How to choose a cloud IoT platform

“The internet” is not an endpoint, of course, but an interconnected collection of networks that transmit data. For IoT, the remote endpoints are often located in a cloud server rather than in a single server inside a private data center. Deploying in a cloud isn’t absolutely necessary if all you’re doing is measuring soil moisture at a bunch of locations, but it can be very useful. Suppose that the sensors measure not only soil moisture, but also soil temperature, air temperature, and air humidity. Suppose that the server takes data from thousands of sensors and also reads a forecast feed from the weather service. Running the server in a cloud allows you to pipe all that data into cloud storage and use it to drive a machine learning prediction for the optimum water flow to use. That model could be as sophisticated and scalable as you want. In addition, running in the cloud offers economies. If the sensor reports come in once every hour, the server doesn’t need to be active for the rest of the hour. In a “serverless” cloud configuration, the incoming data will cause a function to spin up to store the data, and then release its resources. Another function will activate after a delay to aggregate and process the new data, and change the irrigation water flow set point as needed.
How to create a ransomware incident response plan

Companies should test an incident response plan -- ideally, before an incident, as well as on a regular basis -- to ensure it accomplishes its intended results. Using a tabletop exercise focused on testing the response to a ransomware incident, participants can use existing tools to test their effectiveness and determine if additional tools are necessary. Companies may want to have annual, quarterly or even monthly exercises to test the plan and prepare the business. These tests should involve all the relevant parties, including IT staff, management, the communications team, and the public relations (PR) and legal teams. Enterprises should also document which of their security tools have ransomware prevention, blocking or recovery functionality. Additional tests should be conducted to verify simulated systems infected with ransomware can be restored using a backup in a known-good state. While some systems save only the most recent version of a file or a limited number of versions, testing to restore the data, system or access to all critical systems is a good idea.
Report: Chinese-linked hacking group has been infiltrating APAC governments for years

Check Point has found three versions of the attack— infected RTF files, archive files containing a malicious DLL, and a direct executable loader. All three worm their way into a computer's startup folder, download additional malware from a command and control server, and go to work harvesting information. The report concludes that Naikon APT has been anything but inactive in the five years since it was discovered. "By utilizing new server infrastructure, ever-changing loader variants, in-memory fileless loading, as well as a new backdoor — the Naikon APT group was able to prevent analysts from tracing their activity back to them," Check Point said in its report. While the attack may not appear to be targeting governments outside the APAC region, examples like these should serve as warnings to other governments and private organizations worried about cybersecurity threats. One of the reasons Naikon APT has been able to spread so far is because it leverages stolen email addresses to make senders seem legitimate. Every organization, no matter the size, should have good email filters in place, and should train employees to recognize the signs of phishing and other email-based attacks.
Patterns for Managing Source Code Branches
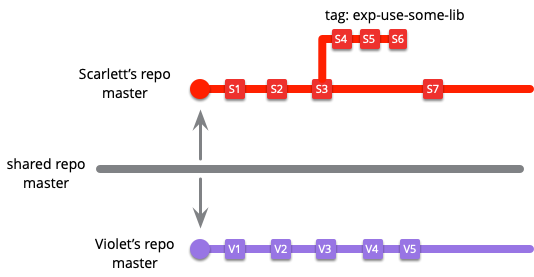
With distributed version control systems like git, this means we also get additional branches whenever we further clone a repository. If Scarlett clones her local repository to put on her laptop for her train home, she's created a third master branch. The same effect occurs with forking in github - each forked repository has its own extra set of branches. This terminological confusion gets worse when we run into different version control systems as they all have their own definitions of what constitutes a branch. A branch in Mercurial is quite different to a branch in git, which is closer to Mercurial's bookmark. Mercurial can also branch with unnamed heads and Mercurial folks often branch by cloning repositories. All of this terminological confusion leads some to avoid the term. A more generic term that's useful here is codeline. I define a codeline as a particular sequence of versions of the code base. It can end in a tag, be a branch, or be lost in git's reflog. You'll notice an intense similarity between my definitions of branch and codeline. Codeline is in many ways the more useful term, and I do use it, but it's not as widely used in practice.

The recognition pattern is notable in that it was primarily the attempts to solve image recognition challenges that brought about heightened interest in deep learning approaches to AI, and helped to kick off this latest wave of AI investment and interest. The recognition pattern however is broader than just image recognition In fact, we can use machine learning to recognize and understand images, sound, handwriting, items, face, and gestures. The objective of this pattern is to have machines recognize and understand unstructured data. This pattern of AI is such a huge component of AI solutions because of its wide variety of applications. The difference between structured and unstructured data is that structured data is already labelled and easy to interpret. However unstructured data is where most entities struggle. Up to 90% of an organization's data is unstructured data. It becomes necessary for businesses to be able to understand and interpret this data and that's where AI steps in. Whereas we can use existing query technology and informatics systems to gather analytic value from structured data, it is almost impossible to use those approaches with unstructured data.
Al Baraka Bank Sudan transforms into an intelligent bank with iMAL*BI

The solution comprises comprehensive data marts equipped with standard facts and dimensions as well as progressive measures that empower the bank’s workforce to build ad-hoc dashboards, in-memory, to portray graphical representations of their data queries. It is rich in out-of-the-box dashboards, covering financial accounting, retail banking, corporate banking, investments, trade finance, limits, in addition to C-level executives’ analytics boosting a base set of KPIs, dashboards and advanced analytics which are essential to each executive with highly visual, interactive and collaborative dashboards backed by centralised metadata security. This strategic platform empowers bankers to make smarter, faster, and more effective decisions, improving operational efficiency. It also enables business agility while driving innovation, competitive differentiation, and profitable growth. The implementation covered the establishment of a comprehensive end-to-end data warehousing solution, an automated ETL process and a progressive data model.
The new cybersecurity resilience

While security teams and experts might have differing metrics for gauging resiliency, they tend to agree on the overarching need and many of the best practices to achieve it. “Resiliency is viewed by some to be the latest buzzword replacing continuity or recovery, but to me it really means placing the appropriate people, processes, and procedures in place to ensure you’re limiting the need for enacting a continuity or recovery plan,” says Shared Assessments Vice President and CISO Tom Garrubba. Resilient organizations share numerous traits. According to Accenture they place a premium on collaboration – 79 percent say collaboration will be key to battling cyberattacks and 57 percent collaborate with partners to test resilience. “By adopting a realistic, broad-based, collaborative approach to cybersecurity and resilience, government departments, regulators, senior business managers and information security professionals will be better able to understand the true nature of cyber threats and respond quickly, and appropriately,” says Steve Durbin, managing director at the Information Security Forum (ISF).
Microsoft and Intel project converts malware into images before analyzing it

The Intel and Microsoft team said that resizing the raw image did not "negatively impact the classification result," and this was a necessary step so that the computational resources won't have to work with images consisting of billions of pixels, which would most likely slow down processing. The resides images were then fed into a pre-trained deep neural network (DNN) that scanned the image (2D representation of the malware strain) and classified it as clean or infected. Microsoft says it provided a sample of 2.2 million infected PE (Portable Executable) file hashes to serve as a base for the research. Researchers used 60% of the known malware samples to train the original DNN algorithm, 20% of the files to validate the DNN, and the other 20% for the actual testing process. The research team said STAMINA achieved an accuracy of 99.07% in identifying and classifying malware samples, with a false positives rate of 2.58%. "The results certainly encourage the use of deep transfer learning for the purpose of malware classification," said Jugal Parikh and Marc Marino
Prepare for the future of distributed cloud computing

Enterprises need to support edge-based computing systems, including IoT and other specialized processing that have to occur near the data source. This means that while we spent the past several years centralizing processing storage in public clouds, now we’re finding reasons to place some cloud-connected applications and data sources near to where they can be most effective, all while still maintaining tight coupling with a public cloud provider. Companies need to incorporate traditional systems in public clouds without physical migration. If you consider the role of connected systems, such as AWS’s Outpost or Microsoft’s Azure Stack, these are really efforts to get enterprises to move to public cloud platforms without actually running physically in a public cloud. Other approaches include containers and Kubernetes that run locally and within the cloud, leveraging new types of technologies, such as Kubernetes federation. The trick is that most enterprises are ill-equipped to deal with distribution of cloud services, let alone move a critical mass of applications and data to the cloud.
Source Generators Will Enable Compile-time Metaprogramming in C# 9
Loosely inspired by F# type providers, C# source generators respond to the same aim of enabling metaprogramming but in a completely different way. Indeed, while F# type providers emit types, properties, and methods in-memory, source generators emit C# code back into the compilation process. Source generators cannot modify existing code, only add new code to the compilation. Another limitation of source generators is they cannot be applied to code emitted by other source generators. This ensures each code generator will see the same compilation input regardless of the order of their application. Interestingly, source generators are not limited to inspecting source code and its associated metadata, but they may access additional files. Specifically, source generators are not designed to be used as code rewriting tools, such as optimizers or code injectors, nor are they meant to be used to create new language features, although this would be technically feasible to some limited extent.
Quote for the day:
"You’ve got to get up every morning with determination if you’re going to go to bed with satisfaction." -- George Lorimer
No comments:
Post a Comment