Unstructured Data Will Be Key to Analytics in 2022

Many organizations today have a hybrid cloud environment in which the bulk of
data is stored and backed up in private data centers across multiple vendor
systems. As unstructured (file) data has grown exponentially, the cloud is being
used as a secondary or tertiary storage tier. It can be difficult to see across
the silos to manage costs, ensure performance and manage risk. As a result, IT
leaders realize that extracting value from data across clouds and on-premises
environments is a formidable challenge. Multicloud strategies work best when
organizations use different clouds for different use cases and data sets.
However, this brings about another issue: Moving data is very expensive when and
if you need to later move data from one cloud to another. A newer concept is to
pull compute toward data that lives in one place. That central place could be a
colocation center with direct links to cloud providers. Multicloud will evolve
with different strategies: sometimes compute comes to your data, sometimes the
data resides in multiple clouds.
Developing Event-Driven Microservices
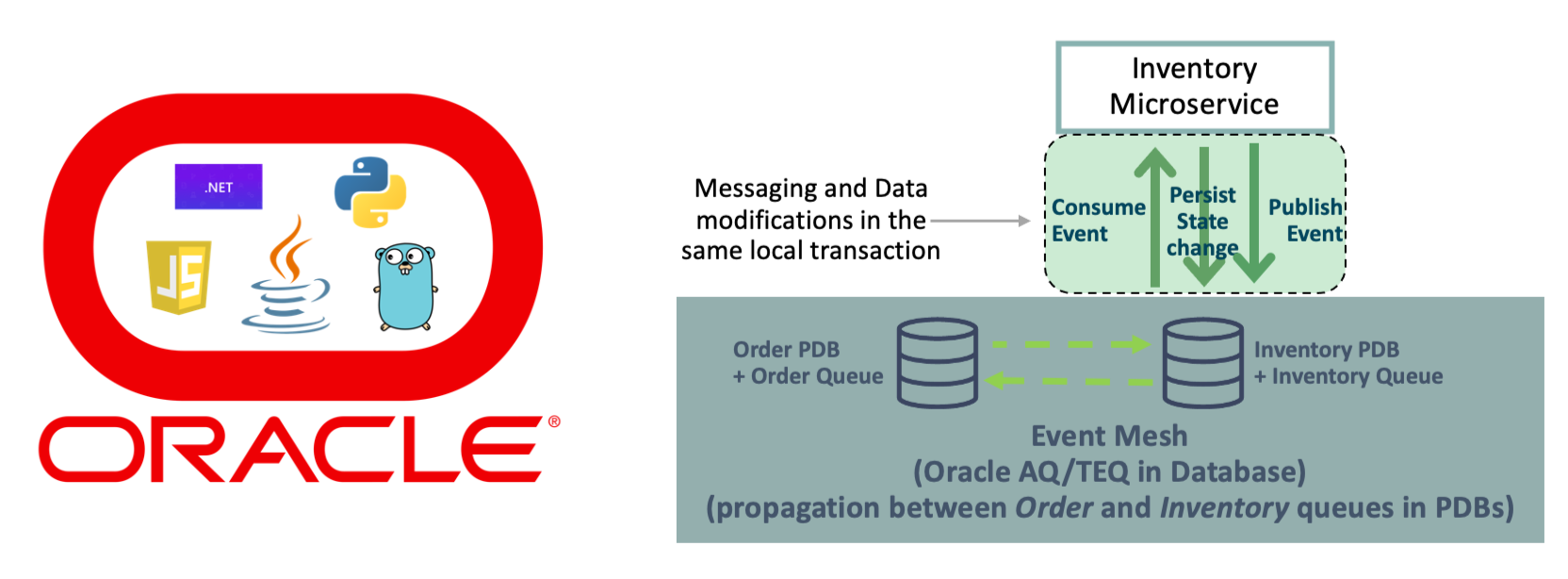
Microservices increasingly use event-driven architectures for communication and
related to this many data-driven systems are also employing an event sourcing
pattern of one form or another. This is when data changes are sent via events
that describe the data change that are received by interested services. Thus,
the data is sourced from the events, and event sourcing in general moves the
source of truth for data to the event broker. This fits nicely with the
decoupling paradigm of microservices. It is very important to notice that there
are actually two operations involved in event sourcing, the data change being
made and the communication/event of that data change. There is, therefore, a
transactional consideration and any inconsistency or failure causing a lack of
atomicity between these two operations must be accounted for. This is an area
where TEQ has an extremely significant and unique advantage as it, the
messaging/eventing system, is actually part of the database system itself and
therefore can conduct both of these operations in the same local transaction and
provide this atomicity guarantee.
Quantum computing use cases are getting real—what you need to know

Most known use cases fit into four archetypes: quantum simulation, quantum
linear algebra for AI and machine learning, quantum optimization and search,
and quantum factorization. We describe these fully in the report, as well as
outline questions leaders should consider as they evaluate potential use
cases. ... Quantum computing has the potential to revolutionize the research
and development of molecular structures in the biopharmaceuticals industry as
well as provide value in production and further down the value chain. In
R&D, for example, new drugs take an average of $2 billion and more than
ten years to reach the market after discovery. Quantum computing could make
R&D dramatically faster and more targeted and precise by making target
identification, drug design, and toxicity testing less dependent on trial and
error and therefore more efficient. A faster R&D timeline could get
products to the right patients more quickly and more efficiently—in short, it
would improve more patients’ quality of life. Production, logistics, and
supply chain could also benefit from quantum computing.
How Extended Security Posture Management Optimizes Your Security Stack

XSPM helps the security team to deal with the constant content configuration
churn and leverages telemetry to help identify the gaps in security by
generating up-to-date emerging threats feeds and providing additional test
cases emulating TTPs that attackers would use, saving DevSocOps the time
needed to develop those test cases. When running XSPM validation modules,
knowing that the tests are timely, current, and relevant enables reflecting on
the efficacy of security controls and understanding where to make investments
to ensure that the configuration, hygiene and posture are maintained through
the constant changes in the environment. By providing visibility and
maximizing relevancy, XSPM helps verify that each dollar spent benefits risk
reduction and tool efficacy through baselining and trending and automatically
generating reports containing detailed recommendations covering security
hardening and tool stack optimization; it dramatically facilitates
conversations with the board.
Edge computing keeps moving forward, but no standards yet

As powerful as this concept of seemingly unlimited computing resources may be,
however, it does raise a significant, practical question. How can developers
build applications for the edge when they don’t necessarily know what
resources will be available at the various locations in which their code will
run? Cloud computing enthusiasts may point out that a related version of this
same dilemma faced cloud developers in the past, and they developed
technologies for software abstraction that essentially relieved software
engineers of this burden. However, most cloud computing environments had a
much smaller range of potential computing resources. Edge computing
environments, on the other hand, won’t only offer more choices, but also
different options across related sites (such as all the towers in a cellular
network). The end result will likely be one of the most heterogeneous targets
for software applications that has ever existed. Companies like Intel are
working to solve some of the heterogeneity issues with software
frameworks.
The Mad Scramble To Lead The Talent Marketplace Market
While this often starts as a career planning or job matching system, early on
companies realize it’s a mentoring tool, a way to connect to development
programs, a way to promote job-sharing and gig work, and a way for hiring
managers to find great staff. In reality, this type of solution becomes “the
system for internal mobility and development,” so companies like Allstate,
NetApp, and Schneider see it as an entire system for employee growth. Other
companies, like Unilever, see it as a way to promote flexible work. These
companies use the Talent Marketplace to encourage agile, gig-work and help
people find projects or developmental assignments. Internal gig work and
cross-functional projects are a massive trend (movement toward Agile), within
a given function (IT, HR, Customer Service, Finance) it’s incredibly powerful.
And since the marketplace democratizes opportunities, companies like Seagate
see this as a diversity platform as well.
Inside the blockchain developer’s mind: Proof-of-stake blockchain consensus

The real innovation in Bitcoin (BTC) was the creation of an elegant system for
combining cryptography with economics to leverage electronic coins (now called
“cryptocurrencies”) to use incentives to solve problems that algorithms alone
cannot solve. People were forced to perform meaningless work to mine blocks,
but the security stems not from the performance of work, but the knowledge
that this work could not have been achieved without the sacrifice of capital.
Were this not the case, then there would be no economic component to the
system. The work is a verifiable proxy for sacrificed capital. Because the
network has no means of “understanding” money that is external to it, a system
needed to be implemented that converted the external incentive into something
the network can understand — hashes. The more hashes an account creates, the
more capital it must have sacrificed, and the more incentivized it is to
produce blocks on the correct fork. Since these people have already spent
their money to acquire hardware and run it to produce blocks, their
incentivizing punishment is easy because they’ve already been punished!
Why Intuitive Troubleshooting Has Stopped Working for You

With complicated and complex, I’m using specific terminology from the Cynefin
model. Cynefin (pronounced kuh-NEV-in) is a well-regarded system management
framework that categorizes different types of systems in terms of how
understandable they are. It also lays out how best to operate within those
different categories — what works in one context won’t work as well in another
— and it turns out that these operating models are extremely relevant to
engineers operating today’s production software. Broadly, Cynefin describes
four categories of system: obvious, complicated, complex, and chaotic. From
the naming, you can probably guess that this categorization ranges from
systems that are more predictable and understandable, to those that are less —
where predictability is defined by how clear the relationship is between cause
and effect. Obvious systems are the most predictable; the relationship between
cause and effect is clear to anyone looking at the system. Complicated systems
have a cause-and-effect relationship that is well understood, but only to
those with system expertise.
2022 will see a rise in application security orchestration and correlation (ASOC)

For organisations that build software, 2022 will be the year of invisible
AppSec. When AppSec tools are run automatically, and when results are
integrated with existing processes and issue trackers, developers can be
fixing security weaknesses as part of their normal workflows. There is no
reason for developers to go to separate systems to “do security,” and no
reason they should be scrolling through thousand-page PDF reports from the
security team, trying to figure out what needs to be done. When security
testing is automated and integrated into a secure development process, it
becomes a seamless part of application development. At the same time,
organisations are coming to recognise that AppSec is a critical part of risk
management, and that a properly implemented AppSec programme results in
business benefits. Good AppSec equals fewer software vulnerabilities, which
equals less risk of catastrophe or embarrassing publicity, but also results in
fewer support cases, fewer emergency updates, higher productivity, and happier
customers. But how can organisations turn this knowledge into power?
Why Sustainability Is the Next Priority for Enterprise Software

To meet market and consumer demands, every enterprise will need to evolve
their sustainability programs into being just as accurate and rigorous as that
of financial accounting. Similarly to the The Sarbanes–Oxley Act of 2002
mandates practices in financial record keeping and reporting for corporations
in the US, we can expect laws and consumer expectations around sustainability
impacts to follow suit. In the same way that SaaS platforms, cloud computing,
and digital transformation have changed how enterprises sell, hire, and
invest, we’re on the cusp of similar changes within sustainability. For
example, as recently as the mid-2000s, interviewing for a new corporate job
meant printing out resumes, distributing paper benefits pamphlets, and signing
forms that had been Xeroxed a half-dozen times. Today, numerous human
resources software companies offer streamlined digital solutions for tracking
candidates, onboarding new colleagues, and managing benefits. When large
organizations are faced with a high volume of data in any area of their
business, digitization is the inevitable solution.
Quote for the day:
"The level of morale is a good
barometer of how each of your people is experiencing your leadership." --
Danny Cox
No comments:
Post a Comment