Time to reset long-held habits for a new reality

With an extended crisis a real possibility, new habits must be adopted and
embraced for the business to adapt, recover and operate successfully in the
long-term. It’s important for CIOs to take the time to understand these
habits, how they have formed and if they are here to stay. One of the more
obvious habit changes we’ve all experienced is the shift from physical
meetings, where cases were presented and decisions made in person, to virtual
conferences. This has made people feel more exposed in decision making as the
human interaction of reading body language has been lost. However, people have
unknowingly started using data more and have shifted to making more data
driven decisions. If new and initial habits are here to stay for the
long-term, CIOs must embed them into the new DNA of the business. If they
aren’t, however, it’s crucial to curb and manage these new habits before they
become automatically ingrained and costly to reverse. This happened to a CIO I
recently spoke with, who made a massive technology investment, changed vendors
and even shortened office leases in the rush to shift their organisation to a
remote working model.
Getting Serious About Data and Data Science

The obvious approach to addressing these mistakes is to identify wasted
resources and reallocate them to more productive uses of data. This is no
small task. While there may be budget items and people assigned to support
analytics, AI, architecture, monetization, and so on, there are no budgets and
people assigned to waste time and money on bad data. Rather, this is hidden
away in day-in, day-out work — the salesperson who corrects errors in data
received from marketing, the data scientist who spends 80% of his or her time
wrangling data, the finance team that spends three-quarters of its time
reconciling reports, the decision maker who doesn’t believe the numbers and
instructs his or her staff to validate them, and so forth. Indeed, almost all
work is plagued by bad data. The secret to wasting less time and money
involves changing one’s approach from the current “buyer/user beware”
mentality, where everyone is left on their own to deal with bad data, to
creating data correctly — at the source. This works because finding and
eliminating a single root cause can prevent thousands of future errors and
eliminate the need to correct them downstream. This saves time and money —
lots of it! The cost of poor data is on the order of 20% of revenue, and much
of that expense can be eliminated permanently.
Most Data Science Projects Fail, But Yours Doesn’t Have To

Through data science automation, companies are not only able to fail faster
(which is a good thing in the case of data science), but to improve their
transparency efforts, deliver minimum value pipelines (MVPs), and continuously
improve through iteration. Why is failing fast a positive? While perhaps
counterintuitive, failing fast can provide a significant benefit. Data science
automation allows technical and business teams to test hypotheses and carry
out the entire data science workflow in days. Traditionally, this process is
quite lengthy — typically taking months — and is extremely costly. Automation
allows failing hypotheses to be tested and eliminated faster. Rapid failure of
poor projects provides savings both financially as well as in increased
productivity. This rapid try-fail-repeat process also allows businesses to
discover useful hypotheses in a more timely manner. Why is white box modelling
important? White-box models (WBMs) provide clear explanations of how they
behave, how they produce predictions, and what variables influenced the model.
WBMs are preferred in many enterprise use cases because of their transparent
‘inner-working’ modeling process and easily interpretable behavior.
Microsoft: Hacking Groups Shift to New Targets
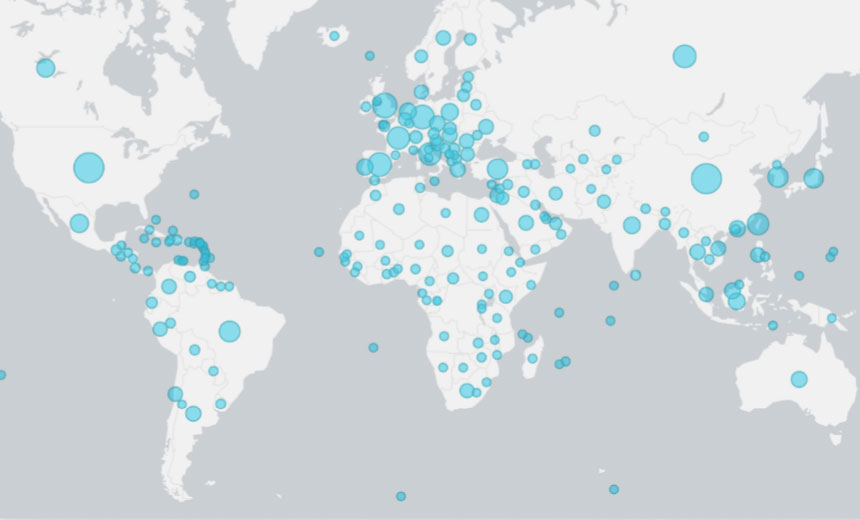
Microsoft notes that, in the last two years, the company has sent out 13,000
notifications to customers who have been targeted by nation-states. The
majority of these nation-state attacks originate in Russia, with Iran, China
and North Korea also ranking high, according to Microsoft. The U.S. was the
most frequent target of these nation-state campaigns, accounting for nearly
70% of the attacks Microsoft tracked, followed by the U.K., Canada, South
Korea and Saudi Arabia. And while critical infrastructure remains a tempting
target for sophisticated hacking groups backed by governments, Microsoft notes
that organizations that are deemed noncritical are increasingly the focus of
these campaigns. "In fact, 90% of our nation-state notifications in the past
year have been to organizations that do not operate critical infrastructure,"
Tom Burt, corporate vice president of customer security and trust at
Microsoft, writes in a blog post. "Common targets have included
nongovernmental organizations, advocacy groups, human rights organizations and
think tanks focused on public policy, international affairs or security. This
trend may suggest nation-state actors have been targeting those involved in
public policy and geopolitics, especially those who might help shape official
government policies."
Why Perfect Technology Abstractions Are Sure To Fail

Everything’s an abstraction these days. How many “existential threats” are
there? We need “universal” this and that, but let’s not forget that relativism
– one of abstraction’s enforcers – is hovering around all the time making
things better or worse, depending on the objective of the solution du jour.
Take COVID-19, for example. Based upon the assumption that the US knows how to
solve “enterprise” problems – the abstract principle at work – the US has done
a great job. But relativism kills the abstraction: the US has roughly 4% of
the world’s population and 25% of the world’s deaths. How many technology
solutions sound good in the abstract, but are relatively ineffective?
The Agile family is an abstract solution to an age-old problem: requirements
management and timely cost-effective software applications design and
development. But the relative context is way too frequent failure. We’ve been
wrestling with requirements validation for decades, which is why the field
constantly invented methods, tools and techniques to manage requirements and
develop applications, like rapid application development (RAD), rapid
prototyping, the Unified Process (UP) and extreme programming (XP), to name a
few.
.NET Framework Connection Pool Limits and the new Azure SDK for .NET
Connection pooling in the .NET framework is controlled by the
ServicePointManager class and the most important fact to remember is that the
pool, by default, is limited to 2 connections to a particular endpoint
(host+port pair) in non-web applications, and to unlimited connection per
endpoint in ASP.NET applications that have autoConfig enabled (without
autoConfig the limit is set to 10). After the maximum number of connections is
reached, HTTP requests will be queued until one of the existing connections
becomes available again. Imagine writing a console application that uploads
files to Azure Blob Storage. To speed up the process you decided to upload using
using 20 parallel threads. The default connection pool limit means that even
though you have 20 BlockBlobClient.UploadAsync calls running in parallel only 2
of them would be actually uploading data and the rest would be stuck in the
queue. The connection pool is centrally managed on .NET Framework. Every
ServiceEndpoint has one or more connection groups and the limit is applied to
connections in a connection group.
Digital transformation: The difference between success and failure

Commenting on the survey, Ritam Gandhi, founder and director of Studio
Graphene, said: "They say necessity is the mother of invention, and the
pandemic is evidence of that. While COVID-19 has put unprecedented strain on
businesses, it has also been key to fast-tracking digital innovation across
the private sector. "The research shows that the crisis has prompted
businesses to break down the cultural barriers which previously stood in the
way of experimenting with new digital solutions. This accelerated digital
transformation offers a positive outlook for the future -- armed with
technology, businesses will now be much better-placed to adapt to any
unforeseen challenges that may come their way." Digital transformation,
whatever precise form it takes, is built on the internet and so, even in
normal times, internet infrastructure needs to be robust. In abnormal times
such as the current pandemic, with widespread remote working and increased
reliance on online services generally, a resilient internet is vital. So how
did it hold up in the first half of 2020?
From Cloud to Cloudlets: A New Approach to Data Processing?
Though the term “cloudlet” is still relatively new (and relatively obscure)
the central concept of it is not. Even from the earliest days of cloud
computing, it was recognized that sending large amounts of data to the cloud
to be processed raises bandwidth issues. Over much of the past decade, this
issue has been masked by the relatively small amounts of data that devices
have shared with the cloud. Now, however, the limitations of the standard
cloud model are becoming all too clear. There is a growing consensus that the
growing volume of end-device data to the cloud for processing is too
resource-intensive, time-consuming, and inefficient to be processed by large,
monolithic clouds. Instead, say some analysts, these data are better
processed locally. This processing will either need to take place in the
device that is generating these data, or in a semi-local cloud that is
interstitial between the device and an organization's central cloud storage.
This is what is meant by a "cloudlet”: intelligent device, cloudlet, and
cloud.
Align Your Data Architecture with the Strategic Plan

Data collected today impacts business direction and growth for tomorrow. The
benefits to having and using data that align with strategic goals include
the ability to make evidence-based decisions, which can provide insights on
how to reduce costs and increase efficiency of other resource utilization.
Data are only valuable when they correlate to a company’s working goals.
That means available data should assist in making the most important
decisions at the present time. Data-based decision-making also coincides
with lower overall costs. Examples of data that should be considered in any
data set include digital data, such as web traffic, customer relationship
management (CRM) data, email marketing data, customer service data, and
third-party data. ... For some data sets, there may not be a need (and
therefore the associated costs) for big data processing. Collecting all data
that exists, just because it is available, does not guarantee inherent value
to the company. Furthermore, data from multiple sources may not be
structured and may require heavy lifting on the processing side. Secondly,
clearly defined data points, such as demographics, financial background and
market trends, will add varying value to any organization and predict the
volume of data and processing needed for meaningful optimization.
Information Quality Characteristics
A personal experience involved the development of an initial data warehouse
for global financial information. The initial effort was to build a new source
of global information that would be more available and would allow senior
management to monitor the current month’s progress toward budget goals for
gross revenue and other profit and loss (P&L) items. The effort was to
build the information from the source systems that feed the process used to
develop the P&L statements. To deliver information that would be
believable to the senior executives, a stated goal was to match the published
P&L information. After a great deal of effort, the initial goal was
changed to deliver the capability for gross revenue. This change was
necessitated because there was no consistent source data for the other P&L
items. Even the new goal proved elusive as the definition for gross revenue
varied among the over 75 corporate subsidiaries. Initial attempts to aggregate
sales for a subsidiary that matched reported amounts proved to be extremely
challenging. The team had to develop a different process to aggregate sales
for each subsidiary. Unfortunately, that process was not always successful in
matching the published revenue amounts.
Quote for the day:
"Inspired leaders move a business beyond problems into opportunities." -- Dr. Abraham Zaleznik
No comments:
Post a Comment