12 Frequently Asked Questions on Deep Learning

Feature engineering is a process of putting domain knowledge into the creation of feature extractors to reduce the complexity of the data and make patterns more visible to learning algorithms to work. This process is difficult and expensive in terms of time and expertise. In Machine learning, most of the applied features need to be identified by an expert and then hand-coded as per the domain and data type. For example, features can be pixel values, shape, textures, position and orientation. The performance of most of the Machine Learning algorithm depends on how accurately the features are identified and extracted. Deep learning algorithms try to learn high-level features from data. This is a very distinctive part of Deep Learning and a major step ahead of traditional Machine Learning. Therefore, deep learning reduces the task of developing new feature extractor for every problem. Like, Convolutional NN will try to learn low-level features such as edges and lines in early layers then parts of faces of people and then high-level representation of a face.
No CS degree? For skilled developers, 75% of hiring managers don't care

Strong work experience is the most important qualification that recruiters and hiring managers look for when filling tech positions, the report found. However, resume-bolstering factors like degree, prestige, and skill keywords are not accurate predictors of future job success, according to the report. Instead, hiring managers and recruiters are looking to indicators that demonstrate ability, such as previous work experience, years of work, and personal projects, which get closer at measuring a candidate's skills. ... Hiring managers' top three measures of success in recruiting were quality of candidate, future performance success, and employee retention, the report found. Failing to align on skills and expectations for candidates are two of the top hurdles facing hiring managers when it comes to working with recruiters, the report found. To solve this problem, recruiters should regularly check in with hiring managers to understand the nuances of the technical skills hiring managers are looking for in each open role. For example, what are the crucial must-have skills for a fullstack developer versus a back-end developer? This can help narrow down the pool of qualified candidates.
Doctors are using AI to see how diseases change our cells

This model can predict where these organelles will be found in any new cell, so long as it’s provided with an image from a microscope. The researchers also used AI to create a probabilistic model that takes its best guess at where one might expect to find those same organelles if provided with a cell’s size and shape, along with the location of its nucleus. These models are useful for doctors and scientists because they provide a close-up look at the effects of cancer and other diseases on individual cells. By feeding the AI with data and images of cancer cells, they can get a more complete picture of how the cell, and its individual components, are affected. And that can indicate how doctors can help each patient with treatment tailored to their disease. The team from the Allen Institute hopes their tools can help democratize medical research, improving healthcare in underserved areas. So the researchers are working to improve them, creating more complete models, according to NPR. They hope to have a broader database, full of models of more cells, available over the next few months.
Everything you need to know about the new general data protection regulations

GDPR applies to any organisation operating within the EU, as well as any organisations outside of the EU which offer goods or services to customers or businesses in the EU. That ultimately means that almost every major corporation in the world will need to be ready when GDPR comes into effect, and must start working on their GDPR compliance strategy. There are two different types of data-handlers the legislation applies to: 'processors' and 'controllers'. The definitions of each are laid out in Article 4 of the General Data Protection Regulation. A controller is "person, public authority, agency or other body which, alone or jointly with others, determines the purposes and means of processing of personal data", while the processor is "person, public authority, agency or other body which processes personal data on behalf of the controller". If you are currently subject to the UK's Data Protection Act, for example, it's likely you will have to look at GDPR compliance too.
You’ve probably been hiring the wrong kind of data scientist
A lot of people like to call themselves data scientists because they’re using point-and-click tools, like Tableau and Excel, to perform data analysis and visualization in order to gain business insights. ... The real challenge comes from handling large datasets, including textual or other unstructured raw data, and doing so in real time–all of which requires programmatic execution. That is, coding. Indeed, many of the gains in AI and data science are thanks to what researchers are calling the “Unreasonable Effectiveness of Data”–being able to learn programmatically from astronomical data sets. This work is also highly nuanced and detailed, and doing the wrangling and cleaning properly is crucial for developing effective machine intelligence later on. Point-and-click software just isn’t sophisticated enough to substitute for good programming skills (after all, you can perform machine learning with Excel). This goes beyond just the usual mantra of “garbage in, garbage out.” Employers are trying to manage turbocharged public relations on social media while staying in regulators’ good graces despite that enhanced scrutiny.
A Simple and Scalable Analytics Pipeline
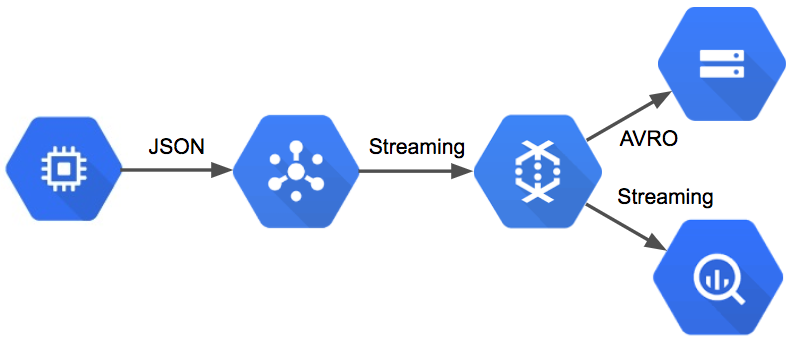
The core piece of technology I’m using to implement this data pipeline is Google’s DataFlow, which is now integrated with the Apache Beam library. DataFlow tasks define a graph of operations to perform on a collection of events, which can be streaming data sources. This post presents a DataFlow task implemented in Java that streams tracking events from a PubSub topic to a data lake and to BigQuery. An introduction to DataFlow and it’s concepts is available in Google’s documentation. While DataFlow tasks are portable, since they are now based on Apache Beam, this post focuses on how to use DataFlow in conjunction with additional managed services on GCP to build a simple, serverless, and scalable data pipeline. The data pipeline that performs all of this functionality is relatively simple. The pipeline reads messages from PubSub and then transforms the events for persistence: the BigQuery portion of the pipeline converts messages to TableRow objects and streams directly to BigQuery, while the AVRO portion of the pipeline batches events into discrete windows and then saves the events to Google Storage.
7 risk mitigation strategies for the cloud

“Cloud services often encourage ‘casual use’ of data; I can collect, search and store anything just about anywhere” is the hook, says John Hodges, vice president of product strategy for AvePoint. “We often see this in systems like Box, DropBox or OneDrive, where there is a real mixed-use danger in how content is stored and shared.” The simple solution? Prohibit services where mixed-use is likely to be a problem. ... Zero trust is an IT security strategy wherein an organization requires every user, system or device inside or outside its perimeter to be verified and validated before connecting to its systems. How can you use a zero trust model to mitigate cloud risk? For Insurity, an organization that specializes in property and casualty insurance services and software, a zero trust approach means restricting access tightly. “We provide logical access to the minimum set of users with a minimum set of rights and privileges in line with job function requirements. This control is audited internally by our Enterprise Security team and externally as part of our annual SOC audit,” says Jonathan Victor, CIO of Insurity. Regularly examine user access levels and ask yourself whether they make sense.
What Is Microservices? An Introduction to Microservice Architecture
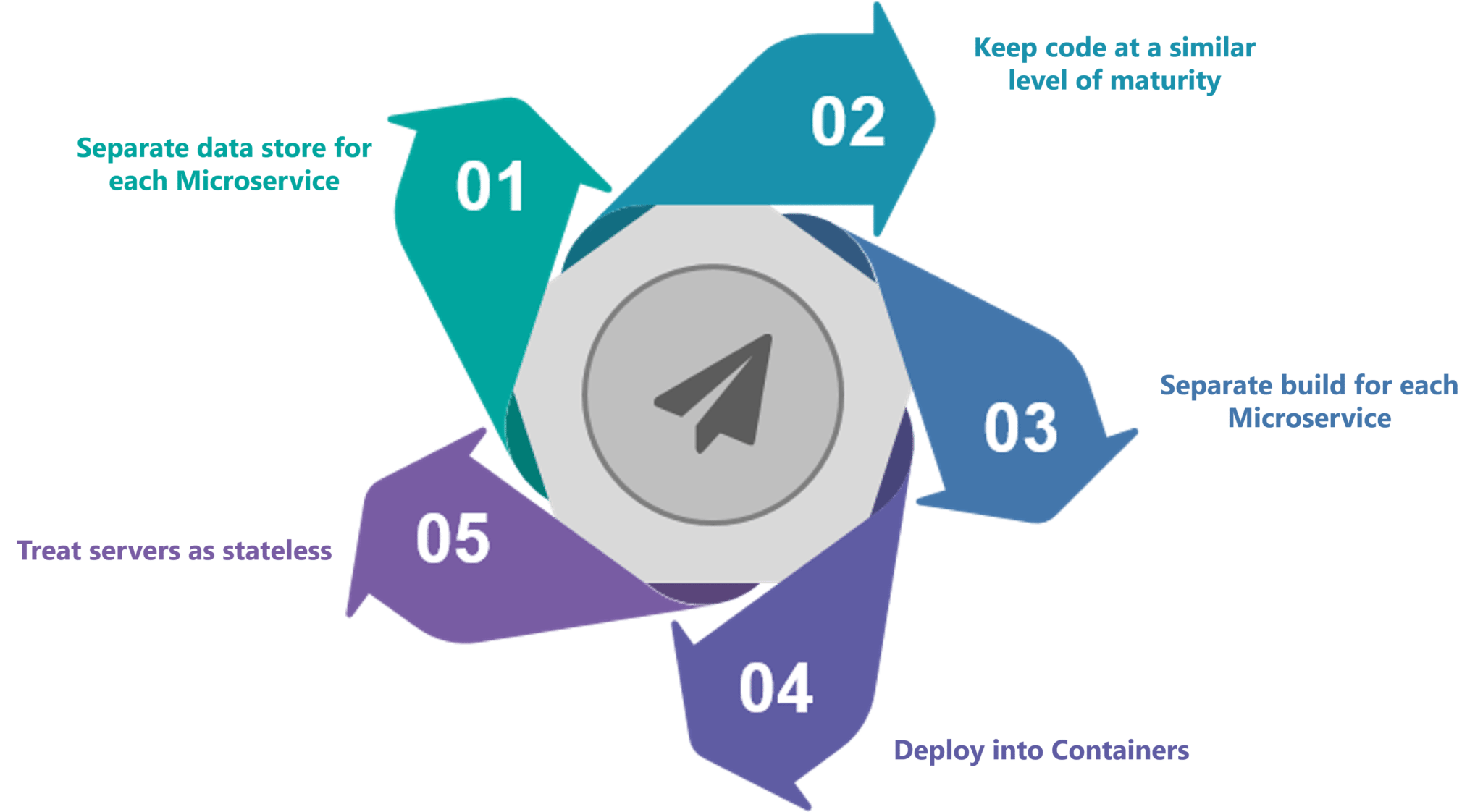
Now, let us look at a use-case to get a better understanding of microservices. Let's take a classic use case of a shopping cart application. When you open a shopping cart application, all you see is just a website. But, behind the scenes, the shopping cart application has a service for accepting payments, a service for customer services and so on. Assume that developers of this application have created it in a monolithic framework. So, all the features are put together in a single code base and are under a single underlying database. Now, let's suppose that there is a new brand coming up in the market and developers want to put all the details of the upcoming brand in this application. Then, they not only have to rework the service for new labels, but they also have to reframe the complete system and deploy it accordingly. To avoid such challenges developers of this application decided to shift their application from a monolithic architecture to microservices.
Cybercriminals Battle Against Banks' Incident Response
Persistent attackers aren't backing down when banks detect them and launch their incident response processes, either. One in four bank CISOs in the Carbon Black study say their institution faced attackers fighting back when they got spotted, trying to deter defenses and the investigation into the attack. "They are leaving wipers or destructive malware to inhibit [IR], deleting logs, and inhibiting the capacity of forensics tools," for example, says Tom Kellermann, chief cybersecurity officer at Carbon Black. "Sometimes they are using DDoS to create smokescreens during events." These counter-IR activities are forcing banks to be be more proactive and aggressive as well, he says. "They need to have threat hunting teams. You can't just rely on telemetry and alerts." While banks are often relying on their IR playbooks, attackers have the freedom to freelance and counter IR activities. They're changing their malware code on the fly when it gets detected, deleting activity logs to hide their tracks, and even targeting bank security analysts and engineers to help their cause.
Certain types of content make for irresistible phishes
It used to be that fear, urgency and curiosity were the top emotional motivators behind successful phishes. Now they’ve been replaced by entertainment, social media and reward/recognition. According to the company, simulated eCards, internal promotion/reward programs, and a number of financial and compliance scenarios (e.g., phishes with “Financial Information Review” or “Compliance Training” in the subject line) are most successful at getting users to click. Employees should be trained to be aware of their emotional reactions to emails and see them as phishing triggers. “When creating simulations, remember consumer scams—those phony Netflix or LinkedIn emails sent to busy employees, who are glad to switch gears and click on something fun,” the company notes. “Understand the dynamics of entertainment or social phishing (think uncritical social acceptance and shortened URLs).” And when it comes to emails promising rewards, employees should be taught to be critical of rewards and deals that sound too good to be true.
Quote for the day:
"You don't have to hold a position in order to be a leader." -- Anthony J. D'Angelo
No comments:
Post a Comment