
The researchers from New York University detail in a new paper how they used a neural network to create 'DeepMasterPrints', or realistic synthetic fingerprints that have the same ridges visible when rolling an ink-covered fingertip on paper. The attack is designed to exploit systems that match only a portion of the fingerprint, like the readers used to control access to many smartphones. The aim is to generate fingerprint-like images that match multiple identities to spoof one identity in a single attempt. DeepMasterPrints are an improvement on the MasterPrints the researchers developed last year, which relied on modifying details from already captured fingerprint images used by a fingerprint scanner for matching purposes. The previous method was able to mimic the images stored in the file, but couldn't create a realistic fingerprint image from scratch. The researchers tested DeepMasterPrints against the NIST's ink-captured fingerprint dataset and another dataset captured from sensors.

The strategy of treating containers as logically identical units that can be replaced, spun up, and moved around without much thought works really well for stateless services but is the opposite of how you want to manage distributed stateful services and databases. First, stateful instances are not trivially replaceable since each one has its own state which needs to be taken into account. Second, deployment of stateful replicas often requires coordination among replicas—things like bootstrap dependency order, version upgrades, schema changes, and more. Third, replication takes time, and the machines which the replication is done from will be under a heavier load than usual, so if you spin up a new replica under load, you may actually bring down the entire database or service. One way around this problem—which has its own problems—is to delegate the state management to a cloud service or database outside of your Kubernetes cluster. That said, if we want to manage all of your infrastructure in a uniform fashion using Kubernetes then what do we do?

A data lake is where vast amounts of raw data or data in its native format is stored, unlike a data warehouse which stores data in files or folders (a hierarchical structure). Data lakes provide unlimited space to store data, unrestricted file size and a number of different ways to access data, as well as providing the tools necessary for analysing, querying and processing. In a data lake each data item is assigned with a unique identifier and metadata tags. In this way the data lake can be queried for relevant data and that smaller set of relevant data can be analysed. Also, data can also be stored in data lakes before being curated and moved to a data warehouse. ... The Azure Data Lake is a Hadoop File System (HDFS) and enables Microsoft services such as Azure HDInsight, Revolution-R Enterprise, industry Hadoop distributions like Hortonworks and Cloudera all to connect to it. Azure Data Lake has all Azure Active Directory features including Multi-Factor Authentication, conditional access, role-based access control, application usage monitoring, security monitoring and alerting.
Harvard researchers want to school Congress about AI
Funded by HKS’s Shorenstein Center on Media, Politics, and Public Policy, the initiative will focus on expanding the legal and academic scholarship around AI ethics and regulation. It will also host a boot camp for US Congress members to help them learn more about the technology. The hope is that with these combined efforts, Congress and other policymakers will be better equipped to effectively regulate and shepherd the growing impact of AI on society. Over the past year, a series of high-profile tech scandals have made increasingly clear the consequences of poorly implemented AI. This includes the use of machine learning to spread disinformation through social media and the automation of biased and discriminatory practices through facial recognition and other automated systems. In October, at the annual AI Now Symposium, technologists, human rights activists, and legal experts repeatedly emphasized the need for systems to hold AI accountable. “The government has the long view,” said Sherrilyn Ifill, president and director-counsel of the NAACP Legal Defense Fund.
Role of digitisation and technologies like AI & ML in digital transformation of SMEs?

More specifically, AI-based solutions like automation can be greatly beneficial to SMEs in reducing several processes like sales planning, managing finances and supply chain, marketing, etc. These processes which most SMEs still conduct through offline methods considerably reduce the efficiency of the enterprise, since the managers’ focus is largely on the operations, rather than on serving customers and retaining them. Simultaneously, digitised business management and enterprise mobility solutions can enable SMEs to expand their business to any region within the country or outside, without having to worry about the infrastructural and monetary challenges associated. Customised, enterprise-centric solutions with AI and Machine Learning Every organisation faces a different set of issues and challenges. The solutions, then, to effectively tackle these challenges should also be specific to the business segment, as well as the industry, which the enterprise is involved in.
What Edge Computing Means for Infrastructure and OperationsLeaders
Edge computing solutions can take many forms. They can be mobile in a vehicle or smartphone, for example. Alternatively, they can be static — such as when part of a building management solution, manufacturing plant or offshore oil rig. Or they can be a mixture of the two, such as in hospitals or other medical settings. The capabilities of edge computing solutions range from basic event filtering to complex-event processing or batch processing. “A wearable health monitor is an example of a basic edge solution. It can locally analyze data like heart rate or sleep patterns and provide recommendations without a frequent need to connect to the cloud,” says Rao. More complex edge computing solutions can act as gateways. In a vehicle, for example, an edge solution may aggregate local data from traffic signals, GPS devices, other vehicles, proximity sensors and so on, and process this information locally to improve safety or navigation. More complex still are edge servers, such as those found in next-generation (5G) mobile communication networks.
The rare form of machine learning that can spot hackers who have already broken in
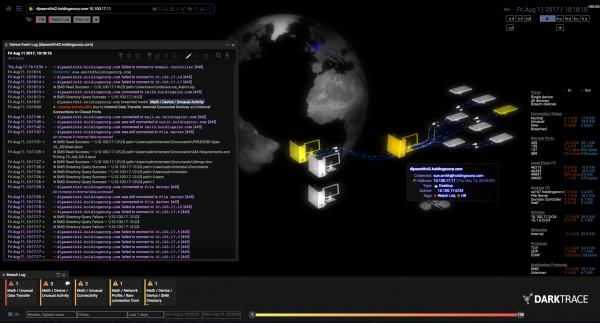
In cybersecurity, supervised learning works pretty well. You train a machine on the different kinds of threats your system has faced before, and it chases after them relentlessly. But there are two main problems. For one, it only works with known threats; unknown threats still sneak in under the radar. For another, supervised-learning algorithms work best with balanced data sets—in other words, ones that have an equal number of examples of what it’s looking for and what it can ignore. Cybersecurity data is highly unbalanced: there are very few examples of threatening behavior buried in an overwhelming amount of normal behavior. Fortunately, where supervised learning falters, unsupervised learning excels. The latter can look at massive amounts of unlabeled data and find the pieces that don’t follow the typical pattern. As a result, it can surface threats that a system has never seen before and needs few anomalous data points to do so.
Building a Web App With Yeoman
Released in 2012, Yeoman is an efficient open-source software system for scaffolding web applications, used for streamlining the development process. It is known primarily for its focus on scaffolding, which means the use of many different tools and interfaces coordinated for optimized project generation. GitHub hosts Yeoman. The Yeoman experience is three-tiered. Though they work together seamlessly, each part of Yeoman was developed separately and works individually. Primarily, Yeoman includes "Yo," the command line utility form used with Yeoman. This is the baseline of the Yeoman software platform. Next, Yeoman has "Grunt," and "Gulp," which are application builders to help automate your application development. Finally, the Yeoman software features "npm", which is a package manager. Package managers manage code packages for back-end and front-end development and their dependencies for you to develop your application. Yeoman provides developers with many options to combine in their development process.
Enterprise architecture still matters

Rather than checking in on how each team is operating, EAs should generally focus on the outcomes these teams have. Following the rule of team autonomy (described elsewhere in this booklet), EAs should regularly check on each team’s outcomes to determine any modifications needed to the team structures. If things are going well, whatever’s going on inside that black box must be working. Otherwise, the team might need help, or you might need to create new teams to keep the focus small enough to be effective. Most cloud native architectures use microservices, hopefully, to safely remove dependencies that can deadlock each team’s progress as they wait for a service to update. At scale, it’s worth defining how microservices work as well, for example: are they event based, how is data passed between different services, how should service failure be handled, and how are services versioned? Again, a senate of product teams can work at a small scale, but not on the galactic scale.
Put Your BLL Monster in Chains
A very popular architecture for enterprise applications is the triplet Application, Business Logic Layer (BLL), Data Access Layer (DAL). For some reason, as time goes by, the Business Layer starts getting fatter and fatter losing its health in the process. Perhaps, I was doing it wrong. Somehow very well designed code gets old and turns into a headless monster. I ran into a couple of these monsters that I have been able to tame using FubuMVC's behaviour chains. A pattern designed for web applications that I have found useful for breaking down complex BLL objects into nice maintainable pink ponies. ... The high code quality is very important if you want a maintainable application with a long lifespan. By choosing the right design patterns and applying some techniques and best practices, any tool will work for us and produce really elegant solutions to our problems. If on the other hand, you learn just how to use the tools, you are going to end up programming for the tools and not for the ones that sign your pay-checks.
Quote for the day:
"A positive attitude will not solve all your problems. But it will annoy enough people to make it worth the effort" -- Herm Albright
No comments:
Post a Comment