Taking the pulse of machine learning adoption

The least surprising part of the survey is how respondents categorized their organizations' experience with ML: roughly half are in beginners in exploration phase who are just starting to investigate ML. The remainder -- early adopters with roughly 2 years of ML experience and "sophisticated" organizations with at least 5 years or more accounted for 36% and 15%, respectively. Our take is that if you blew out the survey to a totally blind sample taken from the general population, those numbers would drop considerably. Nonetheless, we'd surmise that these organizations, by virtue of their budgeting for IT/data or analytics-related learning are among those who will be spending the lion's share on IT -- and AI and ML in particular. In the interest of full disclosure, these results are of more than passing interest to us because of the primary research that we're conducting for the day job -- Ovum research jointly sponsored with Dataiku on the people and process side of AI, where we'll be presenting the results at the Strataconference next month.

How can social media outlets better tune their algorithms? It's a challenging technical problem, but it would also require a willingness to forgo ad revenue that plays on the back of intentionally manipulative or offensive content. There are also battles to be waged against crafty legitimate users who post edgy content that constantly skirts the boundaries of terms of service. As an example, Twitter struggled internally with how to handle right-wing commentator Alex Jones. But the decisions over Jones and lesser firebrands shouldn't be difficult. Neither Twitter nor Facebook or any other company would allow a speech in their corporate headquarters that, for example, employs racist dog whistles or subtly encourages aggression against refugees. And online, their policies should be no different. Such censorship would raise ire, of course. Just a handful of social media outlets have become the main channels for distributing information. Drawing up guidelines for acceptable content isn't difficult, but it is hard to evenly apply them.
For CIOs and CISOs security decision is no less than a dilemma
Just imagine the scene through the eyes of any CIO, CISO or CSO and most would agree it’s certainly a big dilemma – if not done in a right way then it could detrimental in its own way. “Exactly, of course we know that is the dilemma and what should be right the (security) approach – is what we are saying,” said Bhaskar Bakthavatsalu, Managing Director – Check Point, a cybersecurity solutions company, which is known for firewall technology. More than a thousand security vendors to deal, a wide security technology products and solutions to choose, putting security controls to match unique needs in the organisation and business domains, and adhering to government and industry regulations plus distinctive business demands. ... On top of that, there are these continuous cyber threats and unknown sophisticated virus and malware attacks emerging almost every day from anonymous sources and cybercriminals operating from untraceable locations on the earth.
Most UK businesses are not insured against security breaches and data loss, says study

“Third party risk is an interesting topic for cyber insurance underwriting that will certainly evolve as this space matures. Currently cyber insurance underwriting is more focused on the entities themselves being insured, however underwriting takes numerous variables into consideration, and the third-party risk will certainly be a factor for the underwriting process, in particular for larger enterprises.” “Security ratings is one of many variables utilised in the underwriting process. Things such as the company itself, the overall industry risk, responses from questionnaires issued, etc. are all factored in, in addition to security ratings. Each area is weighted accordingly to the overall risk being assessed. As the security ratings industry matures, more weight will certainly be lent to the information security ratings provides. When it comes to SMBs, insurers are less focused on assessing the individual risk of each individual company and more on managing the overall risk of the portfolio”
Difference Between UX and UI Design
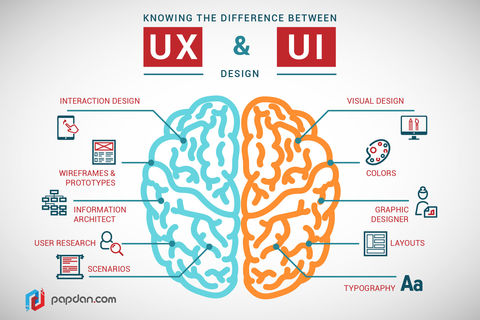
Years ago, we had doctors - just doctors. They practiced every kind of medicine, had small offices, and even made house calls. We called them general practitioners. As the field of medicine grew and research and knowledge expanded, doctors began to specialize. Now we go to one doctor for ear, nose and throat issues; we go to another for skin issues; we go to others for issues with any of our major internal organs. ... So, now we have UX and UI designers, each with their specific facets of web design. These terms are often used interchangeagably, however, and there is some disagreement as to what exactly each specialty entails. So here is a basic definition of each. While UX designers do a lot in the area of how users interact with products and services and designing that flow of interaction, but they do not focus on marketing or sales. They do, however, work with marketing departments, in, for example, the sequence in which products and services may be presented.
Understanding Type I and Type II Errors
In statistical test theory, the notion of statistical error is an integral part of hypothesis testing. The statistical test requires an unambiguous statement of anull hypothesis, for example, "this person is healthy", "this accused person is not guilty" or "this product is not broken". The result of the test of the null hypothesis may be positive or may be negative. If the result of the test corresponds with reality, then a correct decision has been made. However, if the result of the test does not correspond with reality, then two types of error are distinguished: type I errorand type II error. ... Type I and type II errors are highly depend upon the language or positioning of the null hypothesis. Changing the positioning of the null hypothesis can cause type I and type II errors to switch roles. It’s hard to create a blanket statement that a type I error is worse than a type II error, or vice versa. The severity of the type I and type II errors can only be judged in context of the null hypothesis, which should be thoughtfully worded to ensure that we’re running the right test.
Data breach reports see 75% increase in last two years

“Reporting data breaches wasn’t mandatory for most organisations before the GDPR came into force,” explained Andrew Beckett, “so while the data is revealing, it only gives a snapshot into the true picture of breaches suffered by organisations in the UK. “The recent rise in the number of reports is probably due to organisations’ gearing up for the GDPR as much as an increase in incidents. Now that the regulation is in force, we would expect to see a significant surge in the number of incidents reported as the GDPR imposes a duty on all organisations to report certain types of personal data breach. “We would also expect to see an increase in the value of penalties issued as the maximum possible fine has risen from £500,000 to €20 million or 4 per cent of annual turnover, whichever is higher. The ultimate impact is that businesses face not only a much greater financial risk around personal data, but also a heightened reputational risk.”
5 Lessons I Have Learned From Data Science In Real Working Experience
Be like a Detective. Carry out your investigation with laser focus on details. This is particularly important during the process of data cleaning and transformation. Data in real life is messy and you must have the capability to pick up signals from the ocean of noise before you get overwhelmed. Therefore, having a detail-oriented mindset and workflow is of paramount importance to be successful in Data Science. Without a meticulous mindset or a well-structured workflow, you might lose your direction in the midst of diving into exploring your data. You may be diligently performing Exploratory Data Analysis (EDA) for some time but still may not have reached any insights. Or you may be consistently training your model with different parameters to hopefully see some improvement. Or perhaps, you may be celebrating the completion of arduous data cleaning process, when the data could in fact be not clean enough to feed to your model.
Is It Time to Replace Your Network's Annual Check-Up?

The evolution toward a more holistic, personalized health maintenance program will create an explosion of data. In fact, the amount of worldwide health care data is expected to grow to 25,000 petabytes in 2020. This will put more pressure on our communication networks. As a result, it's imperative to ensure the "health" of the data network is robust and that sharing patient information amongst all stakeholders is possible. Much like the annual physical health checkup, the traditional approach of many network managers was to conduct infrequent network performance checkups and to take action only when there is an unexpected outage or issue. In today's on-demand world where users expect their communications to be available 24/7, this is no longer acceptable. If network managers look only for alarms, they see just a fraction of the information available at any given moment and lose the ability see the complete network health picture. This can restrict how much preventive action can be taken to avoid network disruption.
The pressure's on: digital transformation seen as a make-or-break proposition for IT managers
As with many technology trends over the years, many executives rush to buy the shiny new gadgets, expecting them to work miracles on their calcified, customer-repelling processes. Digital transformation -- and all the technologies associated with it -- is only the latest example. Companies attempt to put digital approaches in place, thinking they can do things cheaper, without funding the essential background work, such as data integration. But the competitive pressure is intense: 85 percent said disruption in their industry has accelerated over the past 12 months. Thirty-five percent say the primary driver for digital transformation is advances made by competitors, 23 percent changes in regulation, and 20 percent pressure from customers - "meaning digital transformation is mostly being driven by reactive needs, instead of proactive ideas," the survey's authors conclude.
Quote for the day:
"If You Don't Like Your Situation, Take Actions To Change It, Hope Is Not A Strategy." -- Gordon TredGold
No comments:
Post a Comment