The Role of Relays In Big Data Integration
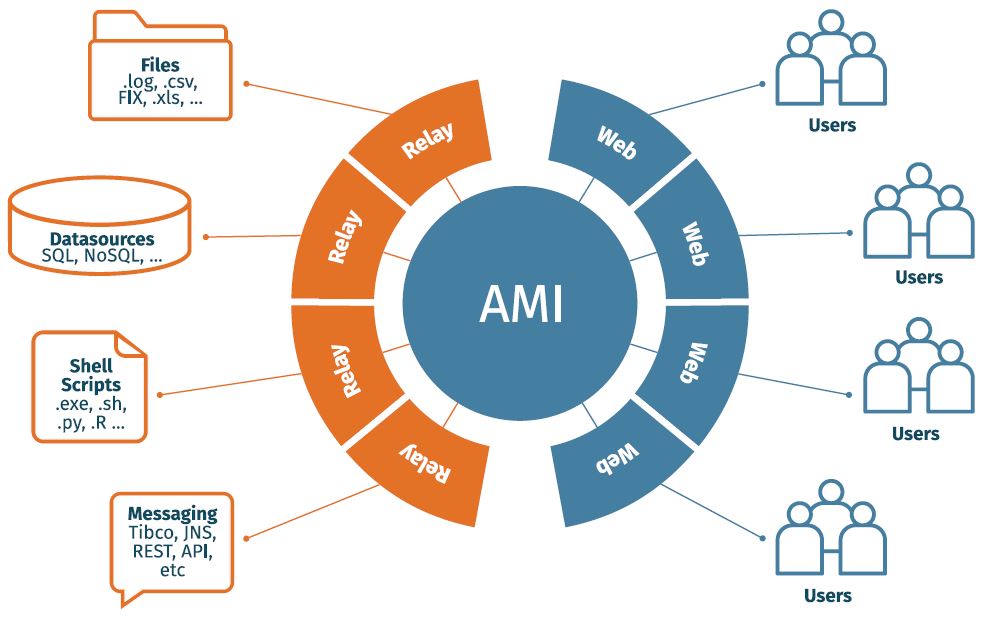
The very nature of big data integration requires an organization to become
more flexible in some ways; particularly when gathering input and metrics from
such varied sources as mobile apps, browser heuristics, A / V input, software
logs, and more. The number of different methodologies, protocols, and formats
that your organization needs to ingest while complying with both internal and
government-mandated standards can be staggering. ... What if, instead of just
allowing all of that data to flow in from dozens of information silos, you
introduced a set of intelligent buffers? Imagine that each of these buffers
was purpose-built for the kind of input that you needed to receive at any
given time: Shell scripts, REST APIs, federated DB’s, hashed log files, and
the like. Let’s call these intelligent buffers what they really are: Relays.
They ingest SSL encrypted data, send out additional queries as needed, and
provide fault-tolerant data access according to ACL’s specific to the team and
server-side apps managing that dataset. If you were to set up such a
distributed relay architecture to deal with your big data integration chain,
it might look something like this
Malware Hidden in Encrypted Traffic Surges Amid Pandemic
Ransomware attacks delivered via SSL/TLS channels soared 500% between March
and September, with a plurality of the attacks (40.5%) targeted at
telecommunication and technology companies. Healthcare organizations were
targeted more so than entities in other verticals and accounted for 1.6
billion, or over 25%, of all SSL-based attacks Zscaler blocked this year.
Finance and insurance companies clocked in next with 1.2 billion or 18% of
attacks blocked, and manufacturing organizations were the third-most targeted,
with some 1.1 billion attacks directed against them. Deepen Desai, CISO and
vice president of security research at Zscaler, says the trend shows why
security groups need to be wary about encrypted traffic traversing their
networks. While many organizations routinely encrypt traffic as part of their
security best practices, fewer are inspecting it for threats, he says. "Most
people assume that encrypted traffic means safe traffic, but that is
unfortunately not the case," Desai says. "That false sense of security can
create risk when organizations allow encrypted traffic to go uninspected."
Shadow IT: The Risks and Benefits That Come With It

Covid-19-induced acceleration of remote work has led to employees being
somewhat lax about cybersecurity. Shadow IT might make business operations
easier – and many companies certainly have been needing that in the last few
months – but from the cybersecurity point of view, it also brings about more
risks. If your IT team doesn’t know about an app or a cloud system that you’re
using in your work, they can’t be responsible for any consequences of such
usage. This includes those impacting the infrastructure of the entire
organization. The responsibility falls on you to ensure the security of your
company’s data whilst using the shadow IT app. Otherwise, your entire
organization is at risk. It’s also easy to lose your data if your Shadow IT
systems don’t back stuff up. If they’re your only method of storage and
something goes wrong, you could potentially lose all your valuable data. If
you work in government, healthcare, banking, or another heavily regulated
center, chances are that you have local normative acts regulating your IT
usage. It’s likely that your internal systems wouldn’t even allow you to
access certain websites or apps.
Refactoring Java, Part 2: Stabilizing your legacy code and technical debt
Technical debt is code with problems that can be improved with refactoring.
The technical debt metaphor is that it’s like monetary debt. When you borrow
money to purchase something, you must pay back more money than you borrowed;
that is, you pay back the original sum and interest. When someone writes
low-quality code or writes code without first writing automated tests, the
organization incurs technical debt, and someone has to pay interest, at some
point, for the debt that’s due. The organization’s interest payments aren’t
necessarily in money. The biggest cost is the loss of technical agility, since
you can’t update or otherwise change the behavior of the software as quickly
as needed. And less technical agility means the organization has less business
agility: The organization can’t meet stakeholders’ needs at the desired speed.
Therefore, the goal is to refactor debt-ridden code. You’re taking the time to
fix the code to improve technical and business agility. Now let’s start
playing with the Gilded Rose kata’s code and see how to stabilize the code,
while preparing to add functionality quickly in an agile way. One huge main
problem with legacy code is that someone else wrote it.
Interactive Imaging Technologies in the Wolfram Mathematica
A lot of mathematical problems that can be solved using computer algebra
systems are constantly expanding. Considerable efforts of researchers are
directed to the development of algorithms for calculating topological
invariants of manifolds, knots, calculating topological invariants of
manifolds of knots of algebraic curves, cohomology of various mathematical
objects, arithmetic invariants of rings of integer elements in fields of
algebraic numbers. Another example of modern research is quantum
algorithms, which sometimes have polynomial complexity, while existing
classical algorithms have exponential complexity. Computer algebra is
represented by theory, technology, software. The applied results include the
developed algorithms and software for solving problems using a computer, in
which the initial data and results are in the form of mathematical
expressions, formulas. The main product of computer algebra has become
computer algebra software systems. There are a lot of systems in this
category, many publications are devoted to them, systematic updates are
published with the presentation of the capabilities of new versions.
EU to introduce data-sharing measures with US in weeks

Companies will be able to use the assessment to decide whether they want to
use a data transfer mechanism, and whether they need to introduce additional
safeguards, such as encryption, to mitigate any data protection risks, said
Gencarelli. The EC is expected to offer companies “non-exhaustive” and
“non-prescriptive” guidance on the factors they should take into account.
This includes the security of computer systems used, whether data is
encrypted and how organisations will respond to requests from the US or
other government law enforcement agencies for access to personal data on EU
citizens. Gencarelli said relevant questions would include: What do you do
as a company when you receive an access request? How do you review it? When
do you challenge it – if, of course, you have grounds to challenge it?
Companies may also need to assess whether they can use data minimisation
principles to ensure that any data on EU citizens they hand over in response
to a legitimate request by a government is compliant with EU privacy
principles. The guidelines, which will be open for public consultation, will
draw on the experience of companies that have developed best practices for
SCCs and of civil society organisations.
Unlock the Power of Omnichannel Retail at the Edge

The Edge exists wherever the digital world and physical world intersect, and
data is securely collected, generated, and processed to create new value.
According to Gartner, by 2025, 75 percent6 of data will be processed at the
Edge. For retailers, Edge technology means real-time data collection,
analytics and automated responses where they matter most — on the shop
floor, be that physical or virtual. And for today’s retailers, it’s what
happens when Edge computing is combined with Computer Vision and AI that is
most powerful and exciting, as it creates the many opportunities of
omnichannel shopping. With Computer Vision, retailers enter a world of
powerful sensor-enabled cameras that can see much more than the human eye.
Combined with Edge analytics and AI, Computer Vision can enable retailers to
monitor, interpret, and act in real-time across all areas of the retail
environment. This type of vision has obvious implications for security, but
for retailers it also opens up huge possibilities in understanding shopping
behavior and implementing rapid responses. For example, understanding how
customers flow through the store, and at what times of the day, can allow
the retailer to put more important items directly in their paths to be more
visible.
4 Methods to Scale Automation Effectively

An essential element of the automation toolkit is the value-determination
framework, which guides the identification and prioritization of automation
opportunity decisions. However, many frameworks apply such a heavy weighting
to cost reduction that other value dimensions are rendered meaningless.
Evaluate impacts beyond savings to capture other manifestations of value;
this will expand the universe of automation opportunities and appeal to more
potential internal consumers. Benefits such as improving quality, reducing
errors, enhancing speed of execution, liberating capacity to work on more
strategic efforts, and enabling scalability should be appropriately
considered, incorporated, and weighted in your prioritization framework.
Keep in mind that where automation drives the greatest value changes over
time depending on both evolving organizational priorities and how extensive
the reach of the automation program has been. Periodically reevaluate the
value dimensions of your framework and their relative weightings to
determine whether any changes are merited. Typically, nascent automation
programs take an “inside-out” approach to developing capability, where the
COE is established first and federation is built over time as ownership and
participation extends radially out to business functions and/or IT.
Digital transformation: 5 ways to balance creativity and productivity
One of the biggest challenges is how to ensure that creative thinking is an
integral part of your program planning and development. Creativity is fueled
by knowledge and experience. It’s therefore important to make time for
learning, whether that’s through research, reading the latest trade
publication, listening to a podcast, attending a (virtual) event, or
networking with colleagues. It’s all too easy to dismiss this as a distraction
and to think “I haven’t got time for that” because you can’t see an immediate
output. But making time to expand your horizons will do wonders for your
creative thinking. ... However, the one thing we initially struggled with was
how to keep being innovative. We were used to being together in the same room,
bouncing ideas off one another, and brainstorms via video call just didn’t
have the same impact. However, by applying some simple techniques such as
interactive whiteboards and prototyping through demos on video platforms,
we’ve managed to restore our creative energy. To make it through the pandemic,
companies have had to think outside the box, either by looking at alternative
revenue streams or adapting their existing business model. Businesses have
proved their ability to make decisions, diversify at speed, and be
innovative.
Google Open-Sources Fast Attention Module Performer
The Transformer neural-network architecture is a common choice for sequence
learning, especially in the natural-language processing (NLP) domain. It has
several advantages over previous architectures, such as recurrent
neural-networks (RNN); in particular, the self-attention mechanism that allows
the network to "remember" previous items in the sequence can be executed in
parallel on the entire sequence, which speeds up training and inference.
However, since self-attention can link each item in the sequence to every other
item, the computational and memory complexity of self-attention is O(N2)O(N2),
where N is the maximum sequence length that can be processed. This puts a
practical limit on sequence length of around 1,024 items, due to the memory
constraints of GPUs. The original Transformer attention mechanism is implemented
by a matrix of size NxN, followed by a softmax operation; the rows and columns
represent queries and keys, respectively. The attention matrix is multiplied by
the input sequence to output a set of similarity values. Performer's FAVOR+
algorithm decomposes the matrix into two matrices which contain "random
features": random non-linear functions of the queries and keys.
Quote for the day:
"Don't let your future successes be prisoners of your past failure, shape the future you want." -- Gordon Tredgold
No comments:
Post a Comment