The CISO as Sustaining Force: Helping Infosec Staff Beat Burnout

CISOs should also be looking for common signs of burnout itself which team
members might be exhibiting, including: A sharp drop in quantity and timeliness
of output; A general lack of energy and enthusiasm around job
functions; Continual signs of anxiety and stress; An extreme
irritability toward co-workers and duties; and Significant changes in
social patterns with co-workers. If some of these characteristics are present,
the CISO has a few options for addressing them. One is to examine possible
workload issues. Even the most resilient team members can burn out if the
workload is crushing. If a staffer is exhibiting signs of burnout, an assessment
can be made as to whether certain tasks should be spread out among other
staffers, if possible. When taking this route, it's important for the CISO to
let team members know that this is being done to gain more scale, not as a
punitive measure. If the burnout signs point to an especially stressful infosec
assignment, such as protecting assets from threats that are rapidly increasing,
a discussion regarding giving the staffer more support may help them feel less
alone in a challenging situation.
3 big problems with datasets in AI and machine learning

Researchers at the University of California, Los Angeles, and Google
investigated the problem in a recently published study titled “Reduced, Reused
and Recycled: The Life of a Dataset in Machine Learning Research.” They found
that there’s “heavy borrowing” of datasets in machine learning — e.g., a
community working on one task might borrow a dataset created for another task —
raising concerns about misalignment. They also showed that only a dozen
universities and corporations are responsible for creating the datasets used
more than 50% of the time in machine learning, suggesting that these
institutions are effectively shaping the research agendas of the field.
“SOTA-chasing is bad practice because there are too many confounding variables,
SOTA usually doesn’t mean anything, and the goal of science should be to
accumulate knowledge as opposed to results in specific toy benchmarks,” Denny
Britz, a former resident on the Google Brain team, told VentureBeat in a
previous interview. “There have been some initiatives to improve things, but
looking for SOTA is a quick and easy way to review and evaluate papers. Things
like these are embedded in culture and take time to change.”
Building an End-to-End Open-Source Modern Data Platform
The good news is that the serverless option is exactly what we’re looking for at
this stage, even if the product isn’t open-source. That’s because we want
something that can scale in terms of storage and query performance without
necessitating dedicated maintenance efforts. And so the ideal option when
getting started is a serverless managed offering — this is true for all of our
components that necessitate elasticity, not just the data warehouse. ... And so
it would make sense for us to leverage BigQuery as our data warehouse for this
platform, but this doesn’t generalize the choice since in other scenarios it may
be more interesting to opt for another option. When picking your data warehouse,
you should take into account factors like pricing, scalability, and performance
and then pick the option that fits your use case the best. ... In an ELT
architecture, the data warehouse is used to store all of our data layers. This
means that we won’t just use it to store the data or query it for analytical use
cases, but we’ll also leverage it as our execution engine for the different
transformations.
Research Opens the Door to Fully Light-Based Quantum Computing

A team of researchers with Japan's NTT Corporation, the Tokyo University, and
the RIKEN research center have announced the development of a full
photonics-based approach to quantum computing. Taking advantage of the quantum
properties of squeezed light sources, the researchers expect their work to
pave the road towards faster and easier deployments of quantum computing
systems, avoiding many practical and scaling pitfalls of other approaches.
Furthermore, the team is confident their research can lead towards the
development of rack-sized, large-scale quantum computing systems that are
mostly maintenance-free. The light-based approach in itself brings many
advantages compared to traditional quantum computing architectures, which can
be based on a number of approaches (trapped ions, silicon quantum dots, and
topological superconductors, just to name a few). However, all of these
approaches are somewhat limited from a physics perspective: they all need to
employ electronic circuits, which leads to Ohmic heating (the waste heat that
results from electrical signals' trips through resistive semiconductor
wiring).
5 Cybersecurity Trends to Watch in 2022

Both state and national laws protecting consumer privacy are expected in 2022
by Trevor Hughes, president and CEO of the International Association of
Privacy Professionals (IAPP). “The trendlines for privacy that formed in 2021
will accelerate and will bring new risks and complexity for organizations,”
Hughes explained. “More national laws will be passed. More state laws will be
passed. More (and heftier) enforcement will occur.” The trade-off for business
is that privacy protections will be something that end users are more
concerned about. ... “Social engineering will continue to work pretty dang
well,” Stairwell’s Mike Wiacek said about 2022. “Social engineering is one of
the most difficult security issues to address because no compliance,
governance or risk-management action can address the fact that people are
imperfect and susceptible to being duped.” ... Email will be increasingly
targeted in 2022 with targeted, high-quality spear-phishing attempts, and will
require a change in defense tactics, according to Troy Gill, senior manager of
threat intelligence with Zix | App River.
6 things in cybersecurity we didn’t know last year

It’s no secret that tech companies are some of the biggest holders of user
data, and — less surprisingly — a frequent target of government data requests
that seek information for criminal investigations. But Microsoft this year
warned of the growing trend of the government attaching secrecy orders to
search warrants, gagging the company from telling its users when their data is
subject to an investigation. Microsoft said one-third of all legal orders come
with secrecy provisions, many of which are “unsupported by any meaningful
legal or factual analysis,” according to the company’s consumer security chief
Tom Burt. Microsoft said secrecy orders were endemic across the entire tech
industry. In April, the FBI launched a first-of-its-kind operation to remove
backdoors in hundreds of U.S. company email servers left behind by hackers
weeks earlier. China was ultimately blamed for the mass exploitation of
vulnerabilities in Microsoft’s Exchange email software, which the hackers used
to attack thousands of company email servers around the U.S. to steal contact
lists and mailboxes.
Building an AI-Powered Content Collaboration Platform on Azure

Critical to any model’s success is the dataset’s quality. Instead of relying
on ready-made data collections, we employ a manual process for Reflexion.ai to
replicate real-world use cases better. We also have firm guidelines in place
to ensure that the collected data is usable. This data requirement sparked the
need for a validation exercise to help weed out abnormalities detected early
in the process. This exercise helps us avoid backtracking later when the model
fails accuracy tests. Since manually validating every data point is tedious,
we explored options to automate the process. We realized Azure Machine
Learning could help. Azure Machine Learning helps us develop scripts to
automate initial dataset checks. We also benefit from the collaboration of
notebooks and datasets, making it easier for multiple developers to work
parallelly. This workflow assures us that the dataset is always in perfect
condition, allowing our developers to focus on other aspects of the operation
whenever a need for optimization arises. Data collection is an inherently
iterative process, and in turn, the datasets are constantly evolving.
Making a Simple Data Pipeline Part 4: CI/CD with GitHub Actions
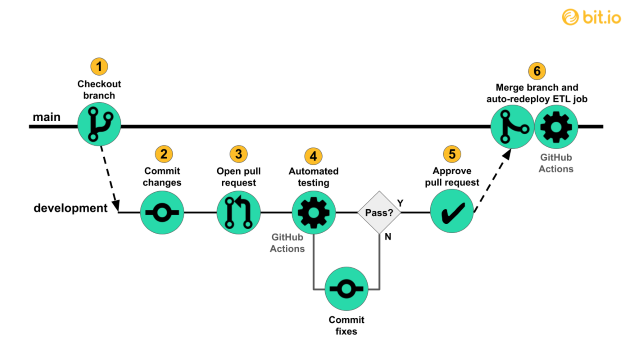
I/CD is an abbreviation for Continuous Integration/Continuous Deployment (or
Continuous Delivery). Much ink has been spilled defining the scope of each of
these terms. We will prioritize basic concepts over comprehensive coverage,
and show how we can apply those basics to our simple pipeline. Continuous
Integration (CI) refers to using automation to frequently build, test, and
merge code changes to a branch in a shared repository. The basic motivation
behind CI is pursuing faster developer iteration and deployment of changes
compared to a process with larger, infrequent integration events where many
changes, often from multiple developers, are de-conflicted and tested at the
same time. Continuous Deployment (CD) refers to using automation to frequently
redeploy a software project. The basic motivation behind CD is freeing
operations teams from executing time-consuming and error-prone manual
deployment processes while getting changes out to users quickly. For our batch
processing pipeline, deployment simply means re-running the pipeline to update
the database when changes are pushed to main.
Data will continue to move to the edge in 2022

The ultimate edge location, though, will continue to be in the phones and
laptops. Web app developers continue to leverage the power of browser-based
storage while exploring more efficient ways to distribute software. WebASM is an
emerging standard that can bring more powerful software to handsets and desktops
without complicated installation or permissioning. Computer scientists are also
working at a theoretical level by redesigning their algorithms to be distributed
to local machines. IBM, for instance, is building AI algorithms that can split
the jobs up so the data does not need to move. When they’re applied to data
collected by handsets or other IoT devices, they can learn and adapt while
synchronizing only essential data. This distributed buzzword is also more
commonly found in debates about control. While the push by some to create a
distributed web, sometimes called Web3, is driven more by political debates
about power than practical concerns about latency, the movement is in the same
general direction.
The Architecture of a Web 3.0 application
Unlike Web 2.0 applications like Medium, Web 3.0 eliminates the middle man.
There’s no centralized database that stores the application state, and there’s
no centralized web server where the backend logic resides. Instead, you can
leverage blockchain to build apps on a decentralized state machine that’s
maintained by anonymous nodes on the internet. By “state machine,” I mean a
machine that maintains some given program state and future states allowed on
that machine. Blockchains are state machines that are instantiated with some
genesis state and have very strict rules (i.e., consensus) that define how
that state can transition. Better yet, no single entity controls this
decentralized state machine — it is collectively maintained by everyone in the
network. And what about a backend server? Instead of how Medium’s backend was
controlled, in Web 3.0 you can write smart contracts that define the logic of
your applications and deploy them onto the decentralized state machine. This
means that every person who wants to build a blockchain application deploys
their code on this shared state machine.
Quote for the day:
"My philosophy of leadership is to
surround myself with good people who have ability, judgment and knowledge,
but above all, a passion for service." -- Sonny Perdue
No comments:
Post a Comment