How Data Scientists Can Improve Their Coding Skills

Learning is incremental by nature and builds upon what we already know. Learning
should not be drastically distant from our existing knowledge graph, which makes
self-reflection increasingly important. ... After reflecting on what we have
learned, the next step is to teach others with no prior exposure to the content.
If we truly understand it, we can break the concept into multiple digestible
modules and make it easier to understand. Teaching takes place in different
forms. It could be a tutorial, a technical blog, a LinkedIn post, a YouTube
video, etc. I’ve been writing long-form technical blogs on Medium and
shorter-form Data Science primers on LinkedIn for a while. In addition, I’m
experimenting with YouTube videos, which provide a great supplementary channel
to learning. Without these two ingredients, my Data Science journey would have
been more bumpy and challenging. Honestly, all of my aha moments come after
extensive reflection and teaching, which is my biggest motivation to be active
on multiple platforms.
5 Dashboard Design Best Practices

From a design perspective, anything that doesn’t convey useful information
should be removed. Things that don’t add value like chart grids or decorations
are prime examples. This can also include things that look cool but don’t really
add anything to the dashboard like a gauge chart where a simple number value
gives the user the same information while taking up less space. If you are
conflicted, you should probably err on the side of caution and remove something
if it doesn’t add any functional value. Space is a prized dashboard commodity,
so you don’t want to waste any space on things that are just there to look
pretty. Using proportion and relative sizing to display differences in data is
another way to make data easier for viewers to quickly understand. Things like
bubble charts, area charts or Sankey diagrams can be used to visually show
differences that can be understood with a glance. The purpose of a dashboard is
to convey information efficiently so users can make better decisions. This means
you shouldn’t try to mislead people or steer them toward a certain decision.
From The Great Resignation To The Great Migration

Much has been written about The Great Resignation, the trend for over 3.4% of
the US workforce to leave their jobs every month. Yes, the trend is real:
companies like Amazon are losing more than a third of their workers each year,
forcing employers to ramp up hiring like we have never seen before. But while
we often blame the massive quit rate on the Pandemic, let me suggest that
something else is going on. This is a massive and possibly irreversible trend:
that of giving workers a new sense of mobility they’ve never had before.
Consider a few simple facts. Today more than 45% of employees now work
remotely (25% full time), which means changing jobs is a simple as getting a
new email address. Only 11% of companies offer formal career programs for
employees, so in many cases, the only opportunity to grow is by leaving. And
wages, benefits, and working conditions are all a “work in process.” Today US
companies spend 32% of their entire payroll on benefits and most are totally
redesigning them to improve healthcare, flexibility, and education.
How Much Has Quantum Computing Actually Advanced?

Everyone's working hard to build a quantum computer. And it's great that there
are all these systems people are working on. There's real progress. But if you
go back to one of the points of the quantum supremacy experiment—and something
I've been talking about for a few years now—one of the key requirements is
gate errors. I think gate errors are way more important than the number of
qubits at this time. It's nice to show that you can make a lot of qubits, but
if you don't make them well enough, it's less clear what the advance is. In
the long run, if you want to do a complex quantum computation, say with error
correction, you need way below 1% gate errors. So it's great that people are
building larger systems, but it would be even more important to see data on
how well the qubits are working. In this regard, I am impressed with the group
in China who reproduced the quantum supremacy results, where they show that
they can operate their system well with low errors.
How Banks Can Bridge The Data Sharing Privacy Gap

Consent management rules regarding online advertising data collection may be
tightening in numerous European Union markets. The Belgian Data Authority
recently alleged that online advertising trade organization IAB Europe’s
Transparency and Consent Framework (TFC) breaches the EU’s General Data
Protection Regulation (GDPR). Statements from the Irish Council for Civil
Liberties (ICCL), one of the legal coordinators on the case, also alleged IAB
Europe was aware its consent popups violated GDPR. The case highlights why EU
entities must pay careful attention to how consent management standards are
changing to ensure they remain compliant. Experts also predict that GDPR
regulatory oversight surrounding consent management will increase in 2022,
meaning organizations must carefully look at how they structure consent boxes
and other forms provided to customers. It is also becoming increasingly
important for consumers to understand what data they share and which entities
may access their information.
ECB Paper Marks Success Factors for CBDCs, Digital Euro

The first one is ‘merchant acceptance’ which has to be wide, meaning users
should be able to pay digitally anywhere. Unlike paper cash, a digital currency
is likely to come with fees for each transaction and require dedicated devices
to process the payments. There are other differences as well, despite both forms
of money having legal tender status. The ECB elaborates: ... The second success
factor has been defined as ‘efficient distribution.’ The ECB officials quote a
Eurosystem report, according to which a digital euro should be distributed by
supervised intermediaries such as banks and regulated payment providers. To
encourage the distribution of the central bank digital currency, incentives may
be paid to supervised intermediaries. The document divides intermediary services
into two categories: onboarding and funding services — which would include
operations required to open, manage, and close a CBDC account — and payment
services.
Let there be light: Ensuring visibility across the entire API lifecycle

When approaching API visibility, the first thing we have to recognize is that
today's enterprises actively avoid managing all their APIs through one system.
According to IBM's Tony Curcio, Director of Integration Engineering, many of his
enterprise customers already work with hybrid architectures that leverage
classic on-premise infrastructure while adopting SaaS and IaaS across various
cloud vendors. These architectures aim to increase resilience and flexibility,
but are well aware that it complicates centralization efforts' to: 'These
architectures aim to increase resilience and flexibility, but at the cost of
complicating centralization efforts In these organizations, it is imperative to
have a centralized API location with deployment into each of these locations, to
ensure greater visibility and better management of API-related business
activities. The challenge for security teams is that there isn't one central
place where all APIs are managed by the development team - and as time passes,
that complexity is likely to only get worse.
DevOps for Quantum Computing
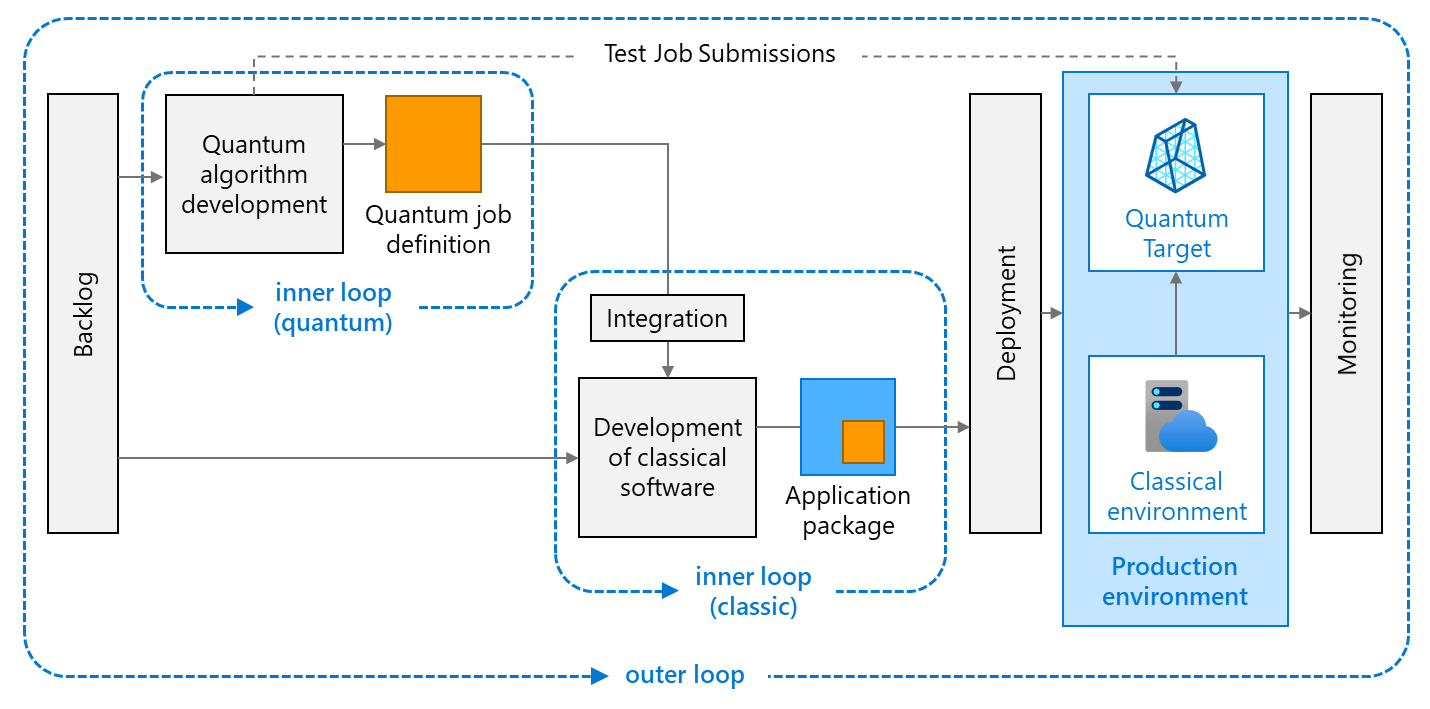
Like any other Azure environment, quantum workspaces and the classical
environments can be automatically provisioned by deploying Azure Resource
Manager templates. These JavaScript Object Notation (JSON) files contain
definitions for the two target environments: The quantum environment contains
all resources required for executing quantum jobs and storing input and output
data: an Azure Quantum workspace connecting hardware providers and its
associated Azure Storage account for storing job results after they are
complete. This environment should be kept in its separate resource group. This
allows separating the lifecycle of these resources from that of the classical
resources; The classical environment contains all other Azure resources
you need for executing the classical software components. Types of resources are
highly dependent on the selected compute model and the integration model. You
would often recreate this environment with each deployment. You can store and
version both templates in a code repository (for example, Azure Repos or GitHub
repositories).
Is the UK government’s new IoT cybersecurity bill fit for purpose?

The bill outlines three key areas of minimum security standards. The first is a
ban on universal default passwords — such as “password” or “admin” — which are
often preset in a device’s factory settings and are easily guessable. The second
will require manufacturers to provide a public point of contact to make it
simpler for anyone to report a security vulnerability. And, the third is that
IoT manufacturers will also have to keep customers updated about the minimum
amount of time a product will receive vital security updates. This new
cybersecurity regime will be overseen by an as-yet-undesignated regulator, that
will have the power to levy GDPR-style penalties; companies that fail to comply
with PSTI could be fined £10 million or 4% of their annual revenue, as well as
up to £20,000 a day in the case of an ongoing contravention. On the face of it,
the PSTI bill sounds like a step in the right direction, and the ban on default
passwords especially has been widely commended by the cybersecurity industry as
a “common sense” measure.
Werner Vogel’s 6 Rules for Good API Design
Once an API is created, it should never be deleted, or changed. “Once you put an
API out there, businesses will build on top of it,” Vogels said, adding that
changing the API will basically break their businesses. Backward capability is a
must. This is not to say you can’t modify, or improve the API. But whatever
changes you make shouldn’t alter the API such that calls coming in from the
previous versions won’t be affected. As an example, AWS has enhanced its Simple
Storage Service (S3) in multiple ways since its launch in 2006, but the
first-generation APIs are still supported. The way to design the APIs is to not
start with what the engineers think would make for a good API. Instead, figure
out what your users need from the API first, and then “work backwards from their
use cases. And then come up with a minimal and simplest form of API that you can
actually offer,” Vogels said. As an example, Vogels described an advertisement
system that can be used for multiple campaigns.
Quote for the day:
"Leaders are visionaries with a poorly
developed sense of fear and no concept of the odds against them." --
Robert Jarvik
No comments:
Post a Comment