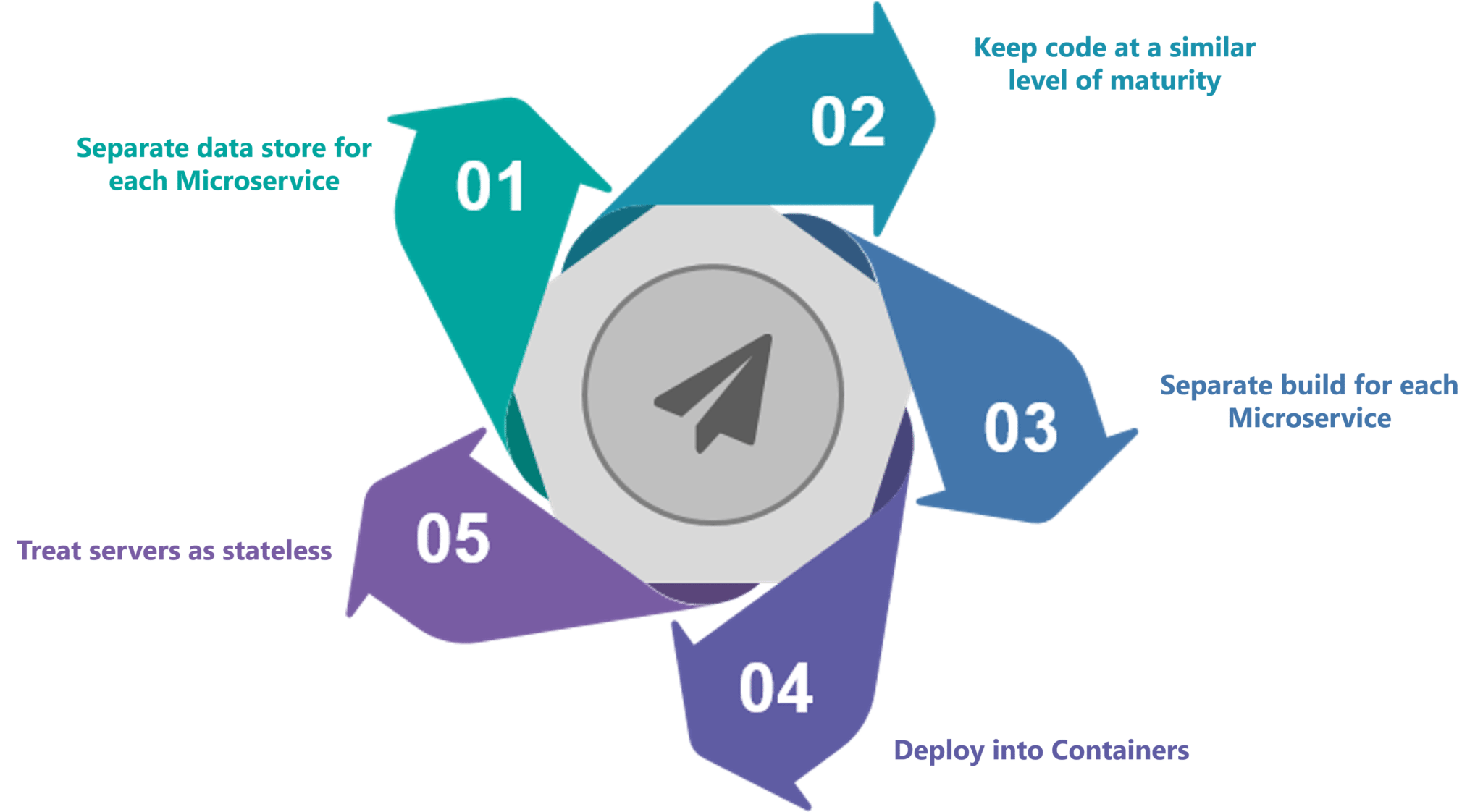
For DevOps to continue to grow, though, we must put the idea that DevOps is a culture aside. That is simply not sufficient and can cause a take everything or nothing approach. DevOps is a transformation process and a collaboration philosophy, and this particular definition comes with different approaches and different criteria for success. It is time to set up standards to help people imagine practical goals and adopt new norms we can all share. Instead of an all or nothing approach, standards unify people and organizations around unique goals that are independent from the used technology, the team size, priority or any other criterion. Setting up standards can also be an iterative process. Take time to think through and grow standards that can continuously shape the interaction between developers, ops, code and servers. And make sure these DevOps standards give the different stakeholders the time to experiment, learn and provide feedback. The 12-factor apps, cloud native or Consortium for IT Software Quality standards are some good examples to follow and consider for iteration.
AI boosts data center availability, efficiency

AI in the data center, for now, revolves around using machine learning to monitor and automate the management of facility components such as power and power-distribution elements, cooling infrastructure, rack systems and physical security. Inside data-center facilities, there are increasing numbers of sensors that are collecting data from devices including power back-up (UPS), power distribution units, switchgear and chillers. Data about these devices and their environment is parsed by machine-learning algorithms, which cull insights about performance and capacity, for example, and determine appropriate responses, such as changing a setting or sending an alert. As conditions change, a machine-learning system learns from the changes – it's essentially trained to self-adjust rather than rely on specific programming instructions to perform its tasks. The goal is to enable data-center operators to increase the reliability and efficiency of the facilities and, potentially, run them more autonomously. However, getting the data isn’t a trivial task.
The path to explainable AI

Traceability also addresses several challenges in AI’s implementation. First, it focuses on the quality in new emerging applications of this advanced technology. Second, in the evolution of human and machine interactions, traceability makes answers more understandable by humans, and helps drive AI’s adoption and related change management necessary for successful implementations. Third, it helps drive compliance in regulated industries such as life sciences, healthcare, and financial services. Traceability exists in some more mature AI applications like computational linguistics. In other emerging technologies that are less mature, the so-called black box problem still tends to appear. This mostly occurs in the context of deep neural networks, machine learning algorithms that are used for image recognition, or natural language processing involving massive data sets. Because the deep neural network is established through multiple correlations of these massive data sets, it is hard to know why it came to a particular conclusion, for now. Companies need a more comprehensive governance structure, especially with these advanced technologies like neural networks that do not permit traceability.
Discussions on the Future of .NET Core
One of the major weaknesses today of .NET Core is the misunderstandings that come with it. Countless developers are still asking, "What's the difference between .NET Core, .NET Standard and .NET Framework". Likewise, which one should they choose and why. The choices aren't always easy or clear. For example it is actually possible to have a .NET Core application that targets the .NET Framework – which if you think about it is really confusing, because we know that both the .NET Framework and .NET Core are runtime implementations of .NET Standard. The .NET Core terminology is overloaded. There are .NET Core applications, .NET Core CLI, .NET Core SDK and .NET Core runtimes. I believe there is much room for improvement with regards to making all of this easier to digest and use. There’s still some work to be done on the performance side of things. Kestrel, the ASP.NET Core web server, performs extremely well in the TechEmpower “plaintext” benchmark, but not so well in the higher-level tests involving database queries and the like. Much of the code that’s been migrated over from the full-fat .NET Framework could be improved a lot in that regard. The great thing is now people are diving into the code and digging these things out.
Quote for the day:
"Prosperity isn't found by avoiding problems, it's found by solving them." -- Tim Fargo