Seeing, doing, and imagining

Association, which Pearl, a Turing Award winner, identifies as the first of
three steps on his ladder of causation, won’t help executives answer many of the
questions they need to ask when formulating corporate strategy, making
investment decisions, or setting prices. To answer questions such as, “What will
raising prices by 10 percent do to revenues?” you need to start climbing Pearl’s
ladder. Intervention is the second step on the ladder. “Intervention ranks
higher than association because it involves not just seeing but changing what
is,” Pearl writes. That’s why companies are running scads of randomized
controlled experiments these days. They are changing things on a small
scale to figure out what effects an action will produce on a large scale.
Real-world experiments aren’t a necessity — you can get a machine to figure out
the effects of an intervention without actually changing anything in the real
world. ... The third and highest rung on Pearl’s causation ladder is
counterfactuals. Pursuing causation at this level means determining what would
have happened if your company had done something in the past. For instance, what
would revenues be today if you had cut prices by 10 percent a year ago?
The time is right for passwordless authentication

People just can’t be trusted to set reliable passwords, to change them
frequently, to make sure they are strong, and to keep them secure. Forcing
password change simply creates bad feeling and password reuse. Two-factor
authentication is little better as a solution. It still relies on a password,
often with a second PIN disclosed to a mobile phone. I’ve heard that some
businesses and schools are trying to implement two-factor solutions, but users
do not feel comfortable disclosing a private mobile number as a means to
authenticate and log on, so the business needs to provide a second phone to the
user, which is expensive and gives the user the task of carrying two phones
around. Asking people to do more to achieve a goal than they were doing before
is a sure-fire way to disgruntle them. Passwordless authentication removes all
of these problems. It gives end-users less to remember, and less to think about.
Login is faster, easier, and in comparison to tapping in passwords, waiting for
a text to come through and tapping in a PIN, it is seamless and painless.
AI can stem the tide of increasing fraud and money laundering

Rather than having developers rewrite systems each time legislation changes, the
new breed of AI-enabled RegTech can ‘learn’, interpret and comply with
applicable laws, including KYC and AML. No system will ever be perfect – there
is still the need for human oversight and there is still the possibility for
criminals to find loopholes. These criminals are increasingly using technology
to exploit weak links in regulatory frameworks, but as fast as they can move to
deploy new schemes, machine learning systems will be able to counter them.
AI-based technology has moved beyond an experimental phase and is ready to
become a competitive differentiator in financial services, but there is still a
level of reticence on the part of the industry when it comes to what many
perceive as handing over compliance to machines. Traditionally, banks and other
companies that handle monetary transactions have had to be conservative in
nature. Data tends to be housed in silos, often on legacy systems, rather than
having it be visible across the whole organisation, which allows AI-based
systems to get the greatest value.
Root Cause Analysis for Data Engineers
In theory, root causing sounds as easy as running a few SQL queries to segment
the data, but in practice, this process can be quite challenging. Incidents can
manifest in non-obvious ways across an entire pipeline and impact multiple,
sometimes hundreds, of tables. For instance, one common cause of data downtime
is freshness — i.e. when data is unusually out-of-date. Such an incident can be
a result of any number of causes, including a job stuck in a queue, a time out,
a partner that did not deliver its dataset timely, an error, or an accidental
scheduling change that removed jobs from your DAG. In my experience, I’ve found
that most data problems can be attributed to one or more of these events: An
unexpected change in the data feeding into the job, pipeline or system; A
change in the logic (ETL, SQL, Spark jobs, etc.) transforming the data; An
operational issue, such as runtime errors, permission issues, infrastructure
failures, schedule changes, etc. Quickly pinpointing the issue at hand requires
not just the proper tooling, but a holistic approach that takes into
consideration how and why each of these three sources could break.
Gamifying machine learning for stronger security and AI models
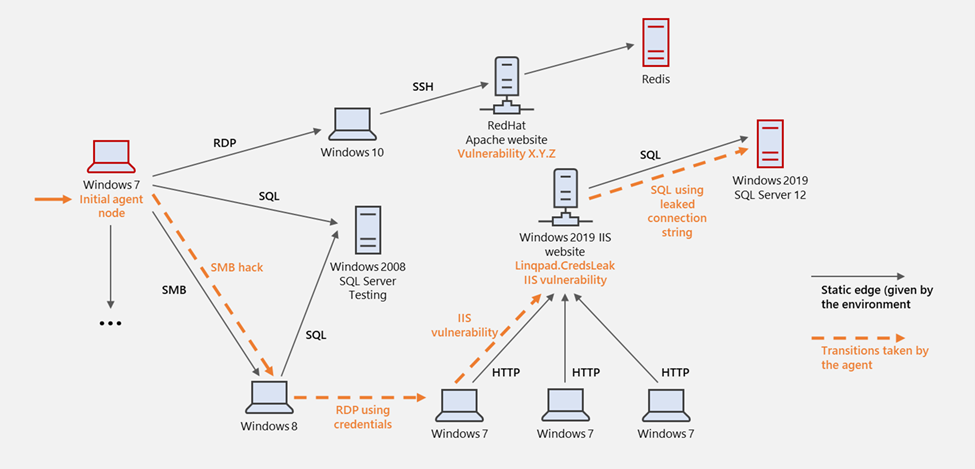
Computer and network systems, of course, are significantly more complex than
video games. While a video game typically has a handful of permitted actions at
a time, there is a vast array of actions available when interacting with a
computer and network system. For instance, the state of the network system can
be gigantic and not readily and reliably retrievable, as opposed to the finite
list of positions on a board game. Even with these challenges, however, OpenAI
Gym provided a good framework for our research, leading to the development of
CyberBattleSim. CyberBattleSim focuses on threat modeling the post-breach
lateral movement stage of a cyberattack. The environment consists of a network
of computer nodes. It is parameterized by a fixed network topology and a set of
predefined vulnerabilities that an agent can exploit to laterally move through
the network. The simulated attacker’s goal is to take ownership of some portion
of the network by exploiting these planted vulnerabilities. While the simulated
attacker moves through the network, a defender agent watches the network
activity to detect the presence of the attacker and contain the attack.
Which Industries Would Benefit the Most From Agile Innovation
It may seem surprising that the financial sector is struggling to reach its
innovation goals. However, Financier Worldwide found in 2015 that 90% of leaders
admitted there was a lack of focus on radical innovation. Several years later,
Deloitte’s report ‘Regulatory Trends Outlook for 2018’, claimed the financial
industry was being hindered by a ‘legacy infrastructure’ that would take years
to transform. For example, a focus on traditional product development means that
customer and end-user feedback can’t be incorporated into the development
process. Agile methods could rectify this by implementing new collaborative and
customer-focused processes to product development. Teams could use a centralised
system for the development of prototypes, which would be shared internally in a
project’s initial phases. They can then conduct beta testing with a select group
of end-users, with feedback incorporated iteratively into the final stages.
Another issue is how increasingly stringent regulations may be inhibiting
innovation. Financial firms are set to spend an estimated 10% of their revenue
on compliance costs by 2022.
Why machine learning struggles with causality

Why do machine learning models fail at generalizing beyond their narrow domains
and training data? “Machine learning often disregards information that animals
use heavily: interventions in the world, domain shifts, temporal structure — by
and large, we consider these factors a nuisance and try to engineer them away,”
write the authors of the causal representation learning paper. “In accordance
with this, the majority of current successes of machine learning boil down to
large scale pattern recognition on suitably collected independent and
identically distributed (i.i.d.) data.” i.i.d. is a term often used in machine
learning. It supposes that random observations in a problem space are not
dependent on each other and have a constant probability of occurring. The
simplest example of i.i.d. is flipping a coin or tossing a die. The result of
each new flip or toss is independent of previous ones, and the probability of
each outcome remains constant. When it comes to more complicated areas such as
computer vision, machine learning engineers try to turn the problem into an
i.i.d. domain by training the model on very large corpora of examples.
WhoIAM: Enabling inclusive security through identity protection and fraud prevention
IT decision-makers are usually quite tuned in to the challenges around the cost
of acquiring new customers, keeping user data secure, and managing
infrastructure costs. However, large groups of users are often left behind
because of an inherent set of biases in identity security. For instance,
authenticator apps, while secure, require a reasonably tech-savvy user.
On-device biometrics such as a fingerprint sensor or retina scan create a
dependency on newer, more powerful hardware. SMS-based MFA, while more readily
available, is expensive both to our client and their end customers and is
considered less secure than other authentication factors. Even onscreen identity
verification challenges tend to be biased towards English speakers who don’t
have visual impairments. Asking a non-native speaker to solve a CAPTCHA that
identifies all “sidewalks” or “stop lights” often does not translate well, and
CAPTCHAs are historically a poor option for the visually impaired. While these
are important factors to solve for, consumer brands still have to strike the
right balance between security, cost, and usability.
Five ways to control spiralling IT costs after disruption

With an ongoing need to optimise costs, many businesses are suddenly realising
they have lost control of their SaaS spend. It’s now common for large businesses
to have SaaS applications managed outside the IT department, multiple contracts
with the same vendor, or even multiple vendors providing the same service to the
business. To combat this, first you need to draw on technology solutions that
will give you full visibility of all SaaS application licences and services
within the business. Then you need to rationalise them. With SaaS sprawl likely
to be coming from outside IT, one way of consolidating this spend is to use
tools that leverage single sign-on (SSO) data stored within an organisation’s
network to identify hidden licences. Once you see the full picture, you can
assess where best to cut back and which licences are redundant. Following on
from this point, you need to introduce more accountability for SaaS usage and
spend together with strict procurement processes and user chargeback. That’s
because services like file storage and collaboration can be too easy to sign up
for without the knowledge of IT.
Teknion CIO on the importance of fostering multi-generational talent
Technology has changed rapidly over the years, and each generation has come into
technology at a different time. Their perspectives, therefore, are very
different when it comes to technology, because it’s viewed from the moment they
began leveraging it, as opposed to waiting for the latest technological
innovation. It’s important to cultivate a multi-generational workforce in
technology, especially, because everyone has different perspectives on the
opportunities, challenges and shortfalls of tech. It’s a huge opportunity for
every organisation to look at these perspectives and use technology in a better
way because of that. ... As a CIO, my team and I have to provide the technology
that keeps the company running, for our customers as well as the employees that
work here every day. Having a perspective of a multi-generational workforce, not
only within the technology department, but the wider business, allows us to
enable digital transformation programs with more success. At the end of the day,
we have to provide the technology, applications and tools that will help people
to do their job better and not forcing them to work in a certain way.
Quote for the day:
"Failing organizations are usually
over-managed and under-led." -- Warren G. Bennis
No comments:
Post a Comment