Man-in-the-middle attacks: A cheat sheet

The concept behind a man-in-the-middle attack is simple: Intercept traffic coming from one computer and send it to the original recipient without them knowing someone has read, and potentially altered, their traffic. MITM attacks give their perpetrator the ability to do things like insert their own cryptocurrency wallet to steal funds, redirect a browser to a malicious website, or passively steal information to be used in later cybercrimes. Any time a third party intercepts internet traffic, it can be called a MITM attack, and without proper authentication it's incredibly easy for an attacker to do. Public Wi-Fi networks, for example, are a common source of MITM attacks because neither the router nor a connected computer verifies its identity. In the case of a public Wi-Fi attack, an attacker would need to be nearby and on the same network, or alternatively have placed a computer on the network capable of sniffing out traffic.
Technical Debt Will Kill Your Agile Dreams
Bad engineering decisions are in a different category to ones that were tactically made with full knowledge that the short-term priority was worth it. When it's clear that such a decision was, in fact, a tactical decision, it is much easier to convince people that refactoring needs to happen and the debt has to be paid off. Unfortunately, when the term is used as a polite way of saying bad engineering, it's unlikely there is any repayment strategy in place and it is even harder to create one because first, you need to convince people there is some bad engineering, then you need to convince people it is causing problems, then you have to consider a better approach and then convince various stakeholders of that too. Finally, you need to convince the investment is needed to refactor. It is like trying to win 5 matches in a row away from home when you don't even have your best players.
3 Keys to a Successful “Pre-Mortem”

The concept of a pre-mortem has been around for years, but only recently have we seen it pick up speed in the engineering community. This is an activity which is run before starting on a big stage in a project, but after doing a product mapping and prioritization activity. Rather than exploring what went wrong after the fact and what to do differently in the future, the goal of a premortem is to identify potential pitfalls and then apply preventative measures. It’s a great idea, but for those new to the concept, it’s easy to overlook some important aspects of the process. To talk about what might go wrong is scary. It acknowledges many things are out of our control, and that we might mess up the things which are within our control. To talk about what might go wrong, and how to adapt to it, acknowledges the possibility of failure. As this is a rare thing in industry, if done initially outside of a structured activity, this can seem like trying to weasel your way out of work.
12 top web application firewalls compared
AWS WAF by itself does not offer the same sort of features you could expect from other solutions on this list, but coupled with other AWS solutions AWS WAF becomes as flexible as any competing solution. Existing AWS customers will see the most value in selecting AWS WaF due to the architecture benefits of staying with a single vendor. ... Each architecture comes with its own set of pros and cons, varying from the simplicity of the SaaS option to the fine-grained control over configuration and deployment with the appliance-based offerings. Barracuda’s various configurations offer very similar functionality, though there are some differences here and there. Server cloaking limits the amount of intel a potential attacker can gain on your configuration by hiding server banners, errors, identifying HTTP headers, return codes, and debug information. Server cloaking is available on all versions of the web application firewall, as is DDoS protection.
Creating a Turing Machine in Rust
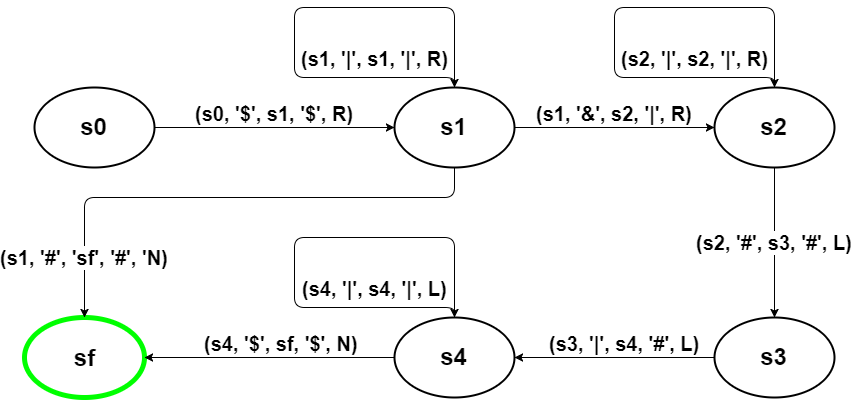
A Turing machine is a mathematical model of computation that reads and writes symbols of a tape based on a table rules. Each Turing machine can be defined by a list of states and a list of transitions. Based on a start state (s0), the Turing machine works its way through all the states until it reaches a final state (sf). If no transition leads to the final state, the Turing machine will run ‘forever’ and eventually run into errors. A transition is defined by the current state, the read symbol at the current position on the tape, the next state and the next symbol that must be written to the tape. Additionally, it contains a direction to determine whether the head of the tape should move the left, right or not at all. To visualize this process, let’s take a look at a very simple Turing machine that increments the value from the initial tape by one. ... While this is a very simple Turing machine, we can use the same model to create machines of any complexity. With that knowledge, we are now ready to lay out the basic structure of our project.
Tech support scammers are using this new trick to bypass security software
Symantec describes this kind of attack technique as 'living off the land', whereby attackers exploit legitimate features in systems to hide malicious activity. In of itself obfuscation isn't malicious, but it can be used for malicious purposes. "There are many open source tools to obfuscate code as developers don't want their code to be seen by the users of their software. Similar is the case with encryption algorithms like AES. Such algorithms have wide usage and implementations in the field of data security," said Siddhesh Chandrayan, threat analysis engineer at Symantec. "Both these mechanisms, by themselves, may not generate an alarm as they are legitimate tools. However, as outlined in the blog, scammers are now using these mechanisms to show fake alerts to the victims. Thus, scammers are 'living off the land' by using 'inherently non-malicious' technology in a malicious way," he added.
Standout predictions for the cloud – a CTO guide

“Many businesses have previously shied away from true multi-cloud deployments by favouring public infrastructures due to the perceived expense of private platforms, rooted in the required expertise necessary to run them. However, recent technological developments that enable businesses to take a highly-automated approach have shown that this is now an outdated view of cloud infrastructure. When it comes to transforming with cloud technologies, multi-cloud is proving itself to be the correct endgame for businesses in all industries.” ... “Enterprises are eliminating all the “state” from their endpoint devices, where any changes are stored only temporarily on the device and are quickly and efficiently on-ramped to the organisation’s cloud. “One key benefit, aside from IT efficiency gains, is that it represents an elimination of the “dark data” that was previously stored in employees’ laptops or desktops. Suddenly, all this “dark” data is right at your fingertips – stored in the cloud– as a searchable, analysable and shareable repository.”
Typemock vs. Google Mock: A Closer Look
Writing tests for C++ can be complicated, especially when you are responsible for maintaining legacy code or working third-party APIs. Fortunately, the C++ marketplace is always expanding, and you have several testing frameworks to choose from. Which one is the best? In this post, we'll consider Typemock vs. Google Mock. We'll use Typemock's Isolator++ and Google Mock, the C++ framework that is bundled with Google Test, to write a test function for a small project. As we implement the tests, we'll examine the difference in how the frameworks approach the same problem. ... Fowler defines an order object that interacts with a warehouse and mail service to fill orders and notify clients. He illustrates different approaches for mocking the mail service and warehouse so the order can be tested. This GitHub project contains Fowler's classes implemented in C++ with tests written in Google Mock. Let's use those classes as a starting point, with some small changes, for our comparison.

Caching can help improve the performance of an ASP.NET Core application. Distributed caching is helpful when working with an ASP.NET application that’s deployed to a server farm or scalable cloud environment. Microsoft documentation contains examples of doing this with SQL Server or Redis, but in this post,I’ll show you an alternative. Couchbase Server is a distributed database with a memory-first (or optionally memory-only) storage architecture that makes it ideal for caching. Unlike Redis, it has a suite of richer capabilities that you can use later on as your use cases and your product expands. But for this blog post, I’m going to focus on it’s caching capabilities and integration with ASP.NET Core. You can follow along with all the code samples on Github. ... No matter which tool you use as a distributed cache (Couchbase, Redis, or SQL Server), ASP.NET Core provides a consistent interface for any caching technology you wish to use.
7 reasons why artificial intelligence needs people

As AI projects roll out over the next few years, we will need to rethink the definition of the “work” that people will do. And in the post-AI era the future of work will become one of the largest agenda items for policy makers, corporate executives and social economists. Despite the strong and inherently negative narrative around the impact on jobs, the bulk of the impact from the automation of work through AI will result in a “displacement” of work not a “replacement” of work – it’s easy to see how the abacus-to-calculator-to-Excel phenomenon created completely new work around financial planning and reporting, and enterprise performance management. Similarly, AI will end up accelerating the future of work and resulting displacement of jobs will be a transition already in place, not an entirely new discussion. As some work gets automated other jobs will get created, in particular ones that require creativity, compassion and generalized thinking.
Quote for the day:
"A single question can be more influential than a thousand statements." -- Bo Bennett
































