The Rise of Cognitive AI

There is a strong push for AI to reach into the realm of human-like
understanding. Leaning on the paradigm defined by Daniel Kahneman in his book,
Thinking, Fast and Slow, Yoshua Bengio equates the capabilities of contemporary
DL to what he characterizes as “System 1” — intuitive, fast, unconscious,
habitual, and largely resolved. In contrast, he stipulates that the next
challenge for AI systems lies in implementing the capabilities of “System 2” —
slow, logical, sequential, conscious, and algorithmic, such as the capabilities
needed in planning and reasoning. In a similar fashion, Francois Chollet
describes an emergent new phase in the progression of AI capabilities based on
broad generalization (“Flexible AI”), capable of adaptation to unknown unknowns
within a broad domain. Both these characterizations align with DARPA’s Third
Wave of AI, characterized by contextual adaptation, abstraction, reasoning, and
explainability, with systems constructing contextual explanatory models for
classes of real-world phenomena. These competencies cannot be addressed just by
playing back past experiences. One possible path to achieve these competencies
is through the integration of DL with symbolic reasoning and deep knowledge.
Singapore puts budget focus on transformation, innovation

Plans are also underway to enhance the Open Innovation Platform with new
features to link up companies and government agencies with relevant technology
providers to resolve their business challenges. A cloud-based digital bench, for
instance, would help facilitate virtual prototyping and testing, Heng said. The
Open Innovation Platform also offers co-funding support for prototyping and
deployment, he added. The Building and Construction Authority, for example, was
matched with three technology providers -- TraceSafe, TagBox, and Nervotec -- to
develop tools to enable the safe reopening of worksites. These include real-time
systems that have enabled construction site owners to conduct COVID-19 contact
tracing and health monitoring of their employees. Enhancements would alsobe made
for the Global Innovation Alliance, which was introduced in 2017 to facilitate
cross-border partnerships between Singapore and global innovation hubs. Since
its launch, more than 650 students and 780 Singapore businesses had participated
in innovation launchpads overseas, of which 40% were in Southeast Asia,
according to Heng.
Machine learning security vulnerabilities are a growing threat to the web, report highlights

Most machine learning algorithms require large sets of labeled data to train
models. In many cases, instead of going through the effort of creating their own
datasets, machine learning developers search and download datasets published on
GitHub, Kaggle, or other web platforms. Eugene Neelou, co-founder and CTO of
Adversa, warned about potential vulnerabilities in these datasets that can lead
to data poisoning attacks. “Poisoning data with maliciously crafted data samples
may make AI models learn those data entries during training, thus learning
malicious triggers,” Neelou told The Daily Swig. “The model will behave as
intended in normal conditions, but malicious actors may call those hidden
triggers during attacks.” Neelou also warned about trojan attacks, where
adversaries distribute contaminated models on web platforms. “Instead of
poisoning data, attackers have control over the AI model internal parameters,”
Neelou said. “They could train/customize and distribute their infected models
via GitHub or model platforms/marketplaces.”
Demystifying the Transition to Microservices
The very first step you should be taking is to embrace container technology. The
biggest difference between a service-oriented architecture and a
microservice-oriented architecture is that in the second one, the deployment is
so complex, there are so many pieces with independent lifecycles, and each piece
needs to have some custom configuration that it can no longer be managed
manually. In a service-oriented architecture, with a handful of monolithic
applications, the infrastructure team can still treat each of them as a separate
application and manage them individually in terms of the release process,
monitoring, health check, configuration, etc. With microservices, this is not
possible with a reasonable cost. There will eventually be hundreds of different
'applications,' each of them with its own release cycle, health check,
configuration, etc., so their lifecycle has to be managed automatically. There
may be other technologies to do so, but microservices have become almost a
synonym of containers. Not only Docker containers manually started, but you will
also need an orchestrator. Kubernetes or Docker Swarm are the most popular
ones.
Ransomware: don’t expect a full recovery, however much you pay

Remember also that an additional “promise” you are paying for in many
contemporary ransomware attacks is that the criminals will permanently and
irrevocably delete any and all of the files they stole from your network while
the attack was underway. You’re not only paying for a positive, namely that the
crooks will restore your files, but also for a negative, namely that the crooks
won’t leak them to anyone else. And unlike the “how much did you get back”
figure, which can be measured objectively simply by running the decryption
program offline and seeing which files get recovered, you have absolutely no way
of measuring how properly your already-stolen data has been deleted, if indeed
the criminals have deleted it at all. Indeed, many ransomware gangs handle the
data stealing side of their attacks by running a series of upload scripts that
copy your precious files to an online file-locker service, using an account that
they created for the purpose. Even if they insist that they deleted the account
after receiving your money, how can you ever tell who else acquired the password
to that file locker account while your files were up there?
Linux Kernel Bug Opens Door to Wider Cyberattacks

Proc is a special, pseudo-filesystem in Unix-like operating systems that is used
for dynamically accessing process data held in the kernel. It presents
information about processes and other system information in a hierarchical
file-like structure. For instance, it contains /proc/[pid] subdirectories, each
of which contains files and subdirectories exposing information about specific
processes, readable by using the corresponding process ID. In the case of the
“syscall” file, it’s a legitimate Linux operating system file that contains logs
of system calls used by the kernel. An attacker could exploit the vulnerability
by reading /proc/<pid>/syscall. “We can see the output on any given Linux
system whose kernel was configured with CONFIG_HAVE_ARCH_TRACEHOOK,” according
to Cisco’s bug report, publicly disclosed on Tuesday.. “This file exposes the
system call number and argument registers for the system call currently being
executed by the process, followed by the values of the stack pointer and program
counter registers,” explained the firm. “The values of all six argument
registers are exposed, although most system call use fewer registers.”
Process Mining – A New Stream Of Data Science Empowering Businesses
It is needless to emphasise that Data is the new Oil, as Data has shown us time
on time that, without it, businesses cannot run now. We need to embrace not just
the importance but sheer need of Data these days. Every business runs the onset
of processes designed and defined to make everything function smoothly, which is
achieved through – Business Processes Management. Each Business Process has
three main pillars – Business Steps, Goals and Stakeholders, where series of
Steps are performed by certain Stakeholders to achieve a concrete goal. And, as
we move into the future where the entire businesses are driven by Data Value
Chain which supports the Decision Systems, we cannot ignore the usefulness of
Data Science combined with Business Process Management. And this new stream of
data science is called Process Mining. As quoted by Celonis, a world-leading
Process Mining Platform provider, that; “Process mining is an analytical
discipline for discovering, monitoring, and improving processes as they actually
are (not as you think they might be), by extracting knowledge from event logs
readily available in today’s information systems.
Alexandria in Microsoft Viva Topics: from big data to big knowledge
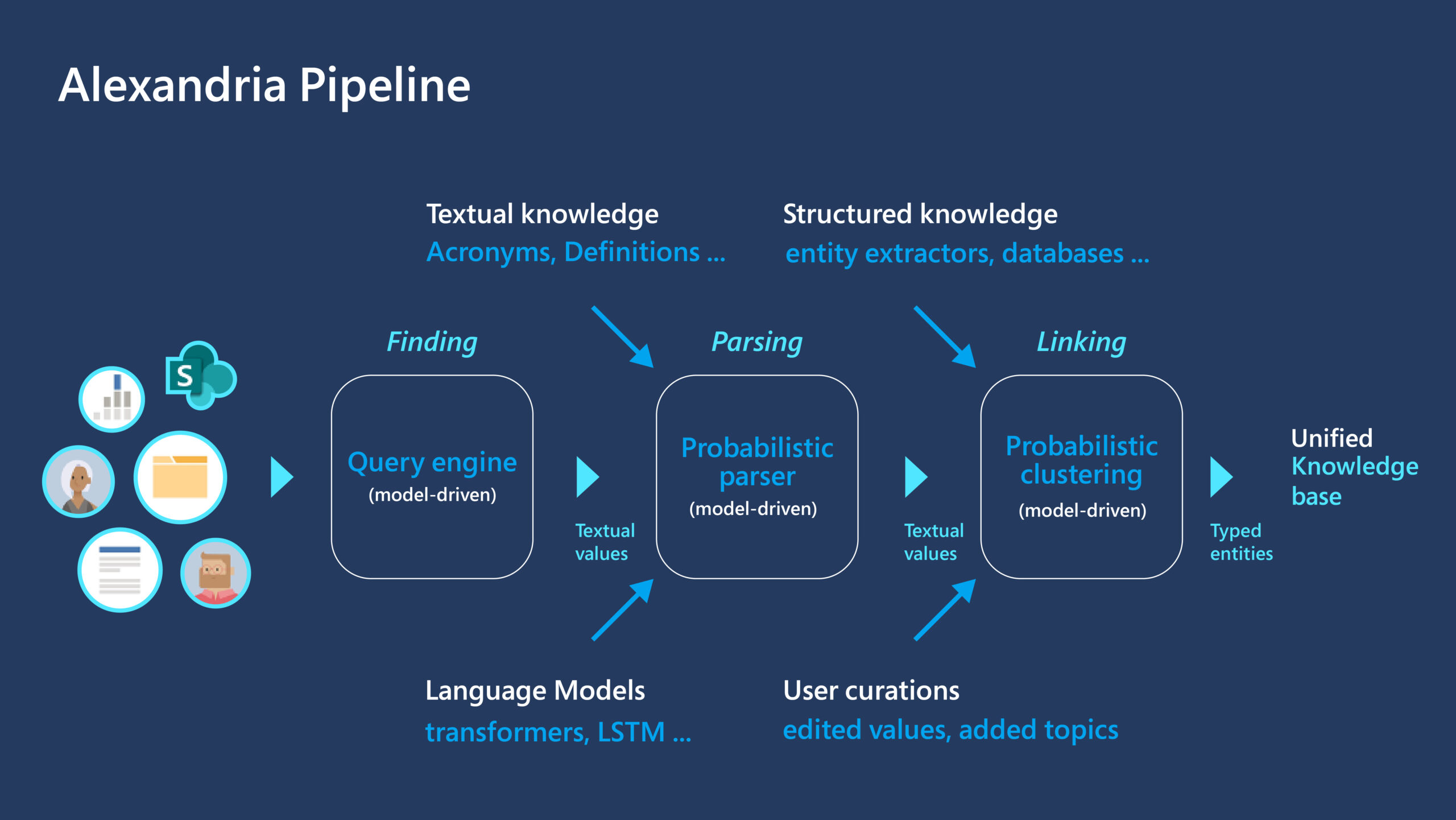
Project Alexandria is a research project within Microsoft Research Cambridge
dedicated to discovering entities, or topics of information, and their
associated properties from unstructured documents. This research lab has studied
knowledge mining research for over a decade, using the probabilistic programming
framework Infer.NET. Project Alexandria was established seven years ago to build
on Infer.NET and retrieve facts, schemas, and entities from unstructured data
sources while adhering to Microsoft’s robust privacy standards. The goal of the
project is to construct a full knowledge base from a set of documents, entirely
automatically. The Alexandria research team is uniquely positioned to make
direct contributions to new Microsoft products. Alexandria technology plays a
central role in the recently announced Microsoft Viva Topics, an AI product that
automatically organizes large amounts of content and expertise, making it easier
for people to find information and act on it. Specifically, the Alexandria team
is responsible for identifying topics and rich metadata, and combining other
innovative Microsoft knowledge mining technologies to enhance the end user
experience.
How Vodafone Greece Built 80 Java Microservices in Quarkus

The company now has 80 Quarkus microservices running in production with another
50-60 Spring microservices remaining in maintenance mode and awaiting a business
motive to update. Vodafone Greece’s success wasn’t just because of Sotiriou’s
technology choices — he also cited organizational transitions the company made
to encourage collaboration. “There is also a very human aspect in this. It was a
risk, and we knew it was a risk. There was a lot of trust required for the team,
and such a big amount of trust percolated into organizing a small team around
the infrastructure that would later become the shared libraries or common
libraries. When we decided to do the migration, the most important thing was not
to break the business continuity. The second most important thing was that if we
wanted to be efficient long term, we’d have to invest in development and
research. We wouldn’t be able to do that if we didn’t follow a code to invest
part of our time into expanding our server infrastructure,” said Sotiriou. That
was extra important for a team that scaled from two to 40 in just under three
years.
The next big thing in cloud computing? Shh… It’s confidential
The confidential cloud employs these technologies to establish a secure and
impenetrable cryptographic perimeter that seamlessly extends from a hardware
root of trust to protect data in use, at rest, and in motion. Unlike the
traditional layered security approaches that place barriers between data and bad
actors or standalone encryption for storage or communication, the confidential
cloud delivers strong data protection that is inseparable from the data itself.
This in turn eliminates the need for traditional perimeter security layers,
while putting data owners in exclusive control wherever their data is stored,
transmitted, or used. The resulting confidential cloud is similar in concept to
network micro-segmentation and resource virtualization. But instead of isolating
and controlling only network communications, the confidential cloud extends data
encryption and resource isolation across all of the fundamental elements of IT,
compute, storage, and communications. The confidential cloud brings together
everything needed to confidentially run any workload in a trusted environment
isolated from CloudOps insiders, malicious software, or would-be attackers.
Quote for the day:
"Lead, follow, or get out of the way."
-- Laurence J. Peter
No comments:
Post a Comment