Cybersecurity Priorities in 2021: How Can CISOs Re-Analyze and Shift Focus?

The level of sophistication of attacks has increased manifold in the past couple
of years. Attackers leveraging advanced technology to infiltrate company
networks and gain access to mission-critical assets. Given this scenario,
organizations too need to leverage futuristic technology such as next-gen WAF,
intelligent automation, behavior analytics, deep learning, security analytics,
and so on to prevent even the most complex and sophisticated attacks. Automation
also enables organizations to gain speed and scalability in the broader IT
environment with ramped-up attack activity. Security solutions like Indusface's
AppTrana enable all this and more. ... Remote work is here to stay, and the
concept of the network perimeter is blurring. For business continuity,
organizations have to enable access of mission-critical assets to employees
wherever they are. Employees are probably accessing these resources from
personal, shared devices and unsecured networks. CISOs need to think
strategically and implement borderless security based on a zero-trust
architecture.
Benefits of cloud computing: The pros and cons

Cloud computing management raises many information systems management issues
that include ethical (security, availability, confidentiality, and privacy)
issues, legal and jurisdictional issues, data lock-in, lack of standardized
service level agreements (SLAs), and customisation technological bottlenecks,
and others. Sharing a cloud provider has some associated risks. The most common
cloud security issues include unauthorized access through improper access
controls and the misuse of employee credentials. According to industry surveys,
unauthorized access and insecure APIs are tied for the No. 1 spot as the single
biggest perceived security vulnerability in the cloud. Others include internet
protocol vulnerabilities, data recovery vulnerability, metering, billing
evasion, vendor security risks, compliance and legal risks, and availability
risks. When you store files and data in someone else's server, you're trusting
the provider with your crown jewels. Whether in a cloud or on a private server,
data loss refers to the unwanted removal of sensitive information, either due to
an information system error or theft by cybercriminals.
Progressing from a beginner to intermediate developer
In all your programming, you should aim to have a single source of truth for
everything. This is the core idea behind DRY - Don't Repeat Yourself -
programming. In order to not repeat yourself, you need to define everything only
once. This plays out in different ways depending on the context. In CSS, you
want to store all the values that appear time and time again in variables.
Colors, fonts, max-widths, even spacing such as padding or margins are all
properties that tend to be consistent across an entire project. You can often
define variables for a stylesheet based on the brand guidelines, if you have
access. Otherwise it's a good idea to go through the site designs and define
your variables before starting. In JavaScript, every function you write should
only appear once. If you need to reuse it in a different place, isolate it from
the context you're working in by putting it into it's own file. You'll often see
a util folder in JavaScript file structures - generally this is where you'll
find more generic functions used across the app. Variables can also be sources
of truth.
SRE vs. DevOps: What are the Differences?
Site Reliability Engineering, or SRE, is a strategy that uses principles rooted
in software engineering to make systems as reliable as possible. In this
respect, SRE, which was made popular by Google starting in the mid-2000s,
facilitates a shared mindset and shared tooling between software development and
IT operations. Instead of writing software using one set of strategies and
tools, then managing it using an entirely different set, SRE helps to integrate
each practice together by orienting both around concepts rooted in software
engineering. Meanwhile, DevOps is a philosophy that, at its core, encourages
developers and IT operations teams to work closely together. The driving idea
behind DevOps is that when developers have visibility into the problems IT
operations teams experience in production, and IT operations teams have
visibility into what developers are building as they push new application
releases down the development pipeline, the end result is greater efficiency and
fewer problems for everyone.
Distributed transaction patterns for microservices compared
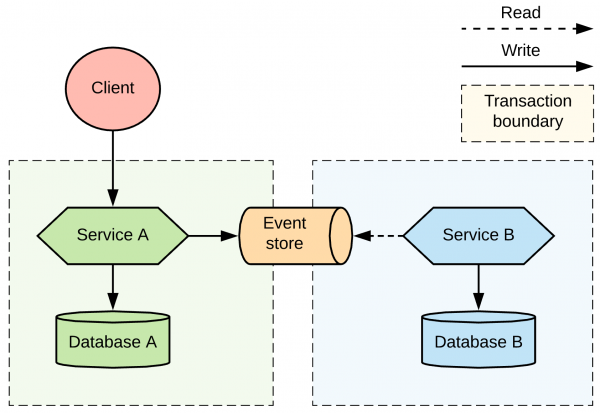
The technical requirements for two-phase commit are that you need a
distributed transaction manager such as Narayana and a reliable storage layer
for the transaction logs. You also need DTP XA-compatible data sources with
associated XA drivers that are capable of participating in distributed
transactions, such as RDBMS, message brokers, and caches. If you are lucky to
have the right data sources but run in a dynamic environment, such as
Kubernetes, you also need an operator-like mechanism to ensure there is only a
single instance of the distributed transaction manager. The transaction
manager must be highly available and must always have access to the
transaction log. For implementation, you could explore a Snowdrop Recovery
Controller that uses the Kubernetes StatefulSet pattern for singleton purposes
and persistent volumes to store transaction logs. In this category, I also
include specifications such as Web Services Atomic Transaction
(WS-AtomicTransaction) for SOAP web services.
5 observations about XDR

Today’s threat detection solutions use a combination of signatures,
heuristics, and machine learning for anomaly detection. The problem is that
they do this on a tactical basis by focusing on endpoints, networks, or cloud
workloads alone. XDR solutions will include these tried-and-true detection
methods, only in a more correlated way on layers of control points across
hybrid IT. XDR will go further than existing solutions with new uses of
artificial intelligence and machine learning (AI/ML). Think “nested
algorithms” a la Russian dolls where there are layered algorithms to analyze
aberrant behavior across endpoints, networks, clouds, and threat
intelligence. Oh, and it kind of doesn’t matter which security telemetry
sources XDR vendors use to build these nested algorithms, as long as they
produce accurate high-fidelity alerts. This means that some vendors will
anchor XDR to endpoint data, some to network data, some to logs, and so on. To
be clear, this won’t be easy: Many vendors won’t have the engineering chops to
pull this off, leading to some XDR solutions that produce a cacophony of false
positive alerts.
Why quantum computing is a security threat and how to defend against it

First, public key cryptography was not designed for a hyper-connected world,
it wasn't designed for an Internet of Things, it's unsuitable for the nature
of the world that we're building. The need to constantly refer to
certification providers for authentication or verification is fundamentally
unsuitable. And of course the mathematical primitives at the heart of that are
definitely compromised by quantum attacks so you have a system which is
crumbling and is certainly dead in a few years time. A lot of the attacks
we've seen result from certifications being compromised, certificates
expiring, certificates being stolen and abused. But with the sort of
computational power available from a quantum computer blockchain is also at
risk. If you make a signature bigger to guard against it being cracked the
block size becomes huge and the whole blockchain grinds to a halt. Think of
the data centers as buckets, three times a day the satellites throw some
random numbers into the buckets and all data centers end up with an identical
bucket full of identical sets of random information.
Government data management for the digital age

Despite the complexity and lengthy time horizon of a holistic effort to
modernize the data landscape, governments can establish and sustain a focus on
rapid, tangible impact. A failure to deliver results from the outset can
undermine stakeholder support. In addition, implementing use cases early on
helps governments identify gaps in their data landscapes (for example, useful
information that is not stored in any register) and missing functionalities in
the central data-exchange infrastructure. To deliver impact quickly,
governments may deploy “data labs”—agile implementation units with
cross-functional expertise that focus on specific use cases. Solutions are
rapidly developed, tested, iterated and, once successful, rolled out at scale.
The German government is pursuing this approach in its effort to modernize key
registers and capture more value. ... Organizations such as Estonia’s
Information System Authority or Singapore’s Government Data Office have played
a critical role in transforming the data landscape of their respective
countries.
Abductive inference: The blind spot of artificial intelligence

AI researchers base their systems on two types of inference machines:
deductive and inductive. Deductive inference uses prior knowledge to reason
about the world. This is the basis of symbolic artificial intelligence, the
main focus of researchers in the early decades of AI. Engineers create
symbolic systems by endowing them with a predefined set of rules and facts,
and the AI uses this knowledge to reason about the data it receives. Inductive
inference, which has gained more traction among AI researchers and tech
companies in the past decade, is the acquisition of knowledge through
experience. Machine learning algorithms are inductive inference engines. An ML
model trained on relevant examples will find patterns that map inputs to
outputs. In recent years, AI researchers have used machine learning, big data,
and advanced processors to train models on tasks that were beyond the capacity
of symbolic systems. A third type of reasoning, abductive inference, was first
introduced by American scientist Charles Sanders Peirce in the 19th
century.
Software Engineering is a Loser’s Game

Nothing is more frustrating as a code reviewer than reviewing someone else’s
code who clearly didn’t do these checks themselves. It wastes the code
reviewer’s time when he has to catch simple mistakes like commented out code,
bad formatting, failing unit tests, or broken functionality in the code. All
of these mistakes can easily be caught by the code author or by a CI pipeline.
When merge requests are frequently full of errors, it turns the code review
process into a gatekeeping process in which a handful of more senior engineers
serve as the gatekeepers. This is an unfavorable scenario that creates
bottlenecks and slows down the team’s velocity. It also detracts from the
higher purpose of code reviews, which is knowledge sharing. We can use
checklists and merge request templates to serve as reminders to ourselves of
things to double check. Have you reviewed your own code? Have you written unit
tests? Have you updated any documentation as needed? For frontend code, have
you validated your changes in each browser your company supports?
Quote for the day:
"Effective leadership is not about
making speeches or being liked; leadership is defined by results not
attributes." -- Peter Drucker
No comments:
Post a Comment