Top 5 Objections to Scrum (and Why Those Objections are Wrong)

Many software development teams are under pressure to deliver work quickly
because other teams have deadlines they need to meet. A common objection to
Agile is that teams feel that when they have a schedule to meet, a traditional
waterfall method is the only way to go. Nothing could be further from the truth.
Not only can Scrum work in these situations, but in my experience, it increases
the probability of meeting challenging deadlines. Scrum works well with
deadlines because it’s based on empiricism, lean thinking, and an iterative
approach to product delivery. In a nutshell, empiricism is making decisions
based on what is known. In practice, this means that rather than making all of
the critical decisions about an initiative upfront, when the least is known,
Agile initiatives practice just-in-time decision-making by planning smaller
batches of work more often. Lean thinking means eliminating waste to focus only
on the essentials, and iterative delivery involves delivering a usable product
frequently.
The Future Is Data Center as a Service

The fact is that whether we realize it or not, we’ve gotten used to thinking of
the data center as a fluid thing, particularly if we use cluster paradigms such
as Kubernetes. We think of pods like tiny individual computers running
individual applications, and we start them up and tear them down at will. We
create applications using multicloud and hybrid cloud architectures to take
advantage of the best situation for each workload. Edge computing has pushed
this analogy even further, as we literally spin up additional nodes on demand,
with the network adjusting to the new topology. Rightfully so; with the speed of
innovation, we need to be able to tear down a data center that is compromised or
bring up a new one to replace it, or to enhance it, at a moment’s notice. In a
way, that’s what we’ve been doing with public cloud providers: instantiating
“hardware” when we need it and tearing it down when we don’t. We’ve been doing
this on the cloud providers’ terms, with each public cloud racing to lock in as
many companies and workloads as possible with a race to the bottom on cost so
they can control the conversation.
DevSecOps: 5 ways to learn more

There’s a clear connection between DevSecOps culture and practices and the open
source community, a relationship that Anchore technical marketing manager Will
Kelly recently explored in an opensource.com article, “DevSecOps: An open source
story.” As you build your knowledge, getting involved in a
DevSecOps-relevant project is another opportunity to expand and extend your
experience. That could range from something as simple as joining a project’s
community group or Slack to ask questions about a particular tool, to taking on
a larger role as a contributor at some point. The threat modeling tool OWASP
Threat Dragon, for example, welcomes new contributors via its Github and
website, including testers and coders. ... The value of various technical
certifications is a subject of ongoing – or at least on-again, off-again –
debate in the InfoSec community. But IT certifications, in general, remain a
solid complementary career development component. Considering a
DevSecOps-focused certification track is in itself a learning opportunity since
any credential worth more than a passing glance should require some homework to
attain.
How Medical Companies are Innovating Through Agile Practices
Within regulatory constraints, there is plenty of room for successful use of
Agile and Lean principles, despite the lingering doubts of some in quality
assurance or regulatory affairs. Agile teams in other industries have
demonstrated that they can develop without any compromise to quality.
Additional documentation is necessary in regulated work, but most of it can be
automated and generated incrementally, which is a well-established Agile
practice. Medical product companies are choosing multiple practices, from both
Agile and Lean. Change leaders within the companies are combining those ideas
with their own deep knowledge of their organization’s patterns and people.
They’re finding creative ways to achieve business goals previously out of
reach with traditional “big design up front” practices. ... Our goal here is
to show how the same core principles in Agile and Lean played out in very
different day-to-day actions at the companies we profiled, and how they drove
significant business goals for each company.
The Importance of Developer Velocity and Engineering Processes

At its core, an organization is nothing more than a collection of moving
parts. A combination of people and resources moving towards a common goal.
Delivering on your objectives requires alignment at the highest levels -
something that becomes increasingly difficult as companies scale. Growth
increases team sizes creating more dependencies and communication channels
within an organization. Collaboration and productivity issues can quickly
arise in a fast-scaling environment. It has been observed that adding
members to a team drives inefficiency with negligible benefits to team
efficacy. This may sound counterintuitive but is a result of the creation of
additional communication lines, which increases the chance of organizational
misalignment. The addition of communication lines brought on by organization
growth also increases the risk of issues related to transparency as teams
can be unintentionally left “in the dark.” This effect is compounded if
decision making is done on the fly, especially if multiple people are making
decisions independent of each other.
Tired of AI? Let’s talk about CI.
Architectures become increasingly complex with each neuron. I suggest
looking into how many parameters GPT-4 has ;). Now, you can imagine how many
different architectures you can have with the infinite number of
configurations. Of course, hardware limits our architecture size, but NVIDIA
(and others) are scaling the hardware at an impressive pace. So far, we’ve
only examined the computations that occur inside the network with
established weights. Finding suitable weights is a difficult task, but
luckily math tricks exist to optimize them. If you’re interested in the
details, I encourage you to look up backpropagation. Backpropagation
exploits the chain rule (from calculus) to optimize the weights. For the
sake of this post, it’s not essential to understand how the learning of the
weights, but it’s necessary to know backpropagation does it very well. But,
it’s not without its caveats. As NNs learn, they optimize all of the weights
relative to the data. However, the weights must first be defined — they must
have some value. This begs the question, where do we start?
How do databases support AI algorithms?

Oracle has integrated AI routines into their databases in a number of ways,
and the company offers a broad set of options in almost every corner of its
stack. At the lowest levels, some developers, for instance, are running
machine learning algorithms in the Python interpreter that’s built into
Oracle’s database. There are also more integrated options like Oracle’s
Machine Learning for R, a version that uses R to analyze data stored in
Oracle’s databases. Many of the services are incorporated at higher levels —
for example, as features for analysis in the data science tools or
analytics. IBM also has a number of AI tools that are integrated with their
various databases, and the company sometimes calls Db2 “the AI database.” At
the lowest level, the database includes functions in its version of SQL to
tackle common parts of building AI models, like linear regression. These can
be threaded together into customized stored procedures for training. Many
IBM AI tools, such as Watson Studio, are designed to connect directly to the
database to speed model construction.
A Comprehensive Guide to Maximum Likelihood Estimation and Bayesian Estimation

An estimation function is a function that helps in estimating the parameters
of any statistical model based on data that has random values. The
estimation is a process of extracting parameters from the observation that
are randomly distributed. In this article, we are going to have an overview
of the two estimation functions – Maximum Likelihood Estimation and Bayesian
Estimation. Before having an understanding of these two, we will try to
understand the probability distribution on which both of these estimation
functions are dependent. The major points to be discussed in this article
are listed below. ... As the name suggests in statistics it is a method for
estimating the parameters of an assumed probability distribution. Where the
likelihood function measures the goodness of fit of a statistical model on
data for given values of parameters. The estimation of parameters is done by
maximizing the likelihood function so that the data we are using under the
model can be more probable for the model.
DORA explorers see pandemic boost in numbers of 'elite' DevOps performers
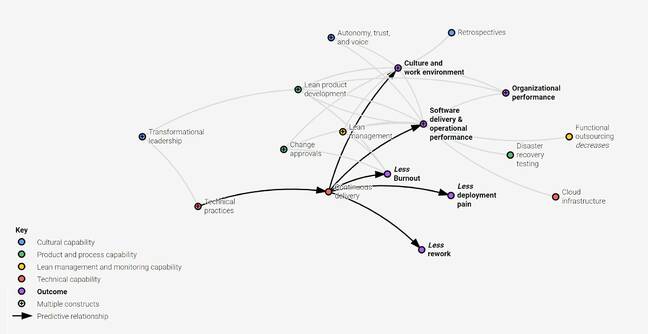
DORA has now added a fifth metric, reliability, defined as the degree to
which one "can keep promises and assertions about the software they
operate." This is harder to measure, but nevertheless the research on which
the report is based asked tech workers to self-assess their reliability.
There was a correlation between reliability and the other performance
metrics. According to the report, 26 per cent of those polled put themselves
into the elite category, compared to 20 per cent in 2019, and seven per cent
in 2018. Are higher performing techies more likely to respond to the survey?
That seems likely, and self-assessment is also a flawed approach; but
nevertheless it is an encouraging trend, presuming agreement that these
metrics and survey methodology are reasonable. Much of the report reiterates
conventional DevOps wisdom. NIST's characteristics of cloud computing [PDF]
are found to be important. "What really matters is how teams implement their
cloud services, not just that they are using cloud technologies," the
researchers said, including things like on-demand self service for cloud
resources.
Why Our Agile Journey Led Us to Ditch the Relational Database

Despite our developers having zero prior experience with MongoDB prior to
our first release, they still were able to ship to production in eight weeks
while eliminating more than 600 lines of code, coming in under time and
budget. Pretty good, right? Additionally, the feedback provided was that the
document data model helped eliminate the tedious work of data mapping and
modeling they were used to from a relational database. This amounted to more
time that our developers could allocate on high-priority projects. When we
first began using MongoDB in summer 2017, we had two collections into
production. A year later, that had grown into 120 collections deployed into
production, writing 10 million documents daily. Now, each team was able to
own its own dependency, have its own dedicated microservice and database
leading to a single pipeline for application and database changes. These
changes, along with the hours saved not spent refactoring our data model,
allowed us to cut our deployment time to minutes, down from hours or even
days.
Quote for the day:
"Inspired leaders move a business
beyond problems into opportunities." -- Dr. Abraham Zaleznik
No comments:
Post a Comment