Optimizing Multi-Cloud, Cross-DC Web Apps and Sites

Latency, payload, caching and rendering are the key measures when evaluating website performance. Each round trip is subject to the connection latency. From the time the webpage is requested by the user to the time the resources on that webpage are downloaded in the browser is directly related to the weight of the page and its resources. The larger the total content size, the more time it will take to download everything needed for a page to become functional for the user. Using caching and default caching headers may reduce the latency since less content is downloaded and it may result in fewer round trips to fetch the resources, although sometimes round trips may be to validate that the content in the cache is not stale. Browsers need to render the HTML page and resources served to them. Client-side work may cause poor rendering at the browser and a degraded user experience, for example, some blocking calls (say 3rd party ads) or improper rendering of page resources can delay page load time and impact a user experience.
Lessons from the UK Government's Digital Transformation Journey
So many lessons! Some of my colleagues set out to document the higher level lessons. The result was an entire book -- Digital Transformation at Scale: Why the Strategy Is Delivery -- but there’s a huge amount more that couldn’t be included there. But top of the list is the importance of remaining focused on your purpose and your users’ needs. As technologists and agilists we can too easily be drawn into improving technology or simplifying processes without stepping back and asking why we have those things in the first place, or if the change we’re making is the right one. I’ve talked to a lot of teams in large organisations who have taken all the right steps in moving to agile but are still having trouble motivating their teams, and the missing piece is almost always being exposed directly to your users. Whether they’re end customers, or internal users, there’s nothing like seeing people use your products to motivate the team to make them better.

MissingLink.ai has launched this week to streamline and automate the entire deep learning life cycle for data scientists and engineers. “Work on MissingLink began in 2016, when my colleagues Shay Erlichmen [CTO], Rahav Lussato [lead developer], and I set out to solve a problem we experienced as software engineers. While working on deep learning projects at our previous company, we realized we were spending too much time managing the sheer volume of data we were collecting and analyzing, and too little time learning from it,” Yosi Taguri, CEO of MissingLink, wrote in a post. “We also realized we weren’t alone. As engineers, we knew there must be a more efficient solution, so we decided to build it. Around that time, we were joined by Joe Salomon [VP of product], and MissingLink was born.” The team decided to focus on machine learning and deep learning because of the potential to “impact our lives in found ways.” Machine learning has already been used for detecting diseases, in autonomous vehicles and in public safety situations, according to the company.
Big data architecture: Navigating the complexity

First, there are the many different engines you might choose to run with your big data. You could choose Splunk to analyze log files, or Hadoop for large file batch processing, or Spark for data stream processing. Each of these specialized big data engines requires its own data universe, and ultimately, the data from these universes must come together—which is where the DBA is called in to do the stitching. But that's not all. Organizations are now mixing and matching on-premise and cloud-based big data-processing and data storage. In may cases, they are using multiple cloud vendors as well. Once again, data and intelligence from these various repositories must be blended together at some point, as the business requires. "This is a system integration problem that vendors need to help their clients solve," said Anoop Dawar, SVP of product management and marketing for MapR, a converged data platform for big data . "You have to not only be able to provide a platform for all of the different big data processing engines and data stores that are out there, but you must also be able to rapidly provide access to new big data processing engines and data stores as they emerge."
Key Difference Between The Cloud And The Data Center
Whilst the purpose of both is the same; storage, management, and maintenance of data – there is an evident architectural difference between both. So the first key difference is that a data center is land-based, in-house and has a physical setup with a physical presence of IT professionals working together as a team. On the other hand, a cloud is more like a virtual, physically non-existent store that is dependent on the internet and is accessible only by the user over the internet. There is a notable difference between the security that both offer. Of course, understandably cloud computing is less secure than data centers as the latter is an in-house setup and is liable to protect your security. On the contrary, cloud computing is internet-based which puts you at an increased risk of data leak and privacy invasion threats. Moreover, you are responsible for your own security with cloud computing because the third-party operator of the cloud is not liable for your data.
5 Easy Ways To Determine If Your Company Needs Blockchain

The purest form of blockchain is in tracking and authenticating a digital asset (music, movies, digital wallets, education certifications, mortgage contracts, and so on) with digital transactions logged against it. Blockchains can also track and authenticate physical assets (gold, organic food, artwork, manufactured parts, and such), though those assets can require checkpoints considered “off-chain.” In such cases, you’ll need trusted sources in your business network to audit and authenticate the physical asset, which can be tricky. Consider a notorious example from the aerospace industry. Some argue that well before the Challenger space shuttle disaster in 1986, some parties knew that the spacecraft’s O-ring seals contained a flaw, but this design and manufacturing problem wasn’t addressed properly. What if an aerospace industry blockchain was tracking the origin, specification, materials, and testing of that part and any known problems? Only once the integrity of that part and required tests had been confirmed by many trusted participants could the part be used.
Axon Conference Panel: Why Should We Use Microservices?
For Schrijver, it’s all about scalability. In terms of teams it’s the ability to work with multiple teams on one product. In terms of operations it’s the ability to independently scale different parts of a system. He thinks that if you build a microservices system the right way you can have almost unlimited horizontal scalability. Buijze pointed out that technically it doesn’t matter whether we work with monoliths or microservices; in theory you can scale out a monolith just as well as microservices. What microservices gives us is a strong and explicit boundary to every service. Although the architects draw limits for communication between components, we as developers are good at ignoring them. If it’s technically possible to directly communicate with another component we will do that, ignoring any rules the architects have set up. Keeping those boundaries intact is much easier when they are explicit and even more so if a component is managed by another team.
The rise of open source use across state and local government

A simple solution for agencies looking to defend against open source vulnerabilities is to turn to enterprise open source providers. Enterprise-ready solutions undergo scrutinizing tests to ensure that any defect is detected, prevented, or addressed in a timely manner, thereby mitigating an agency’s risk. Even further, enterprise solutions protect government networks from these risks throughout the product lifecycle by ensuring the code is up-to-date, secure, and functioning as expected. Investing in future-oriented, enterprise open source solutions can also help lower the total cost of ownership. This is possible because agencies can sidestep the costly and painful vendor lock-in that comes with proprietary software. Instead, enterprise open source enables users to utilize software that is platform agnostic and enables the agency to make the hardware, operating system, and environment decisions that are optimal for their requirements and mission. At the end of the day, an enterprise open source solution provides government users with the best of both worlds.
Crowdstrike CTO on securing the endpoint and responding to a breach
The first was that a modern security platform had to be built as a native-cloud solution. The cloud was critical not just for ease of management and rapid agent rollouts, but also for protection of off-premise assets and workloads deployed in public and hybrid clouds. The cloud would also be used to dramatically reduce performance impact that an endpoint agent would have on a system as heavy processing work would be offloaded to an elastically scalable cloud compute. Finally, the cloud could leverage the power of crowdsourcing – collection of trillions of security-related events from endpoint agents deployed all over the world to learn from every adversary action and taking away their ability to reuse tradecraft as they launch attacks against new victims. The second principle was to leverage machine learning/artificial intelligence to predictively identify new threats by training algorithms on the largest dataset in the security industry – over a trillion events collected every single week by CrowdStrike Falcon agents protecting organisations in 176 countries.
What is Blockchain Technology? A Step-by-Step Guide For Beginners
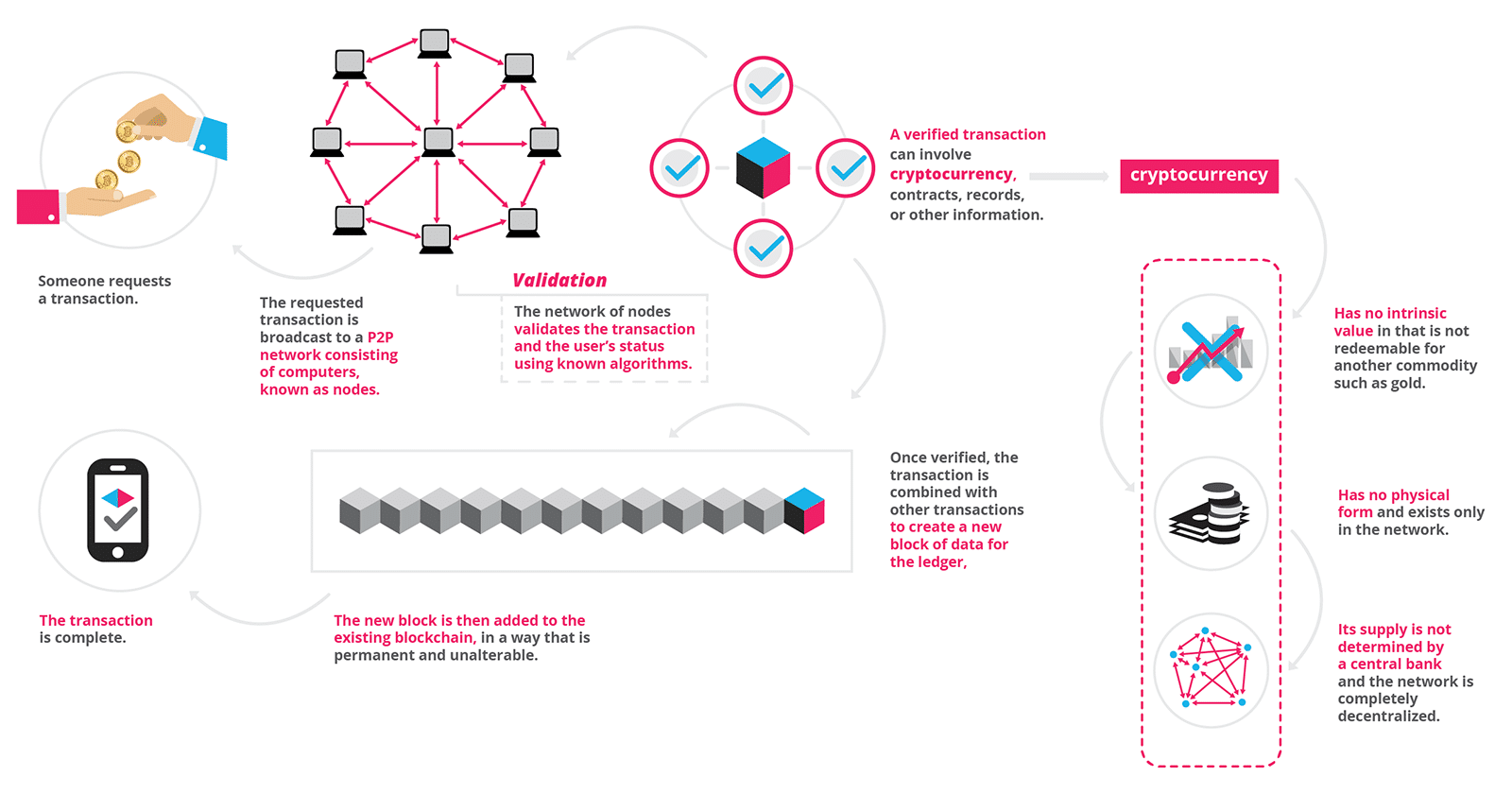
Information held on a blockchain exists as a shared — and continually reconciled — database. This is a way of using the network that has obvious benefits. The blockchain database isn’t stored in any single location, meaning the records it keeps are truly public and easily verifiable. No centralized version of this information exists for a hacker to corrupt. Hosted by millions of computers simultaneously, its data is accessible to anyone on the internet. ... As revolutionary as it sounds, Blockchain truly is a mechanism to bring everyone to the highest degree of accountability. No more missed transactions, human or machine errors, or even an exchange that was not done with the consent of the parties involved. Above anything else, the most critical area where Blockchain helps is to guarantee the validity of a transaction by recording it not only on a main register but a connected distributed system of registers, all of which are connected through a secure validation mechanism.
Quote for the day:
"To have long term success as a coach or in any position of leadership, you have to be obsessed in some way." -- Pat Riley
No comments:
Post a Comment