Secure at every step: A guide to DevSecOps, shifting left, and GitOps

In practice, to hold teams accountable for what they develop, processes need
to shift left to earlier in the development lifecycle, where development teams
are. By moving steps like testing, including security testing, from a final
gate at deployment time to an earlier step, fewer mistakes are made, and
developers can move more quickly. The principles of shifting left also apply
to security, not only to operations. It’s critical to prevent breaches before
they can affect users, and to move quickly to address newly discovered
security vulnerabilities and fix them. Instead of security acting as a gate,
integrating it into every step of the development lifecycle allows your
development team to catch issues earlier. A developer-centric approach means
they can stay in context and respond to issues as they code, not days later at
deployment, or months later from a penetration test report. Shifting left is a
process change, but it isn’t a single control or specific tool—it’s about
making all of security more developer-centric, and giving developers security
feedback where they are. In practice, developers work with code and in Git, so
as a result, we’re seeing more security controls being applied in Git.
Resilience in Deep Systems
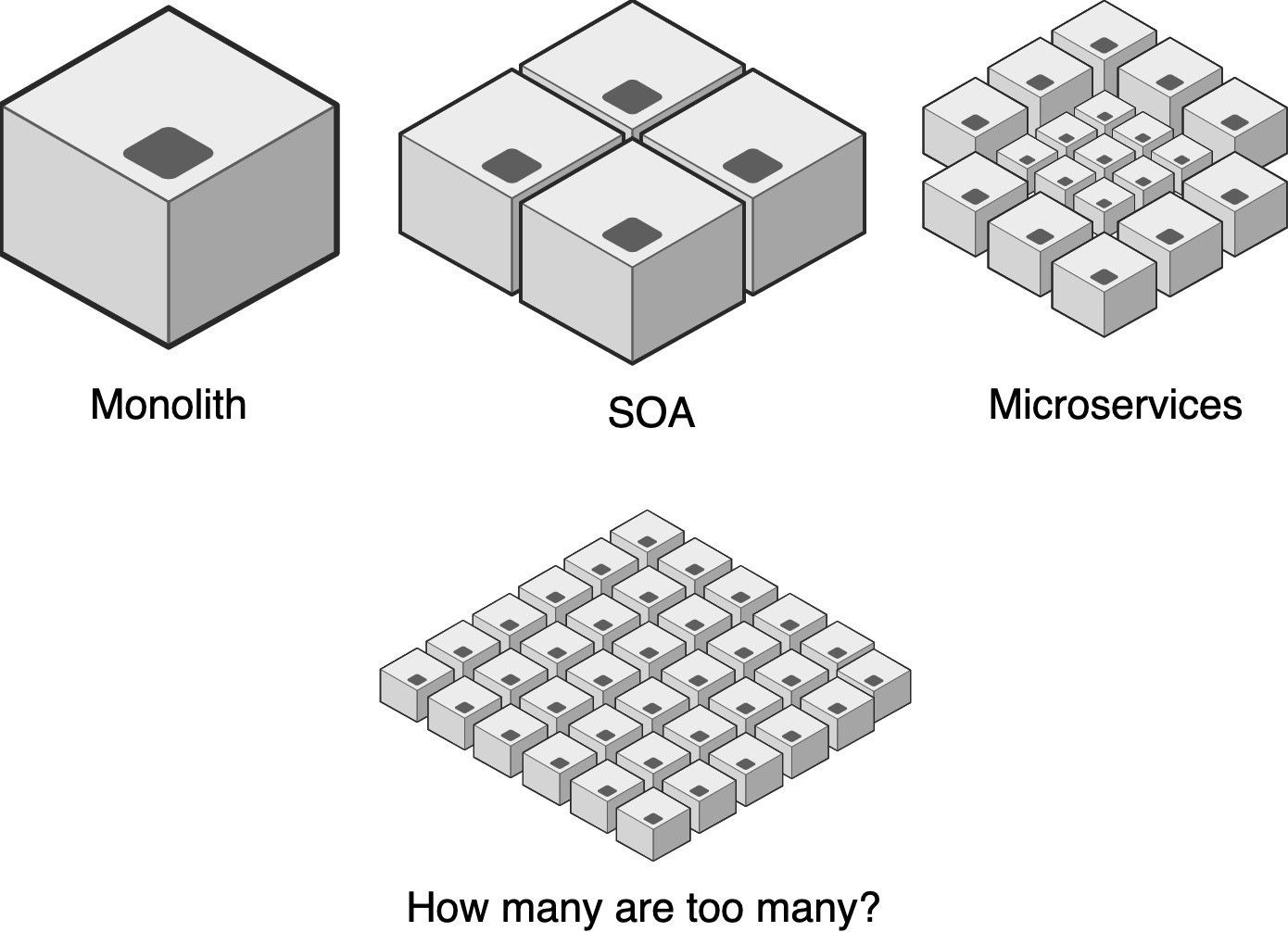
As your system grows, the connections between microservices become more
complex. Communicating in a fault-tolerant way, and keeping the data that is
moving between services consistent and fresh becomes a huge challenge.
Sometimes microservices must communicate in a synchronous way. However, using
synchronous communications, like REST, across the entire deep system makes the
various components in the chain very tightly coupled to each other. It creates
an increased dependency on the network’s reliability. Also, every microservice
in the chain needs to be fully available to avoid data inconsistency, or
worse, system outage if one of the links in a microservices chain is down. In
reality, we found that such a deep system behaves more like a monolith, or
more precisely a distributed monolith, which prevents the full benefits of
microservices from being enjoyed. Using an asynchronous, event-driven
architecture enables your microservices to publish fresh data updates to other
microservices. Unlike synchronous communication, adding more subscribers to
the data is easy and will not hammer the publisher service with more traffic.
Security Jobs With a Future -- And Ones on the Way Out
"The jobs aren't the same as two or three years ago," he acknowledges. "The
types of skill sets employers are looking for is evolving rapidly." Three
factors have led the evolution, O'Malley says. The first, of course, is
COVID-19 and the sudden need for large-scale remote workforces. "Through this
we are seeing a need for people who understand zero-trust work environments,"
he says. "Job titles around knowing VPN [technology] and how to enable remote
work with the understanding that everyone should be considered an outsider
[are gaining popularity]." The next trend is cloud computing. With more
organizations putting their workloads in public and private clouds, they've
become less interested in hardware expertise and want people who understand
the tech's complex IT infrastructure. A bigger focus on business
resiliency is the third major trend. The know-how needed here emphasizes
technologies that make a network more intelligent and enable it to learn how
to protect itself. Think: automation, artificial intelligence, and machine
learning. The Edge asked around about which titles and skills security hiring
managers are interested in today.
Agile FAQ: Get started with these Agile basics
The Agile Manifesto prioritizes working software over comprehensive
documentation -- though don't ignore the latter completely. This is an Agile
FAQ for newcomers and experienced practitioners alike, as many people
mistakenly think they should avoid comprehensive documentation in Agile. The
Agile team should produce software documentation. Project managers and teams
should determine what kind of documentation will deliver the most value.
Product documentation, for example, helps customers understand, use and
troubleshoot the product. Process documentation represents all of the
information about planning, development and release. Similarly, Agile
requirements are difficult to gather, as they change frequently, but they're
still valuable. Rather than set firm requirements at the start of a project,
developers change requirements during a project to best suit customer wishes
and needs. Agile teams iterate regularly, and they should likewise adapt
requirements accordingly. ... When developers start a new project, it can be
hard to estimate how long each piece of the project will take. Agile teams can
typically gauge how complex or difficult a requirement will be to fulfill,
relative to the other requirements.
Facebook’s new A.I. takes image recognition to a whole new level

This might seem a strange piece of research for Facebook to focus on. Better
news feed algorithms? Sure. New ways of suggesting brands or content you could
be interested in interacting with? Certainly. But turning 2D images into 3D
ones? This doesn’t immediately seem like the kind of research you’d expect a
social media giant to be investing. But it is — even if there’s no immediate
plan to turn this into a user-facing feature on Facebook. For the past seven
years, Facebook has been working to establish itself as a leading presence in
the field of artificial intelligence. In 2013, Yann LeCun, one of the world’s
foremost authorities on deep learning, took a job at Facebook to do A.I. on a
scale that would be almost impossible in 99% of the world’s A.I. labs. Since
then, Facebook has expanded its A.I. division — called FAIR (Facebook A.I.
Research) — all over the world. Today, it dedicates 300 full-time engineers
and scientists to the goal of coming up with the cool artificial intelligence
tech of the future. It has FAIR offices in Seattle, Pittsburgh, Menlo Park,
New York, Montreal, Boston, Paris, London, and Tel Aviv, Israel — all staffed
by some of the top researchers in the field.
Honeywell Wants To Show What Quantum Computing Can Do For The World

The companies that understand the potential impact of quantum computing on
their industries, are already looking at what it would take to introduce this
new computing capability into their existing processes and what they need to
adjust or develop from scratch, according to Uttley. These companies will be
ready for the shift from “emergent” to “classically impractical” which is
going to be “a binary moment,” and they will be able “to take advantage of it
immediately.” The last stage of the quantum evolution will be classically
impossible—"you couldn’t in the timeframe of the universe do this computation
on a classical best-performing supercomputer that you can on a quantum
computer,” says Uttley. He mentions quantum chemistry, machine learning,
optimization challenges (warehouse routing, aircraft maintenance) as
applications that will benefit from quantum computing. But “what shows the
most promise right now are hybrid [resources]—“you do just one thing, very
efficiently, on a quantum computer,” and run the other parts of the algorithm
or calculation on a classical computer. Uttley predicts that “for the
foreseeable future we will see co-processing,” combining the power of today’s
computers with the power of emerging quantum computing solutions.
Data Prep for Machine Learning: Encoding

Data preparation for ML is deceptive because the process is conceptually easy.
However, there are many steps, and each step is much more complicated than you
might expect if you're new to ML. This article explains the eighth and ninth
steps ... Other Data Science Lab articles explain the other seven steps. The
data preparation series of articles can be found here. The tasks ... are
usually not followed in a strictly sequential order. You often have to
backtrack and jump around to different tasks. But it's a good idea to follow
the steps shown in order as much as possible. For example, it's better to
normalize data before encoding because encoding generates many additional
numeric columns which makes it a bit more complicated to normalize the
original numeric data. ... A complete explanation of the many different types
of data encoding would literally require an entire book on the subject. But
there are a few encoding techniques that are used in the majority of ML
problem scenarios. Understanding these few key techniques will allow you to
understand the less-common techniques if you encounter them. In most
situations, predictor variables that have three or more possible values are
encoded using one-hot encoding, also called 1-of-N or 1-of-C encoding.
NIST Issues Final Guidance on 'Zero Trust' Architecture

NIST notes that zero trust is not a stand-alone architecture that can be
implemented all at once. Instead, it's an evolving concept that cuts across
all aspects of IT. "Zero trust is the term for an evolving set of
cybersecurity paradigms that move defenses from static, network-based
perimeters to focus on users, assets and resources," according to the
guidelines document. "Transitioning to [zero trust architecture] is a journey
concerning how an organization evaluates risk in its mission and cannot simply
be accomplished with a wholesale replacement of technology." Rose notes that
to implement zero trust, organizations need to delve deeper into workflows and
ask such questions as: How are systems used? Who can access them? Why are they
accessing them? Under what circumstances are they accessing them? "You're
building a security architecture and a set of policies by bringing in more
sources of information about how to design those policies. ... It's a more
holistic approach to security," Rose says. Because the zero trust concept is
relatively new, NIST is not offering a list of best practices, Rose says.
Organizations that want to adopt this concept should start with a risk-based
analysis, he stresses.
Compliance in a Connected World

Early threat detection and response is clearly part of the answer to
protecting increasingly connected networks, because without threat, the risk,
even to a vulnerable network, is low. However, ensuring the network is not
vulnerable to adversaries in the first place is the assurance that many SOCs
are striving for. Indeed, one cannot achieve the highest level of security
without the other. Even with increased capacity in your SOC to review cyber
security practices and carry out regular audits, the amount of information
garnered and its accuracy, is still at risk of being far too overwhelming for
most teams to cope with. For many organisations the answers lie in
accurate audit automation and the powerful analysis of aggregated diagnostics
data. This enables frequent enterprise-wide auditing to be carried out without
the need for skilled network assessors to be undertaking repetitive, time
consuming tasks which are prone to error. Instead, accurate detection and
diagnostics data can be analysed via a SIEM or SOAR dashboard, which allows
assessors to group, classify and prioritise vulnerabilities for fixes which
can be implemented by a skilled professional, or automatically via a
playbook.
The biggest data breach fines, penalties and settlements so far
GDPR fines are like buses: You wait ages for one and then two show up at the
same time. Just days after a record fine for British Airways, the ICO issued a
second massive fine over a data breach. Marriott International was fined £99
million [~$124 million] after payment information, names, addresses, phone
numbers, email addresses and passport numbers of up to 500 million customers
were compromised. The source of the breach was Marriott's Starwood subsidiary;
attackers were thought to be on the Starwood network for up to four years and
some three after it was bought by Marriott in 2015. According to the ICO’s
statement, Marriott “failed to undertake sufficient due diligence when it bought
Starwood and should also have done more to secure its systems.” Marriott CEO
Arne Sorenson said the company was “disappointed” with the fine and plans to
contest the penalty. The hotel chain was also fined 1.5 million Lira
(~$265,000) by the Turkish data protection authority — not under the GDPR
legislation — for the beach, highlighting how one breach can result in multiple
fines globally.
Quote for the day:
"Making the development of people an equal partner with performance is a decision you make." -- Ken Blanchard
No comments:
Post a Comment