Designing data governance that delivers value

Without quality-assuring governance, companies not only miss out on
data-driven opportunities; they waste resources. Data processing and cleanup
can consume more than half of an analytics team’s time, including that of
highly paid data scientists, which limits scalability and frustrates
employees. Indeed, the productivity of employees across the organization can
suffer: respondents to our 2019 Global Data Transformation Survey reported
that an average of 30 percent of their total enterprise time was spent on
non-value-added tasks because of poor data quality and availability ... The
first step is for the DMO to engage with the C-suite to understand their
needs, highlight the current data challenges and limitations, and explain the
role of data governance. The next step is to form a data-governance council
within senior management (including, in some organizations, leaders from the
C-suite itself), which will steer the governance strategy toward business
needs and oversee and approve initiatives to drive improvement—for example,
the appropriate design and deployment of an enterprise data lake—in concert
with the DMO. The DMO and the governance council should then work to define a
set of data domains and select the business executives to lead them.
How to Kill Your Developer Productivity
The problems start when teams get carried away with microservices and take the
"micro" a little too seriously. From a tooling perspective you will now have
to deal with a lot more yml files, docker files, with dependencies between
variables of these services, routing issues, etc. They need to be maintained,
updated, cared for. Your CI/CD setup as well as your organizational structure
and probably your headcount needs a revamp. If you go into microservices for
whatever reason, make sure you plan sufficient time to restructure your
tooling setup and workflow. Just count the number of scripts in various places
you need to maintain. ... Kubernetes worst case: Colleague XY really wanted to
get his hands dirty and found a starter guide online. They set up a cluster on
bare-metal and it worked great with the test-app. They then started migrating
the first application and asked their colleagues to start interacting with the
cluster using kubectl. Half of the team is now preoccupied with learning this
new technology. The poor person that is now maintaining the cluster will be
full time on this the second the first production workload hits the fan.
A Brief History of Data Lakes

Data Lakes are consolidated, centralized storage areas for raw, unstructured,
semi-structured, and structured data, taken from multiple sources and lacking
a predefined schema. Data Lakes have been created to save data that “may have
value.” The value of data and the insights that can be gained from it are
unknowns and can vary with the questions being asked and the research being
done. It should be noted that without a screening process, Data Lakes can
support “data hoarding.” A poorly organized Data Lake is referred to as a Data
Swamp. Data Lakes allow Data Scientists to mine and analyze large amounts
of Big Data. Big Data, which was used for years without an official name, was
labeled by Roger Magoulas in 2005. He was describing a large amount of data
that seemed impossible to manage or research using the traditional SQL tools
available at the time. Hadoop (2008) provided the search engine needed for
locating and processing unstructured data on a massive scale, opening the door
for Big Data research. In October of 2010, James Dixon, founder and
former CTO of Pentaho, came up with the term “Data Lake.” Dixon argued Data
Marts come with several problems, ranging from size restrictions to narrow
research parameters.
What is agile enterprise architecture?
An important group of agility dimensions relates to the process of strategic
planning, where business leaders and architects collectively develop the
global future course of action for business and IT. One of these dimensions is
the overall amount of time and effort devoted to strategic planning. Some
companies invest considerable resources in the discussions of their future
evolution, while other companies pay much less attention to these questions.
Another dimension is the organisational scope covered by strategic planning.
Some companies embrace all their business units and areas in their long-range
planning efforts, while others intentionally limit the scope of these efforts
to a small number of core business areas. A related dimension is the horizon
of strategic planning. Some organisations plan for no more than 2-3 years
ahead, but others need a five-year, or even longer, planning horizons. Yet
another relevant dimension is how the desired future is defined. Some
companies create rather concrete descriptions of their target states, when
others define their future only in terms of planned initiatives in investment
roadmaps.
How to Guard Against Governance Risks Due to Shadow IT and Remote Work

Shadow IT evolves in organizations when workers, teams, or entire departments
begin to improvise their work processes through unauthorized services or
practices that operate outside the oversight and control of IT. It may involve
something as seemingly harmless as storing work documents on a personal
laptop, or it could pose a catastrophic risk by transferring confidential
intellectual property or regulated private data via an unsecured personal file
sharing service. ... Although productivity is critical, the use of personal
cloud file services, ad hoc team network file shares, and personal email for
file transfer undermine governance and represent material risk from a
discovery, privacy, and noncompliance perspective. Without equipping your
employees with productivity tools that address governance requirements, they
pursue novel techniques without understanding the risks. Transferring
documents via email, Dropbox, or Google Drive may seem ingenious; in reality,
users may not understand the dangers posed by insufficient authentication or
auditing or the direct violation of data privacy requirements. What's more,
unmanaged deletion of work product may violate legal hold requirements.
How to Convince Stakeholders That Data Governance is Necessary
Often times, the data consumers don’t have an inventory of the data available
to them. The consumers don’t have business glossaries, data dictionaries and
data catalogs that house information about the data that will improve their
understanding of the data (and access to the metadata might be a problem even
if it is available). They don’t immediately know who to reach out to to
request access to the data (that they may not know exists in the first place).
And the rules associated with the data are not documented in resources that
are available to data consumers, thus putting all of this effort, post
hoop-jumping, at risk anyway. If you ask data consumers, casual data users,
and data scientists what causes delays and problems completing their normal
job, you can expect to get answers listed in the previous paragraph, that will
boggle your mind. At that point, you will begin to understand the often
mentioned 80/20 rule. This rule states that eighty percent of their time is
spent data wrangling and the other twenty percent is spent actually doing the
analysis, meaningful reporting and answering questions that is truly a part of
their job.
Studying an 'Invisible God' Hacker: Could You Stop 'Fxmsp'?
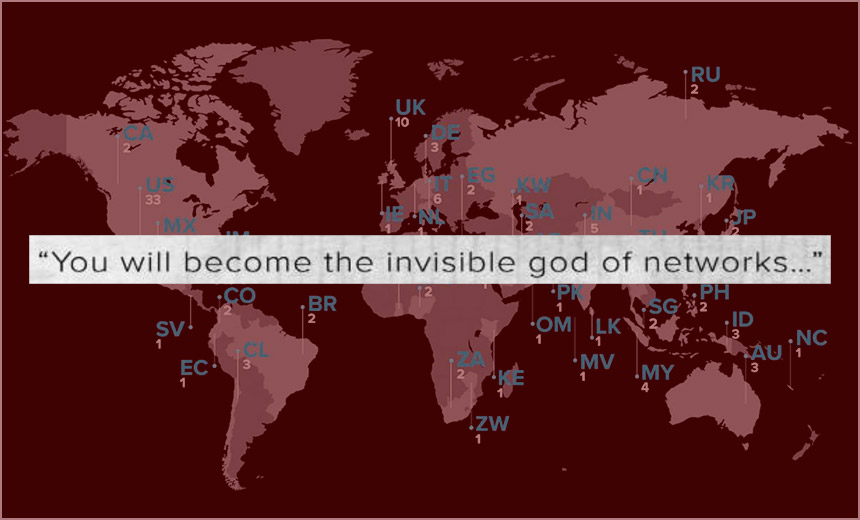
Experts say the group was extremely well-organized and used teams of
specialists, built a sophisticated botnet and sold remote access and
exfiltrated data in the course of perfecting the botnet to help monetize those
efforts. Or at least that was the group's MO until AdvIntel dropped a report
in May 2019 documenting Fxmsp's activities. Shining a light on the gang -
which relied in large part on advertising via publicly accessible cybercrime
forums - caused the group to disappear. "The Fxmsp hacking collective was
explicitly reliant on the publicity of their offers in the dark market
auctions and underground communities," Yelisey Boguslavskiy, CEO of AdvIntel,
tells me. After the report's release, he says Fxmsp disappeared from public
view, although it's not clear if the hacker with that handle might still be
operating privately. Study Fxmsp's historical operations, and a less-is-more
ethos emerges. "In most cases, Fxmsp uses a very simple, yet effective
approach: He scans a range of IP addresses for certain open ports to identify
open RDP ports, particularly 3389. Then, he carries out brute-force attacks on
the victim's server to guess the RDP password," Group-IB says in a recap.
4 common software maintenance models and when to use them

Quick-fix: In this model, you simply make a change without considering
efficiency, cost or possible future work. The quick-fix model fits emergency
maintenance only. Development policies should forbid the use of this model for
any other maintenance motives. Consider forming a special team dedicated to
emergency software maintenance. ... Iterative: Use this model for scheduled
maintenance or small-scale application modernization. The business
justification for changes should either already exist or be unnecessary. The
iterative model only gets the development team involved. The biggest risk here
is that it doesn't include business justifications -- the software team won't
know if larger changes are needed in the future. The iterative model treats
the application target as a known quantity. ... Reuse: Similar to the
iterative model, the reuse model includes the mandate to build, and then
reuse, software components. These components can work in multiple places or
applications. Some organizations equate this model to componentized iteration,
but that's an oversimplification; the goal here is to create reusable
components, which are then made available to all projects under all
maintenance models.
Newly discovered principle reveals how adversarial training can perform robust deep learning

Why do we have adversarial examples? Deep learning models consist of
large-scale neural networks with millions of parameters. Due to the inherent
complexity of these networks, one school of researchers believe in a “cursed”
result: deep learning models tend to fit the data in an overly complicated way
so that, for every training or testing example, there exist small
perturbations that change the network output drastically. This is illustrated
in Figure 2. In contrast, another school of researchers hold that the high
complexity of the network is a “blessing”: robustness against small
perturbations can only be achieved when high-complexity, non-convex neural
networks are used instead of traditional linear models. This is illustrated in
Figure 3. It remains unclear whether the high complexity of neural networks is
a “curse” or a “blessing” for the purpose of robust machine learning.
Nevertheless, both schools agree that adversarial examples are ubiquitous,
even for well-trained, well-generalizing neural networks.
AI Adoption – Data governance must take precedence
Obstacles are to be expected on the path to digital transformation, particularly
with unfamiliar entities in the mix. For AI adoption, the most prevalent
obstructions are: a company culture that doesn’t recognise a need for AI,
difficulties in identifying business use cases, a skills gap or difficulty
hiring and retaining staff and a lack of data or data quality issues. With this
broad spectrum of challenges, it is worth delving into a couple of them.
Firstly, it is interesting to note that an incompatible company culture mostly
affects those companies that are in the evaluation stage with AI. When
rephrased, perhaps it is obvious – a company with “mature” AI practices is 50
percent less likely to see no use for AI. By contrast, in a company where AI is
not yet an integrated business function, resistance is more likely. Secondly, AI
adopters are more likely to encounter data quality issues; by virtue of working
closely with data and requiring good data practice, they are more likely to
notice when errors and inconsistencies arise. Conversely, companies in the
evaluating stages of AI adoption may not be aware of the extent of any data
issues.
Quote for the day:
No comments:
Post a Comment