6 tips for CIOs managing technical debt

Many applications are created to solve a specific business problem that exists
in the here-and-now, without thought about how that problem will evolve or
what other adjacencies it pertains to. For example, a development team might
jump into solving the problem of creating a database to manage customer
accounts without taking into consideration how that database is integrated
with the sales/prospecting database. This can lead to thousands of staff-hours
downstream spent transforming contacts and importing them from the sales to
the customer database. ... One of the best-known problems in large
organizations is the disconnect between development and operations where
engineers design a product without first considering how their peers in
operations will support it, thus resulting in support processes that are
cumbersome, error-prone and inefficient. The entire programming discipline of
DevOps exists in large part to resolve this problem by including
representatives from the operations team on the development team -- but the
DevOps split exists outside programming. Infrastructure engineers may roll out
routers, edge computers or SD-WAN devices without knowing how the devices will
be patched or upgraded.
The Third Wave of Open Source Migration
The first and second open-source migration waves were periods of rapid
expansion for companies that rose up to provide commercial assurances for
Linux and the open-source databases, like Red Hat, MongoDB, and Cloudera. Or
platforms that made it easier to host open source workloads in a reliable,
consistent, and flexible manner via the cloud, like Amazon Web Services,
Google Cloud, and Microsoft Azure. This trend will continue in the third wave
of open source migration, as organizations interested in reducing cost without
sacrificing development speed will look to migrate more of their applications
to open source. They’ll need a new breed of vendor—akin to Red Hat or AWS—to
provide the commercial assurances they need to do it safely. It’s been
hard to be optimistic over the last few months. But as I look for a silver
lining in the current crisis, I believe there is an enormous opportunity for
organizations to get even more nimble in their use of open source. The last
20+ years of technology history have shown that open source is a powerful
weapon organizations can use to navigate a global downturn.
It’s Time to Implement Fair and Ethical AI

Companies have gotten the message that artificial intelligence should be
implemented in a manner that is fair and ethical. In fact, a recent study from
Deloitte indicates that a majority of companies have actually slowed down
their AI implementations to make sure these requirements are met. But the next
step is the most difficult one: actually implementing AI in a fair and ethical
way. A Deloitte study from late 2019 and early 2020 found that 95% of
executives surveyed said they were concerned about ethical risk in AI
adoption. While machine learning brings the possibility to improve the
quantity and quality of decision-making based on data, it also brings the
potential for companies to damage their brand and reduce the trust that
customers have placed in it if AI is implemented poorly. In fact, these risks
were so palpable to executives that 56% of them say they have slowed down
their AI adoptions, according to Deloitte’s study. While progress has been
made in getting the message out about fair and ethical AI, there is still a
lot of work to be done, says Beena Ammanath, the executive director of the
Deloitte AI Institute. “The first step is well underway, raising awareness.
Now I think most companies are aware of the risk associated” with AI
deployments, Ammanath says.
C# designer Torgersen: Why the programming language is still so popular and where it's going next
Like all modern programming languages, C# continues to evolve. With C# 9.0 on
course to arrive in November, the next update will focus on supporting "terse
and immutable" (i.e. unchangeable) representation of data shapes. "C# 9.0 is
trying to take some next steps for C# in making it easier to deal with data
that comes over the wire, and to express the right semantics for data, if you
will, that comes out of what we call an object-oriented paradigm originally,"
says Torgersen. C# 9.0 takes the next step in that direction with a feature
called Records, says Torgersen. These are a reference type that allow a whole
object to be immutable and instead make it act like a value. "We've found
ourselves, for a long time now, borrowing ideas from functional programming to
supplement the object-oriented programming in a way that really helps with,
for instance, cloud-oriented programming, and helps with data manipulation,"
Torgersen explains. "Records is a key feature of C# 9.0 that will help with
that." Beyond C# 9.0 is where things get more theoretical, though. Torgersen
insists that there's no concrete 'endgame' for the programming language – or
at least, not until it finally reaches some as-yet unknown expiration date.
DOJ's antitrust fight with Google: how we got here

The DOJ said in its filing that this case is "just beginning." The government
also says it's seeking to change Google's practices and that "nothing is off
the table" when it comes to undoing the "harm" caused by more than a decade of
anticompetitive business. Is it hard to compete with Google? The numbers speak
for themselves. But that's because the company is darn good at what it does.
Does Google use your data to help it improve search and advertising? Yes, it
does. But this suit is not about privacy. It's about Google's lucrative
advertising business. Just two years ago, the European Commission (EC) fined
Google over €8 billion for various advertising violations. Though the DOJ is
taking a similar tack, Google has done away with its most egregious
requirements. These included exclusivity clauses, which stopped companies from
placing competitors' search advertisements on their results pages and Premium
Placement, which reserved the most valuable page real estate for Google
AdSense ads. It's also true that Google has gotten much more aggressive about
using its own search pages to hawk its own preferred partners. As The
Washington Post's Geoffrey A. Fowler recently pointed out: if you search for
"T Shirts" on Google, the first real search result appears not on row one,
two, or three — those are reserved for advertising — or even rows four through
eight.
7 Hard-Earned Lessons Learned Migrating a Monolith to Microservices
It’s tempting to go from legacy right to the bleeding edge. And it’s an
understandable urge. You’re seeking to future-proof this time around so that
you won’t face another refactor again anytime soon. But I’d urge caution in
this regard, and to consider taking an established route. Otherwise, you may
find yourself wrangling two problems at once, and getting caught in a fresh
new rabbit hole. Most companies can’t afford to pioneer new technology and the
ones that can tend to do it outside of any critical path for the business. ...
For all its limitations, a monolithic architecture does have several intrinsic
benefits. One of which is that it’s generally simple. You have a single
pipeline and a single set of development tools. Venturing into a distributed
architecture involves a lot of additional complexity, and there are lots of
moving parts to consider, particularly if this is your first time doing it.
You’ll need to compose a set of tools to make the developer experience
palatable, possibly write some of your own, (although I’d caution against this
if you can avoid it), and factor in the discovery and learning process for all
that as well.
What is confidential computing? How can you use it?

To deliver on the promise of confidential computing, customers need to take
advantage of security technology offered by modern, high-performance CPUs,
which is why Google Cloud’s Confidential VMs run on N2D series VMs powered
by 2nd Gen AMD EPYC processors. To support these environments, we also had
to update our own hypervisor and low-level platform stack while also working
closely with the open source Linux community and modern operating system
distributors to ensure that they can support the technology. Networking and
storage drivers are also critical to the deployment of secure workloads and
we had to ensure we were capable of handling confidential computing traffic.
... With workforces dispersed, confidential computing can help organizations
collaborate on sensitive workloads in the cloud across geographies and
competitors, all while preserving privacy of confidential datasets. This can
lead to the development of transformation technologies – imagine, for
example, being able to more quickly build vaccines and cure diseases as a
result of this secure collaboration.
What A CIO Wants You to Know About IT Decision Making
CIOs know the organization needs new ideas, new products, new services, etc.
as well as changes to current rules, regulations, and business processes to
grow markets and stay ahead of competition. CIOs also know that the rules,
regulations, and processes are the foundations of trust. Those things that
seem to inhibit new ideas are the things that open customer’s minds to the
next new thing an organization might offer. Without the trust established by
following the rules, adhering to regulations, and at the far extreme, simply
obeying the law, customers would not stick around to try the next new thing.
For proof, look at the stock price of organizations that publicly announce
IT hacks, data loss, or other trust breaking events. Customers leave when
trust is broken, and part of the CIO’s role is to maintain that trust. While
CIOs know the standards that must be upheld, they also know how to navigate
those standards to support new ideas and change requests. Supporting new
ideas and adapting to change requires input from you as the user, the
employee or another member of the IT department, beyond just submitting the
IT change form or other automated process.
The Biggest Reason Not to Go All In on Kubernetes

Here’s the big thing that gets missed when a huge company open-sources their
internal tooling – you’re most likely not on their scale. You don’t have the
same resources, or the same problems as that huge company. Sure, you are
working your hardest to make your company so big that you have the same
scaling problems as Google, but you’re probably not there yet. Don’t get me
wrong: I love when large enterprises open-source some of their internal
tooling, as it’s beneficial to the open-source community and it’s a great
learning opportunity, but I have to remind myself that they are solving a
fundamentally different problem than I am. While I’m not suggesting that you
avoid planning ahead for scalability, getting something like Kubernetes set
up and configured instead of developing your main business application can
waste valuable time and funds. There is a considerable time and overhead
investment for getting your operations team up to speed on Kubernetes that
may not pay out. Google can afford to have its teams learning, deploying,
and managing new technology. But especially for smaller organizations,
premature scaling or premature optimization are legitimate concerns. You may
be attracted to the scalability, and it’s exciting. But, if you implement
too early, you will only get the complexity without any of the benefit.
Did Domain Driven Design help me to ease out the approach towards Event Driven Architecture?
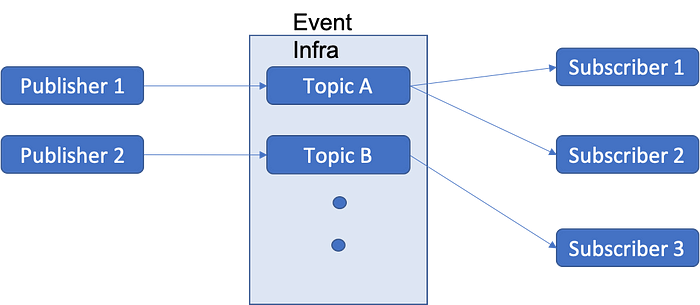
The most important aspect of the Domain Driven Design is setting the context
of a domain/sub-domain where domain would be a very high-level segregation for
different areas of business and sub-domain would be a particular part in the
domain representing a structure where users use a specific ubiquitous language
with domain model. Without going into much detail of the DDD, another paradigm
that one should be aware of is context mapping which consists of identifying
and classifying the relationships between bounded contexts within the domain.
One or more contexts can be related to each other in terms of goals, reuse
components (codes), a consumer and a producer. ... The principles guiding the
conglomeration of DDD and events help us to shift the focus from the nouns
(the domain objects) to the verbs (the events) in the domain. Focusing on flow
of events helps us to understand how change propagates in the system — things
like communication patterns, workflow, figuring out who is talking to whom,
who is responsible for what data, and so on. Events represent facts about the
domain and should be part of the Ubiquitous Language of the domain.
Quote for the day:
“The only way to do great work is to love what you do. If you haven’t found it yet, keep looking. Don’t settle.” -- Steve Jobs
No comments:
Post a Comment