Compositional AI: The Future of Enterprise AI
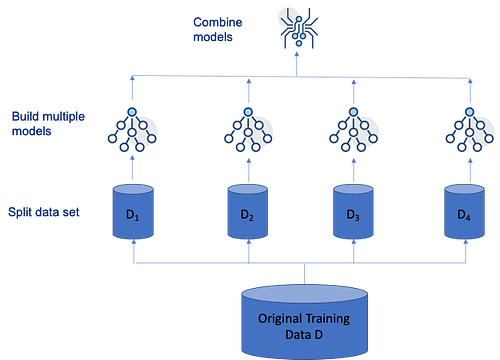
Compositionality refers to the ability to form new (composite) services by
combining the capabilities of existing (component) services. The existing
services may themselves be composite, leading to a hierarchical composition.
The concept is not new, and has been studied previously in different contexts;
most notably, Web Services Composition and Secure Composition of Security
Protocols. Web Services follow the Service Oriented Computing (SOC) approach
of wrapping a business functionality in a self-contained Service. There are
mainly two approaches to composing a service: dynamic and static. In the
dynamic approach, given a complex user request, the system comes up with a
plan to fulfill the request depending on the capabilities of available Web
services at run-time. In the static approach, given a set of Web services,
composite services are defined manually at design-time combining their
capabilities. ... In the very primitive world of supervised learning, an AI
Service consists of data used to train a model, which is then exposed as an
API. There is of course an alternate deployment pipeline, where a trained
model can be deployed on an edge device to be executed in an offline
fashion.
Four common pitfalls of HyperLedger implementation

One of the main goals of distributed ledger technology (DLT), used by
HyperLedger, is decentralization. The nodes (servers) of the network should be
spread among all organizations in the consortium and they should not depend on
the third party providers. However, we have seen implementations where the
whole infrastructure is maintained by one organization or where it is spread
among the organizations but all of them host their nodes provided by the same
cloud vendor (e.g. AWS). With centralized infrastructure comes the threat that
one organization or external provider could easily turn off the system and
thus break the principal goal of DLT. ... One of the extremes in defining
permissions in the DLT network, contrary to limiting the access of an
organization, is privileging one of the organizations in such a way that it
can make any changes to the distributed ledger. As such configuration does not
have to introduce a vulnerability, it is against blockchain rules. We have met
different implementations with this issue that all allowed one organization
can freely modify the contents. The channel endorsement policy required the
signature only from one organization.
ETL vs. Data Preparation
ETL relies on a predetermined set of rules and workflows, she said. Potential
issues, such as misspellings or extra characters, must be anticipated
beforehand so rules for how to deal with those issues can be built into the
end-to-end workflow. Conversely, a data prep tool using built-in algorithms is
capable of discovery and investigation of the data as it proceeds through the
workflow. “For example, algorithms based on machine learning or natural
language processing can recognize things that are spelled differently but are
really the same.” She gave the example of a city called “St. Louis”, and how
it could be entered in multiple ways, or there may be several cities with the
same name spelled differently. In an ETL workflow, rules for encountering each
particular variation must be programmed ahead of time, and variations not
programmed are skipped. A data prep tool can find spelling differences without
help, so that the user does not have to anticipate every possible variation.
The tool can prompt for a decision on each different variation on the name of
this city, providing an opportunity to improve the data before it’s used, she
said.
The coming opportunity in consumer lending

The second major step is to build the decision engine. In this area, new
entrants will have a large advantage over existing lenders with legacy
software that they do not want to alter. The new decision engine can largely
be built using advanced analytics, machine learning, and other tools that
capitalize on speed and agility. By using machine learning, the new-entrant
lenders will be able to automate as much as 95 percent of underwriting
processes while also making more accurate credit decisions. Similarly,
real-time machine-learning solutions can improve pricing and limit setting and
help firms monitor existing customers and credit lines through smarter
early-warning systems. Lenders can also use straight-through processing to
generate faster transactions and a better customer experience. The design of
the decision engine can be modular for maximum flexibility. That will allow
lenders to retain control of strategic processes while potentially outsourcing
other parts. The modular format can also facilitate risk assessment. This
approach involves a series of steps, completely integrated from the front end
to the back end, and is designed for objective and quick decision making
WhatsApp Privacy Controversy and India’s Data Protection Bill

Clause 40 of the PDP bill is particularly dangerous and could be detrimental
to the data rights of the users of WhatsApp. This provision empowers the Data
Protection Authority to include certain data fiduciaries in a regulatory
sandbox who would be exempt from the obligation of taking the consent of the
data principal in processing their data for up to 36 months. The GDPR does not
have any provision related to the regulatory sandbox. Such a sandbox might be
required to provide relaxations to certain corporations, such as those that
deal with Artificial Intelligence so that they can test their technology in a
Sandbox environment. However, it is a commonly accepted practice that in a
good regulatory sandbox the users whose data is taken voluntarily participate
in the exercise. Such a condition is altogether done away with by this
provision. The authority that has to assess the applications for inclusion in
a regulatory Sandbox is the Data Protection Authority (DPA). The members of
the DPA are to be selected by bureaucrats serving under the Union government.
So, it cannot be expected to work independently of government control (Clause
42(2)).
A Data Science Wish List for 2021 and Beyond

Sometimes, we simply cannot overcome the problem of needing more data. It
could be that data collection is too expensive or the data is not possible to
collect in a reasonable time frame. This is where synthetic data can provide
real value. Synthetic data can be created by training a model to understand
available data to such an extent that it can generate new data points that
look, act, and feel real, i.e. mimic the existing data. An example could be a
model that predicts how likely small and medium-sized businesses (SMBs) in the
retail sector might be to default on loans. Factors such as location, number
of employees, and annual turnover, might be key features in this scenario. A
synthetic data model could learn the typical values of these features and
create new data points that fit seamlessly into the real dataset, which can
then be expanded and used to train an advanced loan default prediction model.
... Another benefit of synthetic data is data privacy. In the financial
services industry, much of the data is sensitive and there are many legal
barriers to sharing datasets. Leveraging synthetic data is one way we can
reduce these barriers as synthetic datapoints feel real but do not relate to
real accounts and individuals.
Top 4 Blockchain Risks A CIO Should Know

Blockchain risks lead to malicious activities such as double-spending and
record hacking, which means a hacker will try to steal a blockchain
participants’ or cryptocurrency owner’s credentials and transfer money to
his/her account or hold the credentials as leverage for ransom. As per MIT’s
2019 report, since 2017, hackers have stolen around $2 million worth of
cryptocurrency. Another malicious activity is double-spending, where hackers
access the majority of the power and rewrite the transaction history. This
allows them to spend the cryptocurrency and erase the transaction from history
once they receive their orders. With digital money, the hacker can send the
merchant a copy of the digital token while retaining the original token and
using it again. Implementing and maintaining blockchain applications and
platforms is expensive. If there is a fault in the working or the system fails
due to the blockchain risks, it will cost a massive amount of money to fix
things. A blockchain expert is required to overcome such risks, and the expert
may charge a hefty amount to provide solutions.
Top Challenges Involved In Healthcare Data Management
Medical data is sensitive and must adhere to government regulations, such as
the Health Insurance Portability and Accountability Act of 1996 (HIPAA) in the
US. Data discovery challenges and poor data quality make it much more
difficult to perform the required audits, meet regulatory requirements and
limit the diversity of data healthcare providers can use for the benefit of
patients. Adhering to the HIPAA rules may help in effective data governance.
Effective data governance within a healthcare organization can help better
manage and use data, create processes for resolving data issues and
eventually, and enable users to make decisions based on high-quality
information assets. However, all this begins with better data collection and
making sure that the data collected is accurate, up-to-date, complete, and in
compliance with the HIPAA regulatory standards. A well-designed
HIPAA-compliant web form solution can be instrumental in enabling healthcare
organizations to manage and streamline data collection processes, including –
new patient forms, HIPAA release forms, contact update forms, patient medical
history forms, and consent forms.
CDO's Next Major Task: Enabling Data Access for Non-Analysts

Unlike product managers from two decades ago, today's product manager wants to
look at the user flow data on the website and design changes to UX flow to
improve revenue. He doesn't have the luxury of a dedicated analyst supporting
him for every question he has about his product. The marketing manager has
direct hands-on access to the CRM system. He is pulling targeted customers for
the next campaign and needs to have a lifetime value score for each of the
customers to target the highest value customers effectively. To resolve the
customer concerns quickly, customer support agents need access to what
happened when the customer accessed the website two days ago. He doesn't have
the luxury of the SLA of one-week resolution time of yesteryears; the customer
expects resolution during the call. The CDO needs a proper plan to enable
appropriate access to the right kind of data to the right person, with the
right security level. Barring that, the business's numerous stakeholders will
start standing up their individual mini data marts to serve their needs. If
that happens, the CDO's past five years of centralizing data sources will
amount to nothing. What is needed is a proper data access strategy and
governance for the entire enterprise.
Why ML should be written as pipelines from the get-go
Data scientists are not trained or equipped to be diligent to care about
production concepts such as reproducibility — they are trained to iterate and
experiment. They don’t really care about code quality and it is probably not
in the best interest of the company at an early point to be super diligent in
enforcing these standards, given the trade-off between speed and overhead.
Therefore, what is required is an implementation of a framework that is
flexible but enforces production standards from the get-go. A very natural way
of implementing this is via some form of pipeline framework that exposes an
automated, standardized way to run ML experiments in a controlled environment.
ML is inherently a process that can be broken down into individual, concrete
steps (e.g. preprocessing, training, evaluating, etc), so a pipeline is a good
solution here. Critically, by standardizing the development of these pipelines
at the early stages, organizations can lose the cycle of
destruction/recreation of ML models through multiple toolings and steps, and
hasten the speed of research to deployment.
Quote for the day:
“Just because you’re a beginner
doesn’t mean you can’t have strength.” -- Claudio Toyama
No comments:
Post a Comment