New Zealand stock exchange hit by cyber attack for second day

The incident follows a number of alleged cyber attacks by foreign actors, such
as the targeting of a range of government and private-sector organisations in
Australia. In a statement earlier on Wednesday, the NZX blamed Tuesday’s
attack on overseas hackers, saying that it had “experienced a volumetric DDoS
attack from offshore via its network service provider, which impacted NZX
network connectivity”. It said the attack had affected NZX websites and the
markets announcement platform, causing it to call a trading halt at 3.57pm. It
said the attack had been “mitigated” and that normal market operations would
resume on Wednesday, but this subsequent attack has raised questions about
security. A DDoS attack aims to overload traffic to internet sites by
infecting large numbers of computers with malware that bombards the targeted
site with requests for access. Prof Dave Parry, of the computer science
department at Auckland University of Technology, said it was a “very serious
attack” on New Zealand’s critical infrastructure. He warned that it showed a
“rare” level of sophistication and determination, and also flagged security
issues possibly caused by so many people working from home.
Disruption Happens With What You Don't Know You Don't Know
"There are things we know we don't know, and there are things we don't know we
don't know." And what I'm trying to explain is the practitioners point of
view. Now, when I come to you and I tell you, you know what, "You don't know
this, Peter. You don't know this. And if you do this, you would be making a
lot of money." You will say, "Who are you to tell me that?" So I need to build
confidence first. So the first part of the discussion starts from telling you
what you already know. So when you do use the data, the idea is — and to
create a report, and that's what reports are for. Look at how organizations
make decisions — what they do is they get a report and they take a decision on
that report. But 95% of the time, I know that people who are making that
decision or are reading that report know the answer in the report. That's why
they're comfortable with the report, right? So let's look at a board meeting
where the board has a hunch that this quarter they're going to make 25%
increase in their sales. They have the hunch. Now, that is where they're going
to get a report which will save 24% or 29%, it will be in the ballpark range.
So there's no unknown. But if I'm only telling you what you already
know,
How the Coronavirus Pandemic Is Breaking Artificial Intelligence and How to Fix It
When trained on huge data sets, machine learning algorithms often ferret out
subtle correlations between data points that would have gone unnoticed to
human analysts. These patterns enable them to make forecasts and predictions
that are useful most of the time for their designated purpose, even if
they’re not always logical. For instance, a machine-learning algorithm that
predicts customer behavior might discover that people who eat out at
restaurants more often are more likely to shop at a particular kind of
grocery store, or maybe customers who shop online a lot are more likely to
buy certain brands. “All of those correlations between different variables
of the economy are ripe for use by machine learning models, which can
leverage them to make better predictions. But those correlations can be
ephemeral, and highly context-dependent,” David Cox, IBM director at the
MIT-IBM Watson AI Lab, told Gizmodo. “What happens when the ground
conditions change, as they just did globally when covid-19 hit? Customer
behavior has radically changed, and many of those old correlations no longer
hold. How often you eat out no longer predicts where you’ll buy groceries,
because dramatically fewer people eat out.”

How the edge and the cloud tackle latency, security and bandwidth issues
With the rise of IoT, edge computing is rapidly gaining popularity as it
solves the issues the IoT has when interacting with the cloud. If you
picture all your smart devices in a circle, the cloud is centralised in
the middle of them; edge computing happens on the edge of that cloud.
Literally referring to geographic location, edge computing happens much
nearer a device or business, whatever ‘thing’ is transmitting the data.
These computing resources are decentralised from data centres; they are on
the ‘edge’, and it is here that the data gets processed. With edge
computing, data is scrutinised and analysed at the site of production,
with only relevant data being sent to the cloud for storage. This means
much less data is being sent to the cloud, reducing bandwidth use, privacy
and security breaches are more likely at the site of the device making
‘hacking’ a device much harder, and the speed of interaction with data
increases dramatically. While edge and cloud computing are often seen as
mutually exclusive approaches, larger IoT projects frequently require a
combination of both. Take driverless cars as an example.
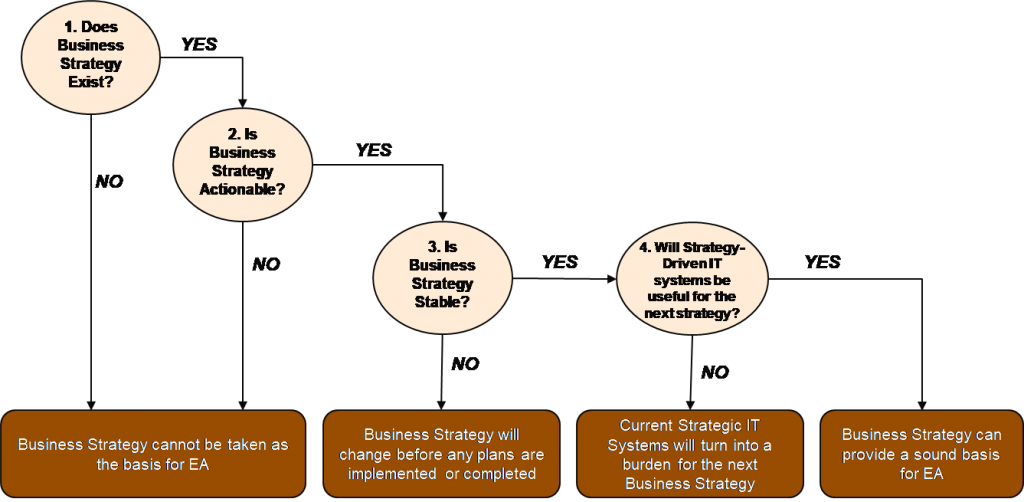
Basing Enterprise Architecture on Business Strategy: 4 Lessons for Architects
Analogous ideas regarding the primacy of the business strategy are also
expressed by other authors, who argue that EA and IT planning efforts in
organizations should stem directly from the business strategy. Bernard
states that “the idea of Enterprise Architecture is that of integrating
strategy, business, and technology”. Parker and Brooks argue that the
business strategy and EA are interrelated so closely that they represent
“the chicken or the egg” dilemma. These views are supported by Gartner
whose analysts explicitly define EA as “the process of translating
business vision and strategy into effective enterprise change”. Moreover,
Gartner analysts argue that “the strategy analysis is the foundation of
the EA effort” and propose six best practices to align EA with the
business strategy. Unsurprisingly, similar views are also shared by
academic researchers, who analyze the integration between the business
strategy and EA modeling of the business strategy in the EA context. To
summarize, in the existing EA literature the business strategy is widely
considered as the necessary basis for EA and for many authors the very
concepts of business strategy and EA are inextricably coupled
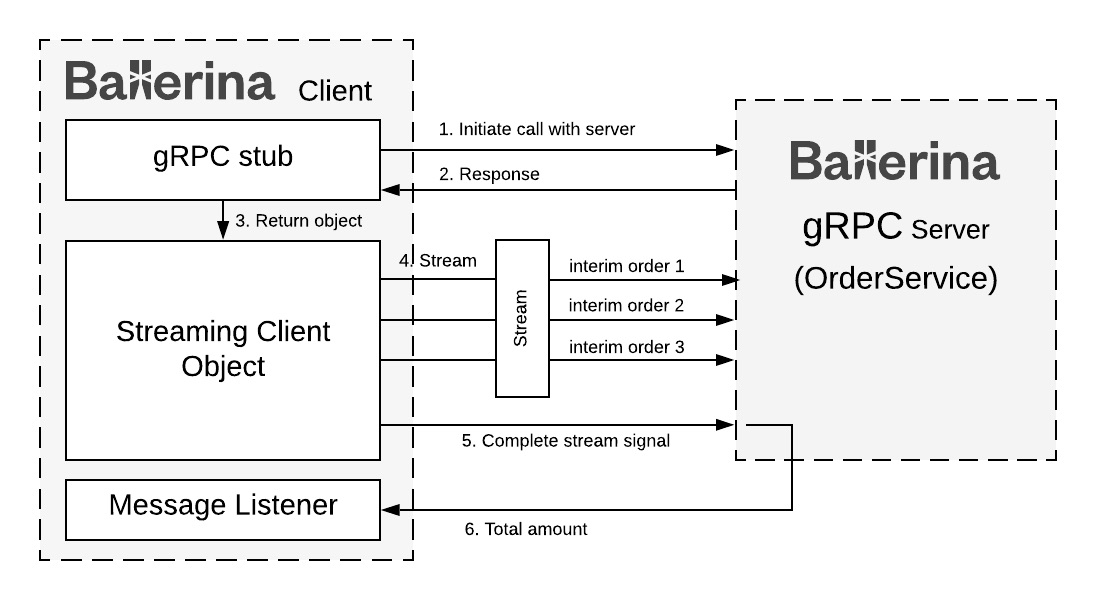
Building Effective Microservices with gRPC, Ballerina, and Go
In modern microservice architecture, we can categorize microservices into
two main groups based on their interaction and communication. The first
group of microservices acts as external-facing microservices, which are
directly exposed to consumers. They are mainly HTTP-based APIs that use
conventional text-based messaging payloads (JSON, XML, etc.) that are
optimized for external developers, and use Representational State Transfer
(REST) as the de facto communication technology. REST’s ubiquity and
rich ecosystem play a vital role in the success of these external-facing
microservices. OpenAPI provides
well-defined specifications for describing, producing, consuming, and
visualizing these REST APIs. API management systems work well with these
APIs and provide security, rate limiting, caching, and monetizing along
with business requirements. GraphQL can
be an alternative for the HTTP-based REST APIs but it is out of scope for
this article. The other group of microservices are internal and don’t
communicate with external systems or external developers. These
microservices interact with each other to complete a given set of tasks.
Internal microservices use either synchronous or asynchronous
communication.
Lessons learned after migrating 25+ projects to .NET Core

One thing that you need to be aware of when jumping from .NET Framework to
.NET Core, is a faster roll-out of new versions. That includes shorter
support intervals too. With .NET Framework, 10 years of support wasn't
unseen, where .NET Core 3 years seem like the normal interval. Also, when
picking which version of .NET Core you want to target, you need to look into
the support level of each version. Microsoft marks certain versions with
long time support (LTS) which is around 3 years, while others are versions
in between. Stable, but still versions with a shorter support period.
Overall, these changes require you to update the .NET Core version more
often than you have been used to or accept to run on an unsupported
framework version. ... The upgrade path isn't exactly straight-forward.
There might be some tools to help with this, but I ended up migrating
everything by hand. For each website, I took a copy of the entire repo. Then
deleted all files in the working folder and created a new ASP.NET Core MVC
project. I then ported each thing one by one. Starting with copying in
controllers, views, and models and making some global search-replace
patterns to make it compile.
Changing How We Think About Change

Many of the most impressive and successful corporate pivots of the past
decade have taken the form of changes of activity — continuing with the same
strategic path but fundamentally changing the activities used to pursue it.
Think Netflix transitioning from a DVD-by-mail business to a streaming
service; Adobe and Microsoft moving from software sales models to monthly
subscription businesses; Walmart evolving from physical retail to
omnichannel retail; and Amazon expanding into physical retailing with its
Whole Foods acquisition and launch of Amazon Go. Further confusing the
situation for decision makers is the ill-defined relationship between
innovation and change. Most media commentary focuses on one specific form of
innovation: disruptive innovation, in which the functioning of an entire
industry is changed through the use of next-generation technologies or a new
combination of existing technologies. (For example, the integration of GPS,
smartphones, and electronic payment systems — all established technologies —
made the sharing economy possible.) In reality, the most common form of
innovation announced by public companies is digital transformation
initiatives designed to enhance execution of the existing strategy by
replacing manual and analog processes with digital ones.
More than regulation – how PSD2 will be a key driving force for an Open Banking future

A crucial factor standing in the way of the acceleration towards Open
Banking has been the delay to API development. These APIs are the technology
that TPPs rely on to migrate their services and customer base to remain PSD2
compliant. One of the contributing factors was that the RTS, which apply to
PSD2, left room for too many different interpretations. This ambiguity
caused banks to slip behind and delay the creation of their APIs. This delay
hindered European TPPs in migrating their services without losing their
customer base, particularly outside the UK, where there has been no
regulatory extension and where the API framework is the least advanced.
Levels of awareness of the new regulations and changes to how customers
access bank accounts and make online payments are very low among consumers
and merchants. This leads to confusion and distrust of the authentication
process in advance of the SCA roll-out. Moreover, because the majority of
customers don’t know about Open Banking yet, they aren’t aware of the
benefits. Without customer awareness and demand it may be very hard for TPPs
to generate interest and uptake for their products.
Election Security's Sticky Problem: Attackers Who Don't Attack Votes
One of the lessons drawn by both sides was how inexpensive it was for the red
team to have an impact on the election process. There was no need to "spend" a
zero-day or invest in novel exploits. Manipulating social media is a known
tactic today, while robocalls are cheap-to-free. Countering the red team's
tactics relied on coordination between the various government authorities and
ensuring communication redundancy between agencies. Anticipating
disinformation plans that might lead to unrest also worked well for the blue
team, as red team efforts to bring violence to polling places were put down
before they bore fruit. The red team also tried to interfere with voting by
mail; they hacked a major online retailer to send more packages through the
USPS than normal, and used label printers to put bar codes with instructions
for resetting sorting machines on a small percentage of those packages. While
there was some slowdown, there was no significant disruption of the mail
around the election.
Quote for the day:
"It's hard to get the big picture when you have a small frame of reference." -- Joshing Stern
No comments:
Post a Comment