Data Science Collides with Traditional Math in the Golden State

San Francisco’s approach is the model for a new math framework proposed by the
California Department of Education that has been adopted for K-12 education
statewide. Like the San Francisco model, the state framework seeks to alter the
traditional pathway that has guided college-bound students for generations,
including by encouraging middle schools to drop Algebra (the decision to
implement the recommendations is made by individual school districts). This new
framework has been received with some controversy. Yesterday, a group of
university professors wrote an open letter on K-12 mathematics, which
specifically cites the new California Mathematics Framework. “We fully agree
that mathematics education ‘should not be a gatekeeper but a launchpad,’” the
professors write. “However, we are deeply concerned about the unintended
consequences of recent well-intentioned approaches to reform mathematics,
particularly the California Mathematics Framework.” Frameworks like the CMF aim
to “reduce achievement gaps by limiting the availability of advanced
mathematical courses to middle schoolers and beginning high schoolers,” the
professors continued.
Promoting trust in data through multistakeholder data governance

A lack of transparency and openness of the proceedings, or barriers to
participation, such as prohibitive membership fees, will impede participation
and reduce trust in the process. These challenges are particularly felt by
participants from low- and middle-income countries (LICs and LMICs), whose
financial resources and technical capacity are usually not on par with those of
higher-income countries. These challenges affect both the participatory nature
of the process itself and the inclusiveness and quality of the outcome. Even
where a level playing field exists, the effectiveness of the process can be
limited if decision makers do not incorporate input from other stakeholders.
Notwithstanding the challenges, multistakeholder data governance is an essential
component of the “trust framework” that strengthens the social contract for
data. In practice, this will require supporting the development of diverse
forums—formal or informal, digital or analog—to foster engagement on key data
governance policies, rules, and standards, and the allocation of funds and
technical assistance by governments and nongovernmental actors to support the
effective participation of LMICs and underrepresented groups.
A Plan for Developing a Working Data Strategy Scorecard

Strategy is an evolving process, with regular adjustments expected as progress
is measured against desired goals over longer timeframes. “There’s always an
element of uncertainty about the future,” Levy said, “so strategy is more about
a set of options or strategic choices, rather than a fixed plan.” It’s common
for companies to re-evaluate and adjust accordingly as business goals evolve and
systems or tools change. Before building a strategy, people often assume that
they must have vision statements or mission statements, a SWOT analysis, or
goals and objectives. These are good to have, he said, but in most instances,
they are only available after the strategy analysis is completed. “When people
establish their Data Strategies, it’s typically to address limitations they have
and the goals that they want. Your strategy, once established, should be able to
answer these questions.” But again, Levy said, it’s after the strategy is
developed, not prior. Although it can be difficult to understand the purpose of
a Data Strategy, he said, it’s critically important to clearly identify goals
and know how to communicate them to the intended audience.
“Less popular” JavaScript Design Patterns.
As software engineers, we strive to write maintainable, reusable, and eloquent
code that might live forever in large applications. The code we create must
solve real problems. We are certainly not trying to create redundant,
unnecessary, or “just for fun” code. At the same time, we frequently face
problems that already have well-known solutions that have been defined and
discussed by the Global community or even by our own teams millions of times.
Those solutions to such problems are called “Design patterns”. There are a
number of existing design patterns in software design, some of them are used
more often, some of them less frequently. Examples of popular JavaScript design
patterns include factory, singleton, strategy, decorator, and observer patterns.
In this article, we’re not going to cover all of the design patterns in
JavaScript. Instead, let’s consider some of the less well-known but potentially
useful JS patterns such as command, builder, and special case, as well as real
examples from our production experience.
Software Engineering | Coupling and Cohesion
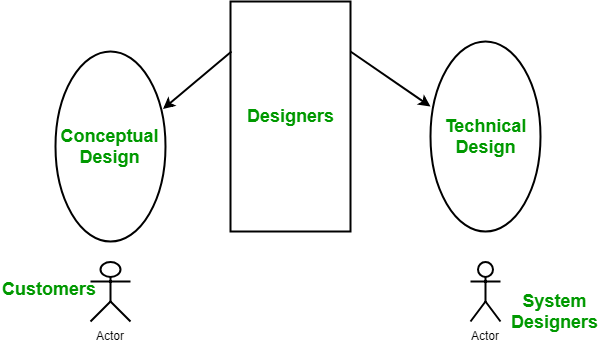
The purpose of Design phase in the Software Development Life Cycle is to produce
a solution to a problem given in the SRS(Software Requirement Specification)
document. The output of the design phase is Software Design Document (SDD).
Basically, design is a two-part iterative process. First part is Conceptual
Design that tells the customer what the system will do. Second is Technical
Design that allows the system builders to understand the actual hardware and
software needed to solve customer’s problem. ... If the dependency between
the modules is based on the fact that they communicate by passing only data,
then the modules are said to be data coupled. In data coupling, the components
are independent of each other and communicate through data. Module
communications don’t contain tramp data. Example-customer billing
system. In stamp coupling, the complete data structure is passed from one
module to another module. Therefore, it involves tramp data. It may be necessary
due to efficiency factors- this choice was made by the insightful designer, not
a lazy programmer.
5 Takeaways from SmartBear’s State of Software Quality Report

As API adoption and growth continues, standardization (52%) continues to rank as
the top challenge organizations hope to solve soon as they look to scale.
Without standardization, APIs become bespoke and developer productivity
declines. Costs and time-to-market increase to accommodate changes, the general
quality of the consumer experience wanes, and it leads to a lower value
proposition and decreased reach. Additionally, the consumer persona in the API
landscape is rightfully getting more attention. Consumer expectations have never
been higher. API consumers demand standardized offerings from providers and will
look elsewhere if expectations around developer experience isn’t met, which is
especially true in financial services. Security (40%) has thankfully crept up in
the rankings to number two this year. APIs increasingly connect our most
sensitive data, so ensuring your APIs are secure before, during, and after
production is imperative. Applying thoughtful standardization and governance
guiderails are required for teams to deliver good quality and secure APIs
consistently.
From DeFi year to decade: Is mass adoption here? Experts Answer, Part 1

More scaling solutions will become essential to the mass adoption of DeFi
products and services. We are seeing that most DeFi applications go live on
multiple chains. While that makes them cheaper to use, it adds more complexities
for those who are trying to learn and understand how they work. Thus, to start
the second phase of DeFi mass adoption, we need solutions that simplify
onboarding and use DApps that are spread across different chains and scaling
solutions. The endgame is that all the cross-chain actions will be in the
background, handled by infra services such as Biconomy or the DApp themselves,
so the user doesn’t need to deal with it themselves. ... Going into 2022 and
equipped with the right layer-one networks, we’re aiming for mass adoption. To
achieve that, we need to eradicate the entry barriers for buying and selling
crypto through regulated fiat bridges (such as banks), overhaul the user
experience, reduce fees, and provide the right guide rails so everyone can
easily and safely participate in the decentralized economy. DeFi is legitimizing
crypto and decentralized economies. Traditional financial institutions are
already starting to participate. In 2022, we will only see an uptick in usage
and adoption.
Serious Security: OpenSSL fixes “error conflation” bugs – how mixing up mistakes can lead to trouble

The good news is that the OpenSSL 1.1.1m release notes don’t list any
CVE-numbered bugs, suggesting that although this update is both desirable and
important, you probably don’t need to consider it critical just yet. But those
of you who have already moved forwards to OpenSSL 3 – and, like your tax return,
it’s ultimately inevitable, and somehow a lot easier if you start sooner –
should note that OpenSSL 3.0.1 patches a security risk dubbed CVE-2021-4044. ...
In theory, a precisely written application ought not to be dangerously
vulnerable to this bug, which is caused by what we referred to in the headline
as error conflation, which is really just a fancy way of saying, “We gave you
the wrong result.” Simply put, some internal errors in OpenSSL – a genuine but
unlikely error, for example, such as running out of memory, or a flaw elsewhere
in OpenSSL that provokes an error where there wasn’t one – don’t get reported
correctly. Instead of percolating back to your application precisely, these
errors get “remapped” as they are passed back up the call chain in OpenSSL,
where they ultimately show up as a completely different sort of error.
Digital Asset Management – what is it, and why does my organisation need it?

DAM technology is more than a repository, of course. Picture it as a framework
that holds a company’s assets, on top of which sits a powerful AI engine capable
of learning the connections between disparate data sets and presenting them to
users in ways that make the data more useful and functional. Advanced DAM
platforms can scale up to storing more than ten billion objects – all of which
become tangible assets, connected by the in-built AI -- at the same time. This
has the capacity to result in a huge rise in efficiency around the use of assets
and objects. Take, for example, a busy modern media marketing agency. In the
digital world, they are faced with a massive expansion of content at the same
time as release windows are shrinking – coupled with the issue of increasingly
complex content creation and delivery ecosystems. A DAM platform can manage
those huge volumes of assets - each with their complex metadata - at speeds and
scale that would simply break a legacy system. Another compelling example of DAM
in action includes a large U.S.-based film and TV company, which uses it for
licencing management.
Impact of Data Quality on Big Data Management

A starting point for measuring Data Quality can be the qualities of big
data—volume, velocity, variety, veracity—supplemented with a fifth criterion of
value, made up the baseline performance benchmarks. Interestingly, these
baseline benchmarks actually contribute to the complexity of big data: variety
such as structured, unstructured, or semi-structured increases the possibility
of poor data; data channels such as streaming devices with high-volume and
high-velocity data enhances the chances of corrupt data—and thus no single
quality metric can work on such voluminous and multi-type data. The easy
availability of data today is both a boon and a barrier to Enterprise Data
Management. On one hand, big data promises advanced analytics with actionable
outcomes; on the other hand, data integrity and security are seriously
threatened. The Data Quality program is an important step in implementing a
practical DG framework as this single factor controls the outcomes of business
analytics and decision-making. ... Another primary challenge that big data
brings to Data Quality Management is ensuring data accuracy, without which,
insights would be inaccurate.
Quote for the day:
"There is no "one" way to be a perfect
leader, but there are a million ways to be a good one." --
Mark W. Boyer
No comments:
Post a Comment