10 things you thought you knew about blockchain that are probably wrong

Blockchain and DLT mean the same thing: Not so much. A blockchain is just one type of DLT. There are many such technologies, and not all of them are blockchains. Just like using the term Xerox to describe all photocopies, "blockchain" is being used to refer to all types of DLTs regardless of underlying technology or architecture but, at this point in the technology's evolution, it's a distinction without a difference, Bennett said. This is why the report itself references all DLTs as blockchains. ... Blockchains will eliminate the need for intermediaries in transactions: While they may change the role of these individuals and organizations, DLTs will not eliminate the role they play in facilitating, verifying, or closing transactions. "The only way to cut out third parties is for a consumer or business to interact with a blockchain directly," the report said. "But even in scenarios where ecosystem partners deal directly with each other at the expense of existing third parties, it doesn't mean third parties will no longer be part of the mix. And let's not forget that the world of cryptocurrencies is full of trusted third parties in the shape of wallet providers and cryptocurrency exchanges."
A Hybrid Approach to Database DevOps
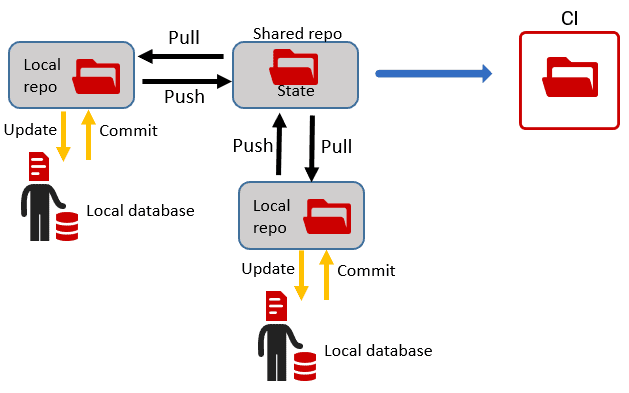
Redgate’s state-based deployment approach uses a schema comparison engine to generate a ‘model’ of the source database, from the DDL (state) scripts, and then compares this to the metadata of a target database. It auto-generates a single deployment script that will make the target the same as the source, regardless of the version of the source and target. If the target database is empty, then the auto-generated script will contain the SQL to create all the required objects, in the correct dependency order, in effect migrating a database at version “zero”, to the version described in the source. This approach works perfectly well for any development builds where preserving existing data is not required. If the current build becomes a candidate for release, and we continue with the same approach, then the tool would generate a deployment script that will modify the schema of any target database so that it matches the version represented by the release candidate. However, if the development involves making substantial schema alterations, such as to rename tables or columns, or split tables and remodel relationships then it will be impossible for the automated script to understand how to make them while preserving existing data.
Health Data Breach Update: What Are the Causes?

Security and privacy teams need to be ready to deal with staff departures, security experts say. "We cannot presume to know the reason for the doctor moving to a different organization, but what is often not mentioned in any type of privacy or security training is 'whose information is it, anyway?''' says Susan Lucci, senior privacy and security consultant at tw-Security. "Some providers may assume that once they treat patients, they have rights to all their information. It appears that in this case, the physician downloaded only information that would be beneficial to alert the patient of the physician's new practice, not that it was downloaded for continuity of care. The personally identifiable information belongs to the facility, and they have a duty to protect it. Release of any confidential information must take place through appropriate channels and authorization." As healthcare entities and their vendors continue to deal with the COVID-19 crisis, new circumstances for breaches could emerge, some experts note.
Why Data Quality Is Critical For Digital Transformation

Often in the case of mergers, companies struggle the most with the consequences of poor data. When one company’s Customer Relationship Management (CRM) system is messed up, it affects the entire migration process – where time and effort is supposed to be spent in understanding and implementing the new system, it’s spent in sorting data! What exactly constitutes poor data? Well, if your data suffers from: Human input error such as spelling mistakes, typos, upper- and lower-case issues, lack of consistency in naming conventions across the data set; Inconsistent data format across the data set such as phone numbers with and without a country code or numbers with punctuation; Address data that is invalid or incomplete with missing street names or postcodes; and Fake names, addresses or phone numbers …then it’s considered to be flawed data. These are considered surface issues that are inevitable and universal – as long as you have humans formulating and inputting the data errors will occur.
Cisco, others, shine a light on VPN split-tunneling

Basically split tunneling is a feature that lets customers select specific, engerprise-bound traffic to be sent through a corporate VPN tunnel. The rest goes directly to the Internet Service Provider (ISP) without going throuogh the tunnel. Otherwise all traffic, even traffic headed for sites on the internet, would go through the VPN, through enterprise security measures and then back out to the internet.The idea is that the VPN infrastructure has to handle less traffic, so it performs better. Figuring out what traffic can be taken out of the VPN stream can be a challenge that Cisco is trying to address with a relatively recent product. It combines tellemetry data gathered by Cisco AnyConnect VPN clients with real-time report generation and dashboard technology from Splunk.Taken together the product is known as Cisco Endpoint Security Analytics (CESA) and is part of the AnyConnect Network Visibility Module (NVM). Cisco says that until July 1, 2020, CESA trial licenses are offered free for 90 days to help IT organizations with surges in remote working.
How to control access to IoT data

Companies also shouldn’t forget to consider security measures that they have in place for other areas of the business, and think twice before relying on settings already applied to devices without checking. “IT teams cannot forget to apply basic IT security policies when it comes to controlling access to IoT generated data,” Simpson-Pirie continued. “The triple A process of access, authentication and authorisation should be applied to every IoT device. It’s imperative that each solution maintains a stringent security framework around it so there is no weak link in the chain. “Security has long been a second thought with IoT, but the stakes are too high in the GDPR era to simply rely on default passwords and settings.” Security is, by no means, the only important aspect to consider when controlling access to IoT data; there are also the matters of visibility, and having a backup plan for when security becomes weakened. For Rob McNutt, CTO at Forescout, the latter can come to fruition by segmenting the network. “Organisations need to have full visibility and control over all devices on their networks, and they need to segment their network appropriately,” he said.
Nvidia & Databricks announce GPU acceleration for Spark 3.0

The GPU acceleration functionality is based on the open source RAPIDS suite of software libraries, themselves built on CUDA-X AI. The acceleration technology, named (logically enough) the RAPIDS Accelerator for Apache Spark, was collaboratively developed by Nvidia and Databricks (the company founded by Spark's creators). It will allow developers to take their Spark code and, without modification, run it on GPUs instead of CPUs. This makes for far faster machine learning model training times, especially if the hardware is based on the new Ampere-generation GPUs, which by themselves offer 5-fold+ faster training and inferencing/scoring times than their Nvidia Volta predecessors. Faster training times allow for greater volumes of training data, which is needed for greater accuracy. But Nvidia says the RAPIDS accelerator also dramatically improves the performance of Spark SQL and DataFrame operations, making the GPU acceleration benefit non-AI workloads as well. This means the same Spark cluster hardware can be used for both data engineering/ETL workloads as well as machine learning jobs.
Nation state APT groups prefer old, unpatched vulnerabilities

“The recent diffusion of smart working increased enormously the adoption of SaaS solutions for office productivity, customer service, financial administration, and other processes. This urgency also increased as well the exposure of misconfigured or too permissive rights. All this has been leveraged by attackers to their advantage,” he said. “A solid vulnerability management, detection, and response workflow that included the ability to validate cloud security posture and compliance with CIS benchmarks – while shortening the Time To Remediate (TTR) would have been a great help for security teams,” said Rottigni. “The mentioned vulnerabilities made their ways in these sad hit parades as the most exploited ones: a clear indicator of the huge room for improvement that organisations still have.” “They can achieve this with properly orchestrated security programs, leveraging SaaS solutions that have the fastest adoption path, the shortest learning curve and the highest success rate in risk mitigation due to their pervasiveness across the newest and widest digital landscapes.”
Evolving IT into a Remote Workforce
When remote work initiatives first began rolling out 20 years ago, I recall a telecom sales manager telling me that six months after he'd deployed his sales force to the field where they all worked out of home offices, he discovered a new problem: He was losing cohesion in his salesforce. “Employees wanted to come in for monthly meetings,” he said. “It was important from a team morale standpoint for them to interact with each other, and for all of us to remind each other what the overall corporate goals and sales targets were.” The solution at that time was to create monthly on-prem staff meetings where everyone got together. A similar phenomenon could affect IT workforces that take up residence in home offices to perform remote work. There could be breakdowns in IT project cohesion without the benefit of on-prem “water cooler” conversations and meetings that foster lively information exchanges. In other cases, there could be some employees who don't perform as well in a home office as they would in the company office. IT managers are likely to find that their decisions on what IT can be done remotely will be based on not only what they could outsource, but also whom.
AI: A Remedy for Human Error?

Humans are naturally prone to making mistakes. Such errors are increasingly impactful in the workplace, but human error in the realm of cybersecurity can have particularly devastating and long-lasting effects. As the digital world becomes more complex, it becomes much tougher to navigate – and thus, more unfair to blame humans for the errors they make. Employees should be given as much help and support as possible. But employees are not often provided with the appropriate security solutions, so they resort to well-intentioned workarounds in order keep pace and get the job done. As data continues to flow faster and more freely than ever before, it becomes more tempting to just upload that document from your personal laptop, or click on that link, or share that info to your personal email. Take, for instance, one of the most common security problems: phishing emails. An employee might follow instructions in a phishing email not only because it looks authentic, but that it conveys some urgency. Employee training can help reduce the likelihood of error, but solving the technological shortcoming is more effective: if a phishing email is blocked from delivery in the first place, we can help mitigate the human error factor.
Quote for the day:
"Leadership is intangible, and therefore no weapon ever designed can replace it." -- Omar N. Bradley
No comments:
Post a Comment