CIOs to Hit the Gas on Digital Business in 2021

"We have to go into the year 2021 absolutely hating the word average,"
Lovelock said. "As soon as you say 'the average is', the only thing you are
going to know for sure is that absolutely nobody is going to do that." Some
CIOs spent on devices to get their workforces equipped to work from home.
Others didn't. That's because executives looking to preserve cash in a crisis
cut back where they could, according to Lovelock. "In 2020 devices is one of
those first areas where you can save cash," he said. "When CIOs are faced with
cash flow restrictions like they were in March and April, the first thing you
save on or the first thing you defer is that deferable spending. That's mobile
phones, laptops, all those hard things you can buy and pay cash up front form.
You can sweat these assets." Meanwhile, categories that saw huge growth
included desktop as a service and cloud-based video conferencing, according to
Lovelock. These extremes in spending are part of what makes the 2020 recession
different from the Great Recession of 2009 and 2010. That earlier economic
downturn hit everyone across the board. "The decline in IT spending was more
evenly spread," Lovelock said.
Microsoft adds a new Linux: CBL-Mariner

Investing in a lightweight Linux such as CBL-Mariner makes a lot of sense,
considering Microsoft’s investments in container-based technologies. Cloud
economics require hosts to use as few resources as possible, allowing services
such as Azure to get a high utilization. At the same time, Kubernetes
containers need as little overhead as possible, allowing as many nodes per pod
as possible, and allowing new nodes to be launched as quickly as feasible. The
same is true of edge hardware, especially the next generation of edge nodes
intended for use with 5G networks. Here, like the public cloud, workloads are
what’s most important, shifting them and data closer to users. Microsoft uses
its growing estate of edge hardware as part of the Azure Content Delivery
Network outside its main Azure data centers, caching content from Azure Web
apps and from hosted video and file servers, with the aim of reducing latency
where possible. The Azure CDN is a key component of its Jamstack-based Azure
Static Websites service, hosting pages and JavaScript once published from
GitHub. In the past Red Hat’s CoreOS used to be the preferred host of Linux
containers, but its recent deprecation means that it’s no longer supported.
Anyone using it has had to find an alternative.
The future of programming languages: What to expect in this new Infrastructure as Code world

While we still use COBOL and other older programming languages, we also keep
inventing new languages, each with its own advantages and disadvantages. For
example, we have Rust and C++ for low-level, performance-sensitive systems
programming (with Rust adding the benefit of safety); Python and R for machine
learning, data manipulation, and more; and so on. Different tools for
different needs. But as we move into this Everything-as-Code world, why can't
we just keep using the same programming languages? After all, wouldn't it be
better to use the Ruby you know (with all its built-in tooling) rather than
starting from scratch? The answer is "no," as Graham Neray, cofounder and
CEO of oso, told me. Why? Because there is often a "mismatch between the
language and the purpose." These general-purpose, imperative languages "were
designed for people to build apps and scripts from the ground up, as opposed
to defining configurations, policies, etc." Further, mixing declarative
tools with an imperative language doesn't make things any easier to debug.
Consider Pulumi, which bills itself as an "open source infrastructure-as-code
SDK [that] enables you to create, deploy, and manage infrastructure on any
cloud, using your favorite languages." Sounds awesome, right?
Did Dremio Just Make Data Warehouses Obsolete?

The first new thing was caching data in the Apache Arrow format. The company
employs the creators of Arrow, the in-memory data format, and it uses Arrow
for in the computation engine. But Dremio was not using Arrow to accelerate
queries. Instead, it used the Apache Parquet file format to build caches.
However, because it’s an on-disk format, Parquet is much slower than Arrow.
... The second new thing that Dremio had to build was scale-out query
planning. This advance enabled the massive concurrency that the biggest
enterprise BI shops demand of their data warehouses. “Traditionally in the
world of big data, people had lots of nodes to support big data sets, but they
didn’t have lots of nodes to support concurrency,” Shiran says. “We now scale
out our query planning and execution separately.”By enabling an arbitrary
number of query planning coordinators in the Dremio cluster to go along with
an arbitrary number of query executors, the software can now support
deployments involving thousands of concurrent users. The third new element
Dremio is bringing to the data lake is runtime filtering. By being smart about
what database tables queries actually end up accessing during the course of
execution, Dremio can eliminate the need to perform massive table scans on
data that has no bearing on the results of the query.
What’s stopping job seekers from considering a career in cybersecurity?
The good news is that 71% of participants said that they view cybersecurity
professionals as smart, technically skilled individuals, 51% view them as
“good guys fighting cybercrime,” and 35% said cybersecurity professionals
“keep us safe, like police and firefighters.” The bad news is that even though
most view cybersecurity as a good career path, they don’t think it’s the right
path for them. In fact, only 8% of respondents have considered working in the
field at some point. “One of the most unexpected findings in the study is that
respondents from the youngest generation of workers – Generation Z (Zoomers),
which consist of those up to age 24 – have a less positive perception of
cybersecurity professionals than any other generation surveyed. This issue in
particular merits close attention by the cybersecurity industry at a time when
employers are struggling to overcome the talent gap,” (ISC)² noted. The
analysts posited that Generation Z’s perceptions of the cybersecurity field
are shaped negatively by social media exposure, as social media platforms
“tend to focus on the negative – arguments and venting.”
A Progressive Approach To Data Governance

For businesses, progressive data governance encourages fluid implementation
using scalable tools and programs. The first step is to identify both a
dataset and the relevant function. Using the same example as before, this
could be the data in a reporting system the accounts department uses. That
data could then be used during data literacy training hosted by a data
governance software tool. Sticking with data literacy, after establishing one
use case, an organization may decide to progress by expanding existing
programs to other departments and then moving on to another function of data
governance, such as identifying the roles and responsibilities of various data
users or developing an internal compliance program. Businesses can scale the
scope of the data they include in a governance program gradually, which gives
them the chance to learn important lessons along the way. As an organization
grows in confidence, it may widen its data scope and source it from other
departments and locations. Progressive data governance can be described as a
three-step process that incorporates the three C’s: catalog, collaborate and
comply. Cataloging data assets makes data discoverable.
The 4 Stages of Data Sophistication
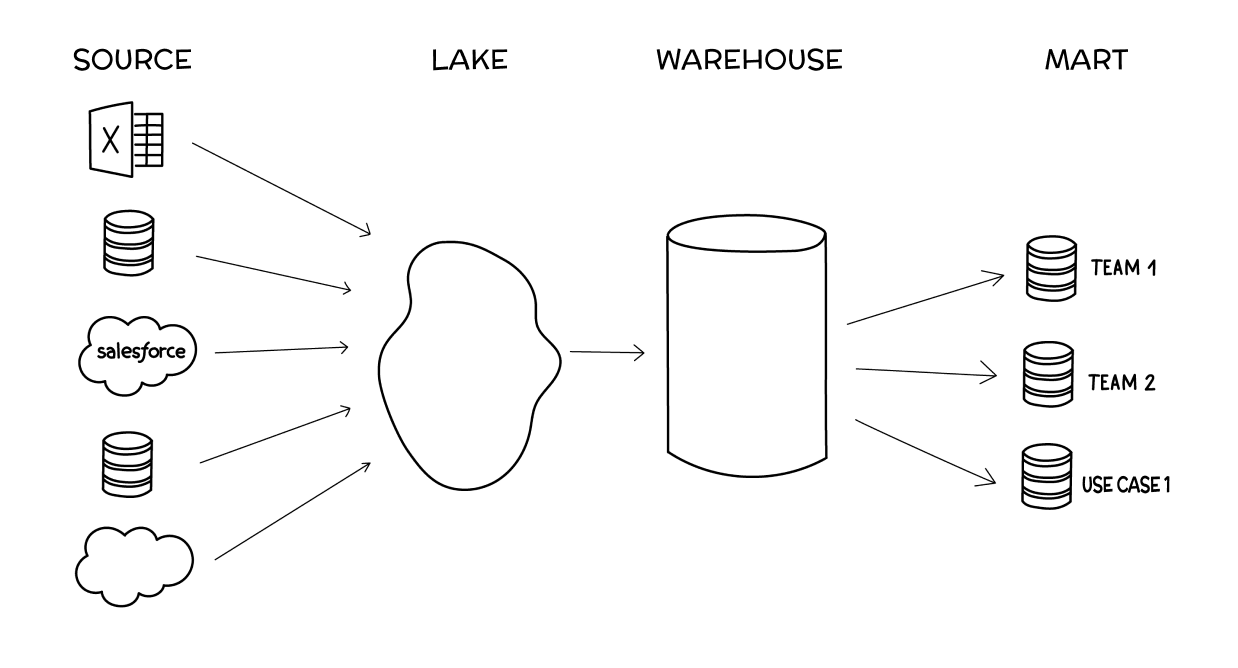
As you start to rely on more data sources, and more frequently need to blend
your data, you’ll want to build out a Data Lake—a spot for all of your data to
exist together in a unified, performant source. Especially when you need to
work with data from applications like Salesforce, Hubspot, Jira, and Zendesk,
you’ll want to create a single home for this data so you can access all of it
together and with a single SQL syntax, rather than many different APIs.
... In the Lake stage, as you bring in more people to work with the
data, you have to explain to them the oddities of each schema, what data is
where, and what special criteria you need to filter by in each of the tables
to get the proper results. This becomes a lot of work, and will leave you
frequently fighting integrity issues. Eventually, you’ll want to start
cleaning your data into a single, clean source of truth. ... When you have
clean data and a good BI product on top of it, you should start noticing that
many people within your company are able to answer their own questions, and
more and more people are getting involved. This is great news: your company is
getting increasingly informed, and the business and productivity results
should be showing.
Tales & Tips from the Trenches: In Defense of the Data Catalog

Most tools’ catalog interfaces provide many helpful features that together
provide the context behind the data. The interface has many visual features
that are certainly not vintage 1980’s. For example, many data catalog products
have data quality metrics built in, which show dashboards of an asset’s
quality on many of the “data quality dimensions.” These dashboards can be
visible to the user and can help them determine if the data is suitable for
their purposes. ... Data lineage is an extremely important feature of data
catalogs; the products vary in how they perform it and how deep the lineage
goes. One of my government sponsors felt data lineage was critical to their
understanding, especially the visual depiction of the lineage. The data
catalog’s data lineage diagrams tell the whole “back story” of the data: where
it comes from, where it’s going, how “good” it is (based on whatever quality
metrics are relevant), and some products even show the level of protection in
the lineage diagram. The interface is important because it displays a visual
diagram of the data flow along with descriptive metadata. See Figure 2 from
Informatica which shows column-to-column mappings as data flows from one
system to another, from source to warehouse or data lake. Notice that the
actual transformations can also be shown for a given column.
A Seven-Step Guide to API-First Integration

This approach drastically reduces project delays and cost overruns due to
miscommunication between frontend and backend teams leading to changes in APIs
and backend systems. After designing the APIs, it can take some time to get
the live backend systems up and running for the frontend teams to make API
calls and test the system. To overcome this issue, frontend teams can set up
dummy services, called mock backends, that mimic the designed APIs and return
dummy data. You can read more about it in this API mocking guide. There can be
instances where the requirements are vague or the development teams aren’t
sure about the right approach to design the APIs upfront. In that case, we can
design the API for a reduced scope and then implement it. We can do this for
several iterations, using multiple sprints until the required scope is
implemented. This way, we can identify a design flaw at an earlier stage and
minimize the impact on project timelines. ... In software engineering, the
façade design pattern is used to provide a more user-friendly interface for
its users, hiding the complexity of a system. The idea behind the API façade
is also the same; it provides a simplified API of its complex backend systems
to the application programmers.
Fintechs: transforming customer expectations and disrupting finance
With favourable tech regulation, massive mobile adoption, and shifting
expectations across the demographics, digital challengers are well positioned
to advance and evolve the personalised services they offer. Fintechs have the
advantage of starting from scratch, without having to build on legacy IT
infrastructure bureaucratic decision-making processes. They are lean and
innovative, led by entrepreneurs on a mission to change the world. Using the
latest technologies such as Artificial Intelligence (AI), Blockchain,
Biometrics Security and Cloud, the processes, compliance requirements,
policies and technology differ from conventional banks, providing lower
operating and resource costs. With these foundations, they are well-positioned
to pursue a highly customer-centric approach and rapid product innovation. By
contrast, for traditional banks it can be an arduous task to innovate and
reinvent. They are highly bureaucratic and slow-moving, with high-cost
structures and substantial legacy tech. These characteristics prevent them
from flexibly adapting to fast-changing consumer expectations. Service
providers unable to live up to the expectations of best-in-class digital
experiences will see high switching rates. As a result, providers are actively
investing in initiatives that boost customer experience in a bid to increase
long-term customer retention.
Quote for the day:
"Rarely have I seen a situation where doing less than the other guy is a good strategy." -- Jimmy Spithill
No comments:
Post a Comment