How and why automation can improve network-device security

Automating the processes of device discovery and configuration validation allows
you to enforce good network security by making sure that your devices and
configurations not accidentally leaving any security holes open. Stated
differently, the goal of automation is to guarantee that your network policies
are consistently applied across the entire network. A router that’s forgotten
and left unsecured could be the avenue that bad actors exploit. Once each device
on the network is discovered, the automation system downloads its configurations
and checks them against the configuration rules that implement your network
policies. These policies range from simple things that are not security related,
like device naming standards, to essential security policies like authentication
controls and access control lists. The automation system helps deploy and
maintain the configurations that reflect your policies. ... A network-change and
configuration-management (NCCM) system can use your network inventory to
automate the backup of network-device configurations to a central repository.
How Unnecessary Complexity Gave the Service Mesh a Bad Name
The difficulty comes from avoiding “retry storms” or a “retry DDoS,” which is
when a system in a degraded state triggers retries, increasing load and further
decreasing performance as retries increase. A naive implementation won’t take
this scenario into account as it may require integrating with a cache or other
communication system to know if a retry is worth performing. A service mesh can
do this by providing a bound on the total number of retries allowed throughout
the system. The mesh can also report on these retries as they occur, potentially
alerting you of system degradation before your users even notice. ... The design
pattern of sidecar proxies is another exciting and powerful feature, even if it
is sometimes oversold and over-engineered to do things users and tech aren’t
quite ready for. While the community waits to see which service mesh “wins,” a
reflection of the over-hyped orchestration wars before it, we will inevitably
see more purpose-built meshes in the future and, likely, more end-users building
their own control planes and proxies to satisfy their use cases.
How To Deal With Data Imbalance In Classification Problems?

A classification model is a technique that tries to draw conclusions or predict
outcomes based on input values given for training. The input, for example, can
be a historical bank or any financial sector data. The model will predict the
class labels/categories for the new data and say if the customer will be
valuable or not, based on demographic data such as gender, income, age, etc.
Target class imbalance is the classes or the categories in the target class that
are not balanced. Rao, giving an example of a marketing campaign, said, let’s
say we have a classification task on hand to predict if a customer will respond
positively to a campaign or not. Here, the target column — responded has two
classes — yes or no. So, those are the two categories. In this case, let’s say
the majority of the people responded ‘no.’ Meaning, the marketing campaign where
you end up reaching out to a lot of customers, only a handful of them want to
subscribe, for example, this can be you offering a credit card, a new insurance
policy, etc. The one who subscribed or is interested would request more
details.
Motivational debt — it will fix itself, right?

Motivational debt is a hidden cost to product delivery. It’s the rust that is
accruing on aged PBIs, the sludge at the bottom of the Sprint Backlog and the
creaking of the process when needing to do something new. Technical debt is to
quality what motivational debt is to process. It’s important to remember that
whilst motivational debt is shouldered by the entire Scrum Team, there is an
individual element of accrual to it as well. Both short-term stresses which
bounce back quickly (“I didn’t get any sleep last night”) to long-term tensions
which don’t (“My parents are ill) all contribute to the motivational
complexities of a Scrum Team. Moving to address these actively is an ethical
quandary, as individuals have different coping mechanisms, meaning efforts to
help may actually exacerbate the issue. Remember that whilst some team members
may be feeling down, others may be up, therefore being conscious of the overall
direction of pull is vital as a Scrum Master. Holistically, it is fair to say
that motivational debt is felt both individually and collectively and it is
everyone’s responsibility to create an environment where it can be minimised.
But how can you do this?
Waste and inefficiency in outdated government IT systems

Those responsible for addressing the government’s current levels of wasted IT
expenditure may find that businesses offer positive, proactive case studies that
highlight the value of embracing digital transformation. A 2020 study from
Deloitte, for instance, has found that digitally mature companies – those that
have embraced various aspects of digital transformation – saw net revenue growth
of 45% and net profit growths of 43% compared to industry averages. The same
study has found that the benefits of digital maturation are not limited to
profits, but to a range of outcomes including increased efficiency, better
product and service quality, and higher levels of both customer satisfaction and
employee engagement. A study from McKinsey is even more strident, noting that
“by digitising information-intensive processes, costs can be cut by up to 90%
and turnaround times improved by several orders of magnitude.” Part of the
‘Organising for Digital Delivery Report’ includes a commitment to “investing in
developing the technical fluency of senior civil service leadership.”
Robotic process automation and intelligent automation are accelerating, study finds

Process mining is used to obtain a wide lens over business processes and
workflows within a company by examining event logs across systems, including
how variable they are and where there are bottlenecks. The less variable the
process, the greater its potential candidacy for RPA/IA, though other factors
must be considered as well. Task mining is used to understand how a user is
interacting with systems and where there are opportunities for automation.
Both of the above help identify automation candidates throughout an
organization. IDP is a use case of IA and is growing in popularity, as there
are so many document-intensive processes across organizations that impact many
employees. ... Data governance, visibility of shadow deployments (and having
guardrails in place for them), and security are all important to set in place
ahead of RPA/IA to ensure architectural readiness. Another challenge is
ensuring that the infrastructure is able to handle the increased speed and
volume of transactions related to automated processes, whether it’s their own
or someone they do business with.
Importance of DevOps Automation in 2021
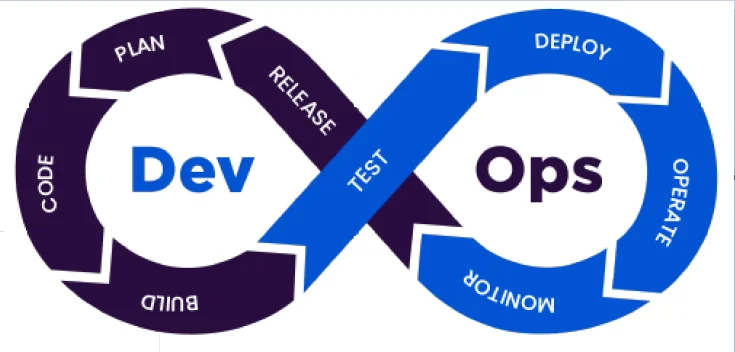
From a software development perspective, DevOps automation enhances the
performance of the engineering teams with the help of top-notch DevOps tools.
It encourages cross teams to work together by removing organizational silos.
The reduced team inter-dependencies and manual processes for infrastructure
management have enabled the software team to focus on frequent releases,
receiving quick feedback, and improving user experience. From an
organizational point of view, DevOps automation reduces the chances of human
errors and saves the time used for error detection with the help of
auto-healing features. Additionally, it minimizes the time required for
deploying new features significantly and removes any inconsistencies caused
due to human errors. Enterprises should first focus on the areas where they
face the most challenges. The decision on what to automate depends on their
organizational needs and technological feasibility. The DevOps automation
teams should be able to analyze which areas of the DevOps lifecycle needs
automation.
The biggest problem with ransomware is not encryption, but credentials

The obvious concern about being the victim of a ransomware attack is being
locked out from data, applications, and systems – making organizations unable
to do business. Then, there is the concern of what an attack is going to cost;
the question of whether or not you need to pay the ransomware is being forced
by cybercriminal gangs, as 77% of attacks also included the threat of leaking
exfiltrated data. Next are the issues of lost revenue, an average of 23 days
of downtime, remediation costs, and the impact on the businesses’ reputation.
But those are post-attack concerns, and you should, first and foremost, be
laser-focused on what effective measures you can you take to stop ransomware
attacks. Organizations that are truly concerned about the massive growth in
ransomware are working to understand the tactics, techniques and procedures
used by threat actors to craft preventative, detective and responsive measures
to either mitigate the risk or minimize the impact of an attack. Additionally,
these organizations are scrutinizing the technologies, processes and
frameworks they have in place, as well as asking the same of their third-party
supply chain vendors.

If your organization is looking to hire data engineers in the next 12 months, be
prepared to move quickly in your hiring process and think carefully before you
waste time negotiating salaries. That’s some of the advice for hiring managers
from the first edition of Salaries of Data Engineering Professionals from the
quantitative executive recruiting firm Burtch Works. Known for its work with
data scientists and analytics professionals, and its annual salary surveys that
look at the employment trends for those professionals, this year, Burtch Works
has expanded by offering this new survey for data engineers, conducted in
individual interviews with 320 of these professionals based in the United
States. The survey looks at salaries, demographics, and trends among data
engineers. What is a data engineer? These are the professionals responsible for
building and managing the data and IT infrastructure that sits between the data
sources and the data analytics. They report into the IT department, the data
science department, or both. According to the Burtch Works survey, these
professionals command a high rate of pay.
Data And Analytics In Healthcare: Addressing the 21st-century Challenges
Scientists have claimed victory against future diseases after successfully
decoding the human genome. The marriage of this knowledge to the health data
generated by patients would enable clinicians to make better decisions about our
care. The two benefits of using predictive analytics: better care and lower
costs. The biggest lesson of the recent global health issues such as COVID-19,
SARS, dengue and malaria outbreaks is that pharma and healthcare companies
cannot afford merely to react to every emerging situation. They need to track
several data streams of local, regional, and global trends, create a database,
and then predict various scenarios. Data analytics helps companies develop their
predictive models, enabling them to make quicker, intelligent decisions, build
partnerships, and resolve bottlenecks before the crisis hits the shore. Such
data-driven measures aim to save invaluable lives and allow care to be
personalized for each individual. Predictive analytics can classify particular
risk factors for diverse populations. This is very useful for patients suffering
from multiple ailments with complex medical histories.
Quote for the day:
"Every great leader has incredible odds
to overcome." -- Wayde Goodall