System brings deep learning to “internet of things” devices

To run that tiny neural network, a microcontroller also needs a lean inference
engine. A typical inference engine carries some dead weight — instructions for
tasks it may rarely run. The extra code poses no problem for a laptop or
smartphone, but it could easily overwhelm a microcontroller. “It doesn’t have
off-chip memory, and it doesn’t have a disk,” says Han. “Everything put
together is just one megabyte of flash, so we have to really carefully manage
such a small resource.” Cue TinyEngine. The researchers developed their
inference engine in conjunction with TinyNAS. TinyEngine generates the
essential code necessary to run TinyNAS’ customized neural network. Any
deadweight code is discarded, which cuts down on compile-time. “We keep only
what we need,” says Han. “And since we designed the neural network, we know
exactly what we need. That’s the advantage of system-algorithm codesign.” In
the group’s tests of TinyEngine, the size of the compiled binary code was
between 1.9 and five times smaller than comparable microcontroller inference
engines from Google and ARM. TinyEngine also contains innovations that reduce
runtime, including in-place depth-wise convolution, which cuts peak memory
usage nearly in half. After codesigning TinyNAS and TinyEngine, Han’s team put
MCUNet to the test.
Beyond the Database, and Beyond the Stream Processor: What's the Next Step for Data Management?

The breadth of database systems available today is staggering. Something like
Cassandra lets us store a huge amount of data for the amount of memory the
database is allocated; Elasticsearch is different, providing a rich,
interactive query model; Neo4j lets us query the relationship between
entities, not just the entities themselves; things like Oracle or PostgreSQL
are workhorse databases that can morph to different types of use case. Each of
these platforms has slightly different capabilities that make it more
appropriate to a certain use case but at a high level, they’re all similar. In
all cases, we ask a question and wait for an answer. This hints at an
important assumption all databases make: data is passive. It sits there in the
database, waiting for us to do something. This makes a lot of sense: the
database, as a piece of software, is a tool designed to help us humans —
whether it's you or me, a credit officer, or whoever — interact with
data. But if there's no user interface waiting, if there's no one
clicking buttons and expecting things to happen, does it have to be
synchronous? In a world where software is increasingly talking to other
software, the answer is: probably not.
Data warehousing workloads at data lake economics with lakehouse architecture
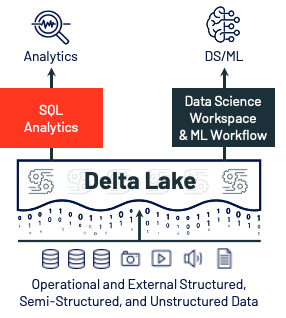
Data lakes in the cloud have high durability, low cost, and unbounded scale,
and they provide good support for the data science and machine learning use
cases that many enterprises prioritize today. But, all the traditional
analytics use cases still exist. Therefore, customers generally have, and pay
for, two copies of their data, and they spend a lot of time engineering
processes to keep them in sync. This has a knock-on effect of slowing down
decision making, because analysts and line-of-business teams only have access
to data that’s been sent to the data warehouse rather than the freshest, most
complete data in the data lake. ... The complexity from intertwined data
lakes and data warehouses is not desirable, and our customers have told us
that they want to be able to consolidate and simplify their data architecture.
Advanced analytics and machine learning on unstructured and large-scale data
are one of the most strategic priorities for enterprises today, – and the
growth of unstructured data is going to increase exponentially – therefore it
makes sense for customers to think about positioning their data lake as the
center of data infrastructure. However, for this to be achievable, the data
lake needs a way to adopt the strengths of data warehouses.
What to Learn to Become a Data Scientist in 2021

Apache Airflow, an open source workflow management tool, is rapidly being
adopted by many businesses for the management of ETL processes and machine
learning pipelines. Many large tech companies such as Google and Slack are
using it and Google even built their cloud composer tool on top of this
project. I am noticing Airflow being mentioned more and more often as a
desirable skill for data scientists on job adverts. As mentioned at the
beginning of this article I believe it will become more important for data
scientists to be able to build and manage their own data pipelines for
analytics and machine learning. The growing popularity of Airflow is likely to
continue at least in the short term, and as an open source tool, is definitely
something that every budding data scientist should at learn. ... Data science
code is traditionally messy, not always well tested and lacking in adherence
to styling conventions. This is fine for initial data exploration and quick
analysis but when it comes to putting machine learning models into production
then a data scientist will need to have a good understanding of software
engineering principles. If you are planning to work as a data scientist it is
likely that you will either be putting models into production yourself or at
least be involved heavily in the process.
WhatsApp Pay: Game changer with new risks
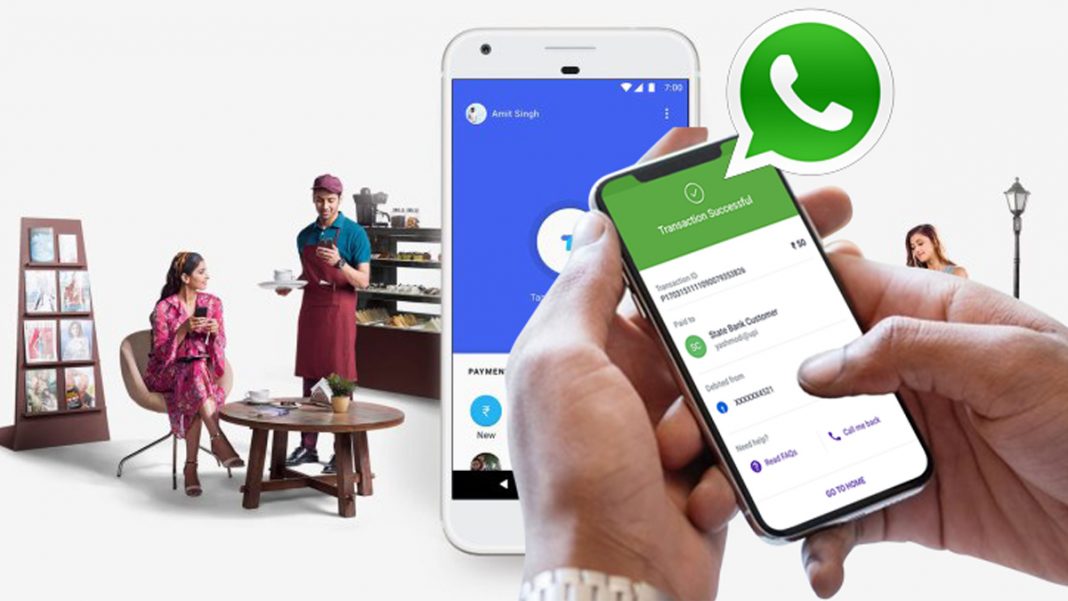
The payment instruction itself is a message to the partner bank, which then
triggers a normal UPI transaction from the customer’s designated UPI bank to
the destination partner bank through the National Payments Corporation of
India (NPCI). The destination partner bank forwards the payment to the
addressee’s default UPI bank registered with WhatsApp. A confirmation of
credit is also sent through WhatsApp and reaches the message box of the
recipient. It is possible that at either end, the WhatsApp partner bank may
not be the customer’s bank. Hence, there may be the involvement of four banks,
the NPCI and WhatsApp in completing the transaction. As far as the user is
concerned, the system is managed by WhatsApp and none of the other players is
visible. Though WhatsApp is not licensed to undertake UPI transactions
directly, it engages the services of its partner banks to initiate the
transaction. As these partner banks are not bankers for the customers, they
engage two more banks to assist them. Finally, NPCI acts as the agent of the
two banks through which the money actually passes through to the right bank.
Thus, there is a chain of principal agent transaction and the roles of the
customer, WhatsApp, banks, etc., need to be clarified.
New Circuit Compression Technique Could Deliver Real-World Quantum Computers Years Ahead of Schedule
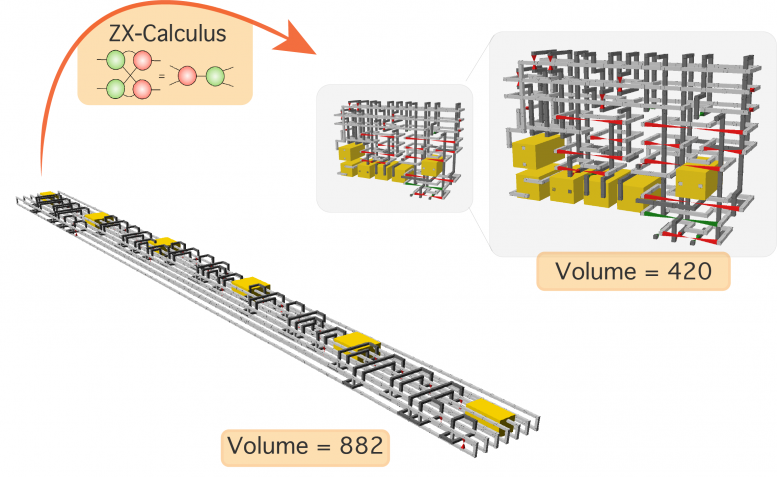
“By compressing quantum circuits, we could reduce the size of the quantum
computer and its runtime, which in turn lessens the requirement for error
protection,” said Michael Hanks, a researcher at NII and one of the authors of
a paper, published on November 11, 2020, in Physical Review X. Large-scale
quantum computer architectures depend on an error correction code to function
properly, the most commonly used of which is surface code and its variants.
The researchers focused on the circuit compression of one of these variants:
the 3D-topological code. This code behaves particularly well for distributed
quantum computer approaches and has wide applicability to different varieties
of hardware. In the 3D-topological code, quantum circuits look like
interlacing tubes or pipes, and are commonly called “braided circuits. The 3D
diagrams of braided circuits can be manipulated to compress and thus reduce
the volume they occupy. Until now, the challenge has been that such “pipe
manipulation” is performed in an ad-hoc fashion. Moreover, there have only
been partial rules for how to do this. “Previous compression approaches cannot
guarantee whether the resulting quantum circuit is correct,” said co-author
Marta Estarellas, a researcher at NII.
Microsoft Warns: A Strong Password Doesn’t Work, Neither Does Typical MFA

“Remember that all your attacker cares about is stealing passwords...That’s a
key difference between hypothetical and practical security.” — Microsoft’s
Alex Weinert In other words, the bad guys will do whatever is necessary to
steal your password and a strong password isn’t an obstacle when criminals
have a lot of time and a lot of tools at their disposal. ... MFA based on
phones, aka publicly switched telephone networks or PSTN, is not secure,
according to Weinert. (What is typical MFA? It’s when, for example, a bank
sends you a verification code via a text message.) “I believe they’re the
least secure of the MFA methods available today,” Weinert wrote in a blog.
“When SMS (texting) and voice protocols were developed, they were designed
without encryption...What this means is that signals can be intercepted by
anyone who can get access to the switching network or within the radio range
of a device,” Weinert wrote. Solution: use app-based authentication. For
example, Microsoft Authenticator or Google Authenticator. An app is safer
because it doesn’t rely on your carrier. The codes are in the app itself and
expire quickly.
Defining data protection standards could be a hot topic in state legislation in 2021

Once the immediacy of both the pandemic dissipates and the political heat
cools, cybersecurity issues will likely surface again in new or revived
legislation in many states, even if weaved throughout other related matters.
It’s difficult to separate cybersecurity per se from adjoining issues such as
data privacy, which has generally been the biggest topic to involve
cybersecurity issues at the state level over the past four years. “You really
don’t have this plethora of state cybersecurity laws that would be independent
of their privacy law brethren,” Tantleff said. According to the National
Conference of State Legislatures, at least 38 states, along with Washington,
DC, and Puerto Rico introduced or considered more than 280 bills or
resolutions that deal significantly with cybersecurity as of September 2020.
Setting aside privacy and some grid security funding issues, there are two
categories of cybersecurity legislative issues at the state level to watch
during 2021. The first and most important is spelling out more clearly what
organizations need to meet security and privacy regulations. The second is
whether states will pick up election security legislation left over from the
2020 sessions.
The Case for Combining Next Generation Tech with Human Oversight

Human error is the main cause of security breaches, wrong data interpretation,
mistaken insights, and a variety of other damning experiences the insights
industry has had to wade through ever since its conception. Zooming out to
take a wider look, human error is the cause of mistaken elections, aviation
accidents, cybersecurity issues, etc. but also scientific breakthroughs across
the world. While some mistakes yield true results, most have dangerous
consequences that could have been avoided if we were more careful. To err is
human, but in an industry where mistakes have real-world consequences, to err
is to potentially cost a business it’s life. If we stick with the artificial
intelligence and automation example, automated processes with next generation
technology are the most poignant example of humans trying to make up for their
mistakes and can help minimise human error at all stages ... The main benefit
of combining human oversight with this next generation technology, is that we
can catch and fix any bugs that arise before they harm the research process
and projects that rely on said technology. But we need to be wary that humans
cannot catch every mistake, and when one slips through that is when oversight
takes on a whole new, disappointing meaning.
Important Considerations for Pushing AI to the Edge

The decision on where to train and deploy AI models can be determined by
balancing considerations across six vectors: scalability, latency, autonomy,
bandwidth, security, and privacy. In terms of scalability, in a perfect world,
we’d just run all AI workloads in the cloud where compute is centralized and
readily scalable. However, the benefits of centralization must be balanced out
with the remaining factors that tend to drive decentralization. For example, if
you depend on edge AI for latency-critical use cases and for which autonomy is a
must, you would never make a decision to deploy a vehicle’s airbag from the
cloud when milliseconds matter, regardless of how fast and reliable your
broadband network may be under normal circumstances. As a general rule,
latency-critical applications will leverage edge AI close to the process,
running at the Smart and Constrained Device Edges as defined in the paper.
Meanwhile, latency-sensitive applications will often take advantage of higher
tiers at the Service Provider Edge and in the cloud because of the scale factor.
In terms of bandwidth consumption, the deployment location of AI solutions
spanning the User and Service Provider Edges will be based on a balance of the
cost of bandwidth, the capabilities of devices involved and the benefits of
centralization for scalability.
Quote for the day:
"If you want to do a few small things right, do them yourself. If you want to do great things and make a big impact, learn to delegate." -- John C. Maxwell
No comments:
Post a Comment