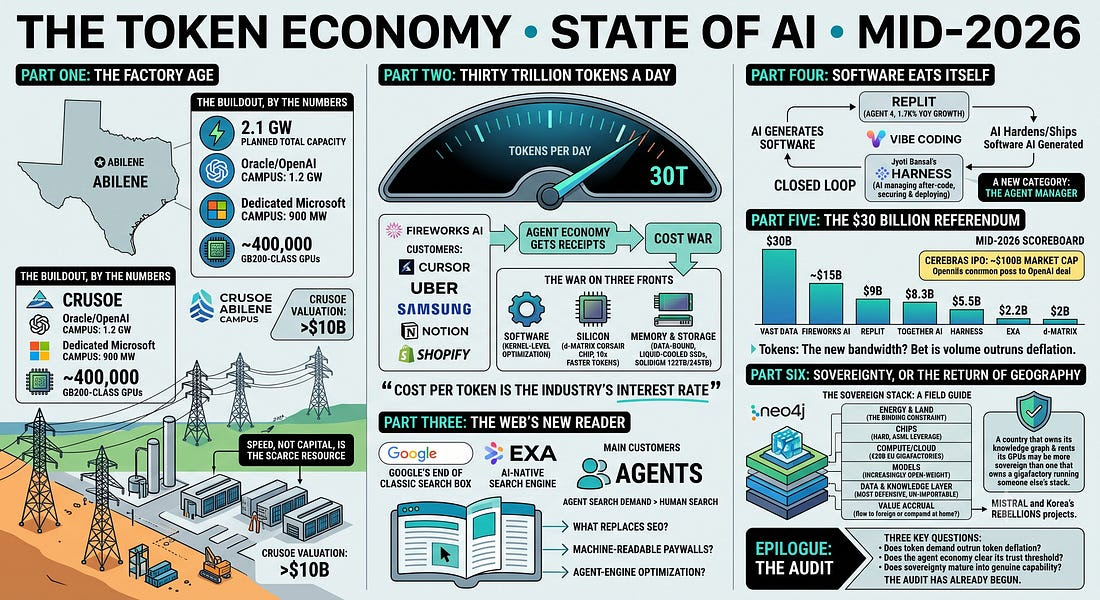
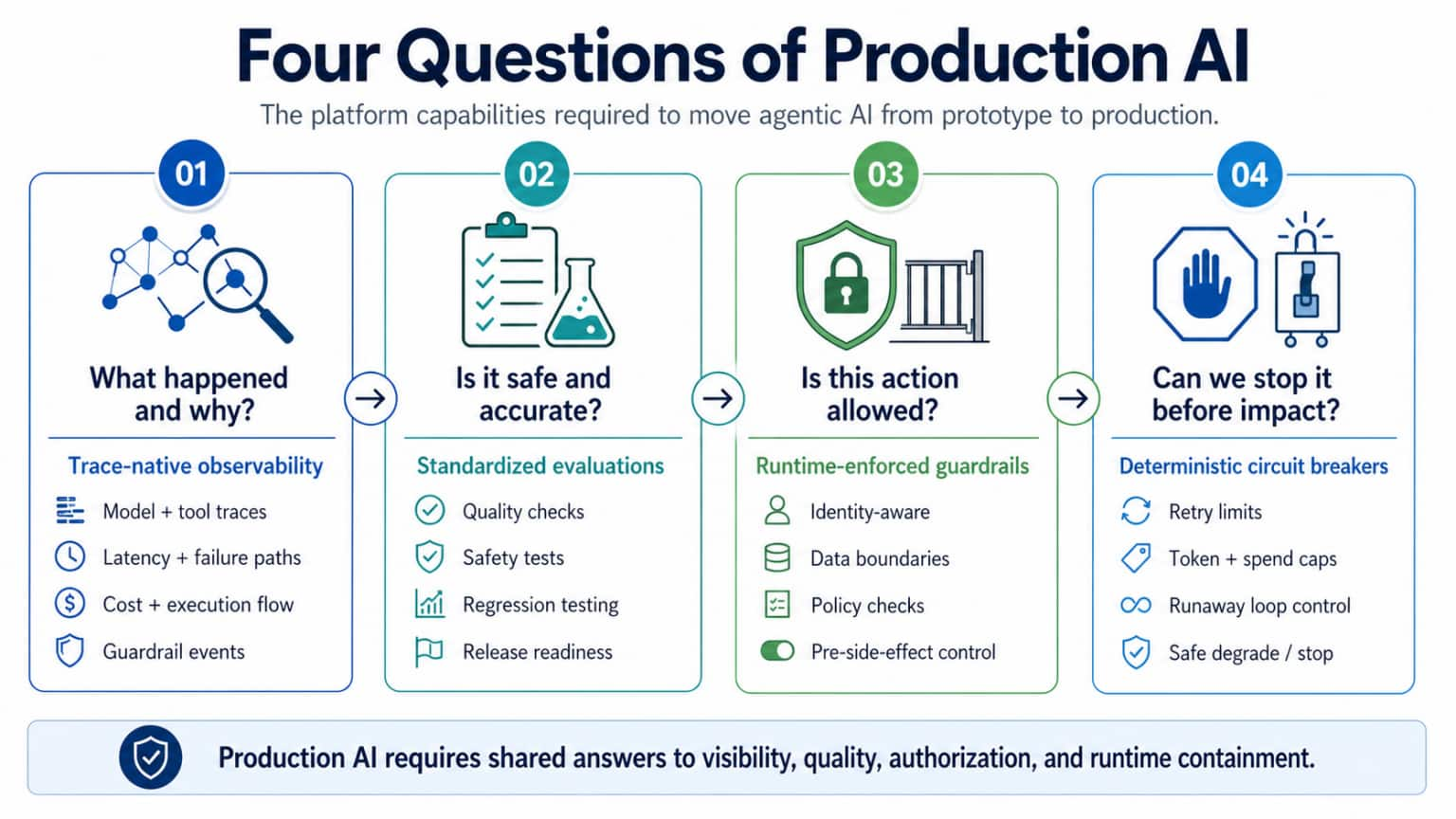
Quote for the day:
“None of us is as smart as all of us.” -- Ken Blanchard
🎧 Listen to this digest on YouTube Music
▶ Play Audio DigestDuration: 23 mins • Perfect for listening on the go.
The Inferencing Cost Problem No One Is Talking About: Unstructured Data Quality
 As companies expand their artificial intelligence budgets, many focus heavily
on the initial price of building models while overlooking the ongoing expense
of running them. Every single time a model answers a question, it consumes
computing power and incurs a fee. While engineering teams use various tactics
to manage these processing costs, they frequently ignore a major factor: the
quality of the unstructured files being fed into the system. Unstructured
information, like everyday documents, emails, and images, makes up a massive
portion of enterprise data but typically lacks clear labels. When businesses
feed disorganized or irrelevant files into artificial intelligence, they end
up paying to process useless information. By properly sorting and labeling
this data with descriptive tags before it ever reaches the model,
organizations can drastically reduce their computing and storage expenses.
Sending only the most relevant files directly lowers the volume of information
processed, which in turn drops the overall cost. Proper data sorting also
prevents sensitive or outdated information from being exposed, reducing legal
and ethical risks. Ultimately, treating careful data preparation as a core
financial strategy allows companies to control their spending while
simultaneously improving the accuracy and safety of their new artificial
intelligence software tools.
As companies expand their artificial intelligence budgets, many focus heavily
on the initial price of building models while overlooking the ongoing expense
of running them. Every single time a model answers a question, it consumes
computing power and incurs a fee. While engineering teams use various tactics
to manage these processing costs, they frequently ignore a major factor: the
quality of the unstructured files being fed into the system. Unstructured
information, like everyday documents, emails, and images, makes up a massive
portion of enterprise data but typically lacks clear labels. When businesses
feed disorganized or irrelevant files into artificial intelligence, they end
up paying to process useless information. By properly sorting and labeling
this data with descriptive tags before it ever reaches the model,
organizations can drastically reduce their computing and storage expenses.
Sending only the most relevant files directly lowers the volume of information
processed, which in turn drops the overall cost. Proper data sorting also
prevents sensitive or outdated information from being exposed, reducing legal
and ethical risks. Ultimately, treating careful data preparation as a core
financial strategy allows companies to control their spending while
simultaneously improving the accuracy and safety of their new artificial
intelligence software tools.Six Thinking Hats: An S-Tier Behavioral Designer’s Guide
 Edward de Bono’s Six Thinking Hats is a structured framework designed to
eliminate the conflict and ego that derail most meetings. De Bono argued that
traditional arguments force individuals to blindly defend their initial
positions, preventing actual collaboration. His solution was “parallel
thinking,” where everyone in a meeting adopts the exact same perspective
simultaneously, represented by six colored hats. The White hat focuses
strictly on facts and missing data. The Red hat allows participants to express
pure emotion and gut feelings without any need for justification. The Black
hat, often the default setting in business, is used to identify risks and
flaws. The Yellow hat forces a rigorous search for optimism and hidden value.
The Green hat generates creative alternatives without judgment. Finally, the
Blue hat manages the overall process, sets the agenda, and keeps the group
focused. By assigning these specific modes of thinking to hats rather than
people, the framework removes the need to defend personal ideas. Instead of a
tug-of-war, the meeting becomes a cooperative exploration of a problem from
multiple angles. When facilitated correctly, this method can drastically
reduce meeting times and lead to much smarter, more unified group decisions.
Edward de Bono’s Six Thinking Hats is a structured framework designed to
eliminate the conflict and ego that derail most meetings. De Bono argued that
traditional arguments force individuals to blindly defend their initial
positions, preventing actual collaboration. His solution was “parallel
thinking,” where everyone in a meeting adopts the exact same perspective
simultaneously, represented by six colored hats. The White hat focuses
strictly on facts and missing data. The Red hat allows participants to express
pure emotion and gut feelings without any need for justification. The Black
hat, often the default setting in business, is used to identify risks and
flaws. The Yellow hat forces a rigorous search for optimism and hidden value.
The Green hat generates creative alternatives without judgment. Finally, the
Blue hat manages the overall process, sets the agenda, and keeps the group
focused. By assigning these specific modes of thinking to hats rather than
people, the framework removes the need to defend personal ideas. Instead of a
tug-of-war, the meeting becomes a cooperative exploration of a problem from
multiple angles. When facilitated correctly, this method can drastically
reduce meeting times and lead to much smarter, more unified group decisions.
Data Governance Fails Without Culture Change
 Most data governance initiatives fail not because of flawed rules, but because
organizations neglect to change employee behavior. According to recent survey
data, only about a quarter of organizations include culture and communication
in their data strategies, while the vast majority focus strictly on technical
controls and security. This oversight is costly; analysts predict that
companies failing to address these cultural habits will also struggle to
manage artificial intelligence effectively. To succeed, organizations should
adopt a minimum effective approach. Instead of attempting massive,
company-wide data cleanups that take years and cause people to lose interest,
teams should focus on improving only the specific data needed to achieve
immediate business goals. Once that specific data reaches an acceptable
quality level, the team moves to the next priority. Furthermore, rather than
forcing new rules onto unwilling employees, leaders should identify the people
who are already informally fixing data issues and officially support their
efforts. Acknowledging their hard work and simplifying their existing
processes builds trust. Finally, keeping a program alive requires celebrating
small, visible wins and ensuring that every meeting is highly relevant, so
participants feel their unique input is genuinely necessary for the company's
ongoing success.
Most data governance initiatives fail not because of flawed rules, but because
organizations neglect to change employee behavior. According to recent survey
data, only about a quarter of organizations include culture and communication
in their data strategies, while the vast majority focus strictly on technical
controls and security. This oversight is costly; analysts predict that
companies failing to address these cultural habits will also struggle to
manage artificial intelligence effectively. To succeed, organizations should
adopt a minimum effective approach. Instead of attempting massive,
company-wide data cleanups that take years and cause people to lose interest,
teams should focus on improving only the specific data needed to achieve
immediate business goals. Once that specific data reaches an acceptable
quality level, the team moves to the next priority. Furthermore, rather than
forcing new rules onto unwilling employees, leaders should identify the people
who are already informally fixing data issues and officially support their
efforts. Acknowledging their hard work and simplifying their existing
processes builds trust. Finally, keeping a program alive requires celebrating
small, visible wins and ensuring that every meeting is highly relevant, so
participants feel their unique input is genuinely necessary for the company's
ongoing success.Event-Driven Architecture Anti-Patterns on AWS - Failure Modes, Root Causes, and How to Design Around Them
Event-driven architectures often fail quietly in production because design
mistakes remain hidden during initial testing. A recent guide outlines common
anti-patterns that cause these systems to break, focusing heavily on how teams
misconfigure core cloud services. One major trap is the infinite event loop,
where a function writes its output directly back to the exact same location
that triggered it. This creates a runaway cycle that can quickly rack up
massive cloud bills, especially when the default loop detection safeguards do
not cover certain routing services. Another frequent error is assuming that
standard messaging queues will deliver events in the exact order they were
sent. Because basic queues only offer best-effort ordering, heavy traffic will
inevitably scramble the sequence and silently corrupt data unless developers
explicitly enforce strict ordering rules. Furthermore, many engineers wrongly
assume that a system will deliver a message exactly once. In reality, standard
setups guarantee at-least-once delivery, meaning duplicate messages are
completely normal. If a developer fails to design a system that can safely
process the identical message multiple times, the application might execute
actions twice, resulting in duplicate customer charges or incorrect inventory
counts. To prevent these failures, teams must understand and design around the
exact documented limits of their infrastructure.
 Observability platforms are rapidly evolving beyond standard system monitoring
to address the growing complexities of enterprise technology, particularly the
rise of artificial intelligence. According to a recent Gartner report, vendors
are heavily investing in features like autonomous investigations and
operational intelligence to help technical teams identify root causes and find
the best solutions quickly. A major driving force behind this shift is the
need to monitor artificial intelligence workloads, tracking everything from
token usage and response times to the accuracy of language models. While
vendors heavily promote these new capabilities, the report notes that fully
autonomous operations remain largely aspirational. Meanwhile, managing the
sheer cost of collecting system data has become a top priority for businesses.
Because data volumes are exploding, organizations are demanding better cost
management tools to justify their investments, with some spending over ten
million dollars annually on a single provider. Additionally, the widespread
adoption of open data standards like OpenTelemetry has commoditized basic data
collection. Consequently, vendors must now differentiate themselves by
offering superior analytics, integrated automated workflows, and comprehensive
full-stack platforms that turn raw system data into measurable business
intelligence.
Observability platforms are rapidly evolving beyond standard system monitoring
to address the growing complexities of enterprise technology, particularly the
rise of artificial intelligence. According to a recent Gartner report, vendors
are heavily investing in features like autonomous investigations and
operational intelligence to help technical teams identify root causes and find
the best solutions quickly. A major driving force behind this shift is the
need to monitor artificial intelligence workloads, tracking everything from
token usage and response times to the accuracy of language models. While
vendors heavily promote these new capabilities, the report notes that fully
autonomous operations remain largely aspirational. Meanwhile, managing the
sheer cost of collecting system data has become a top priority for businesses.
Because data volumes are exploding, organizations are demanding better cost
management tools to justify their investments, with some spending over ten
million dollars annually on a single provider. Additionally, the widespread
adoption of open data standards like OpenTelemetry has commoditized basic data
collection. Consequently, vendors must now differentiate themselves by
offering superior analytics, integrated automated workflows, and comprehensive
full-stack platforms that turn raw system data into measurable business
intelligence.
AI workloads shake up observability market
Observability platforms are rapidly evolving beyond standard system monitoring
to address the growing complexities of enterprise technology, particularly the
rise of artificial intelligence. According to a recent Gartner report, vendors
are heavily investing in features like autonomous investigations and
operational intelligence to help technical teams identify root causes and find
the best solutions quickly. A major driving force behind this shift is the
need to monitor artificial intelligence workloads, tracking everything from
token usage and response times to the accuracy of language models. While
vendors heavily promote these new capabilities, the report notes that fully
autonomous operations remain largely aspirational. Meanwhile, managing the
sheer cost of collecting system data has become a top priority for businesses.
Because data volumes are exploding, organizations are demanding better cost
management tools to justify their investments, with some spending over ten
million dollars annually on a single provider. Additionally, the widespread
adoption of open data standards like OpenTelemetry has commoditized basic data
collection. Consequently, vendors must now differentiate themselves by
offering superior analytics, integrated automated workflows, and comprehensive
full-stack platforms that turn raw system data into measurable business
intelligence.Why network recovery still depends on a site visit
The article explains why, despite major improvements in monitoring and
automation, network recovery often still requires someone to physically visit
a site. When a device stops responding—whether from a power issue, a failed
update, aging hardware, or environmental stress—operators can usually see the
problem right away. What they can’t always do is fix it remotely. That gap
between detection and action becomes more costly as networks spread across
rural areas, edge locations, and other hard‑to‑reach sites. A single reset may
seem minor, but repeated truck rolls add up in labor, travel time, scheduling
delays, and extended outages. The piece notes that many outages now carry
significant financial impact, with more than half costing over $100,000. The
industry has long relied on manual intervention because it feels safe and
familiar, but this approach strains teams and slows recovery as footprints
grow. The author argues that the next step in resilience is shifting from
passive visibility to active, remote control—especially through automated
power management. With the ability to reset equipment from afar, outages can
shrink from hours to minutes, technicians can focus on work that truly
requires their expertise, and operators can scale without multiplying manual
effort. Ultimately, the article suggests that closing the gap between knowing
something is broken and being able to fix it remotely is essential for modern
network reliability.
Open source helps governments shift from technical debt to technical equity
-1783661616299.jpg) Many public sector technology projects suffer from poor planning, resulting in
a backlog of outdated and complex systems that are often tied to a single
vendor. This ongoing burden makes future upgrades slow and expensive. To fix
this, governments are encouraged to shift their focus from simply buying
software to building lasting public resources. This approach relies heavily on
adopting established open source software and shared standards. Instead of
just asking who owns the code, public institutions need to focus on who will
properly maintain, secure, and improve it over time. The root of the problem
frequently begins during the purchasing process, where contracts often
prioritize fast delivery over lasting usability and easy maintenance. By
changing how they buy technology, public agencies can demand software that is
built to be shared across multiple departments, preventing wasted effort and
redundant spending. Furthermore, building inclusive, accessible, and efficient
digital services from the beginning rather than treating these features as
afterthoughts ensures the technology serves all citizens effectively.
Ultimately, every new digital investment represents a choice. Governments can
either continue piling on maintenance burdens for future teams, or they can
invest in shared, adaptable technology that actively strengthens their digital
capacity for years.
Many public sector technology projects suffer from poor planning, resulting in
a backlog of outdated and complex systems that are often tied to a single
vendor. This ongoing burden makes future upgrades slow and expensive. To fix
this, governments are encouraged to shift their focus from simply buying
software to building lasting public resources. This approach relies heavily on
adopting established open source software and shared standards. Instead of
just asking who owns the code, public institutions need to focus on who will
properly maintain, secure, and improve it over time. The root of the problem
frequently begins during the purchasing process, where contracts often
prioritize fast delivery over lasting usability and easy maintenance. By
changing how they buy technology, public agencies can demand software that is
built to be shared across multiple departments, preventing wasted effort and
redundant spending. Furthermore, building inclusive, accessible, and efficient
digital services from the beginning rather than treating these features as
afterthoughts ensures the technology serves all citizens effectively.
Ultimately, every new digital investment represents a choice. Governments can
either continue piling on maintenance burdens for future teams, or they can
invest in shared, adaptable technology that actively strengthens their digital
capacity for years.Digital Twins for Operational Resilience
 Adam Mattis first used digital twin technology in 2018 for a custom bicycle
company. Instead of physically building endless prototypes, he successfully
modeled carbon fiber frames in software to test critical characteristics like
flexibility and weight distribution before construction began. At the time,
creating a digital twin was expensive, quite difficult, and mostly confined to
specialized manufacturing circles. However, the technology has recently
evolved from an obscure engineering tool into an essential business practice.
The high costs and immense complexity that once intimidated companies have
decreased significantly, aided by cheaper physical sensors and the growing
need to prove the value of recent investments in artificial intelligence and
data center infrastructure. Today, digital twins are no longer just static
simulations used before building something new. They have successfully become
live, continuous monitoring systems that act as crucial operational
fail-safes. By mirroring a physical system in real time, a digital twin can
detect subtle performance drifts well before a major failure ever occurs.
Real-world systems rarely fail instantly with sudden, blaring alarms; instead,
they slowly degrade over time. Digital twins allow organizations to spot this
hidden deterioration early, transforming how businesses maintain system
resilience and confidently prevent catastrophic operational breakdowns.
Adam Mattis first used digital twin technology in 2018 for a custom bicycle
company. Instead of physically building endless prototypes, he successfully
modeled carbon fiber frames in software to test critical characteristics like
flexibility and weight distribution before construction began. At the time,
creating a digital twin was expensive, quite difficult, and mostly confined to
specialized manufacturing circles. However, the technology has recently
evolved from an obscure engineering tool into an essential business practice.
The high costs and immense complexity that once intimidated companies have
decreased significantly, aided by cheaper physical sensors and the growing
need to prove the value of recent investments in artificial intelligence and
data center infrastructure. Today, digital twins are no longer just static
simulations used before building something new. They have successfully become
live, continuous monitoring systems that act as crucial operational
fail-safes. By mirroring a physical system in real time, a digital twin can
detect subtle performance drifts well before a major failure ever occurs.
Real-world systems rarely fail instantly with sudden, blaring alarms; instead,
they slowly degrade over time. Digital twins allow organizations to spot this
hidden deterioration early, transforming how businesses maintain system
resilience and confidently prevent catastrophic operational breakdowns.Code Is Cheap. Judgment Isn’t
 Artificial intelligence has drastically reduced the cost and time required to
write software. While this increased speed seems like a massive benefit, it
actually hides a dangerous trap for companies. Historically, the slow process
of writing code naturally prevented unnecessary ideas from being built.
Because it took days to create a single feature, developers had to carefully
consider if it was truly worth the effort. Today, artificial intelligence can
generate that exact same code in minutes, completely removing this natural
filter. Consequently, teams are rapidly filling their systems with unnecessary
features, leading to severe code bloat. This unchecked growth creates massive,
fragile systems that no single person fully understands. The true expense of
software is never creating it, but rather owning and maintaining it over time.
Every line of code, whether written in ten minutes or two days, requires
ongoing testing, updating, and explanation to new employees. Therefore, the
most valuable resource in software development is no longer coding speed, but
careful human judgment. Leaders must aggressively evaluate whether a feature
should even exist before allowing the machine to build it. Protecting a
system's simplicity is the only guaranteed way to maintain speed over the long
term.
Artificial intelligence has drastically reduced the cost and time required to
write software. While this increased speed seems like a massive benefit, it
actually hides a dangerous trap for companies. Historically, the slow process
of writing code naturally prevented unnecessary ideas from being built.
Because it took days to create a single feature, developers had to carefully
consider if it was truly worth the effort. Today, artificial intelligence can
generate that exact same code in minutes, completely removing this natural
filter. Consequently, teams are rapidly filling their systems with unnecessary
features, leading to severe code bloat. This unchecked growth creates massive,
fragile systems that no single person fully understands. The true expense of
software is never creating it, but rather owning and maintaining it over time.
Every line of code, whether written in ten minutes or two days, requires
ongoing testing, updating, and explanation to new employees. Therefore, the
most valuable resource in software development is no longer coding speed, but
careful human judgment. Leaders must aggressively evaluate whether a feature
should even exist before allowing the machine to build it. Protecting a
system's simplicity is the only guaranteed way to maintain speed over the long
term.
The cleanup trap: Stop asking RAG to fix bad data
 Many enterprise artificial intelligence projects fail before ever reaching
full operation, and technical leaders frequently blame the models themselves
for these disappointing setbacks. However, the true culprit is usually a
flawed data foundation. This situation is known as the cleanup trap, which is
the false belief that a company can feed messy, inconsistent information into
a retrieval system and easily fix it later. When a system receives raw,
unvalidated data directly from operational storage, the resulting database
inherits all the original noise, duplicate records, and conflicting details.
Modifying the model or adjusting basic text prompts cannot adequately
compensate for a broken information pipeline. If the foundation is
compromised, the application will simply fail to deliver reliable results. To
solve this problem, teams must stop treating data quality as a final step.
Instead, they need to validate information early, establish automated checks
for unusual patterns, and handle security rules strictly within the data
infrastructure rather than relying on the model to enforce them. As artificial
intelligence matures, success depends far less on picking the perfect model
and far more on maintaining strict engineering discipline. Reliable systems
require treating data infrastructure as the core foundation for enterprise
intelligence rather than just a background function.
Many enterprise artificial intelligence projects fail before ever reaching
full operation, and technical leaders frequently blame the models themselves
for these disappointing setbacks. However, the true culprit is usually a
flawed data foundation. This situation is known as the cleanup trap, which is
the false belief that a company can feed messy, inconsistent information into
a retrieval system and easily fix it later. When a system receives raw,
unvalidated data directly from operational storage, the resulting database
inherits all the original noise, duplicate records, and conflicting details.
Modifying the model or adjusting basic text prompts cannot adequately
compensate for a broken information pipeline. If the foundation is
compromised, the application will simply fail to deliver reliable results. To
solve this problem, teams must stop treating data quality as a final step.
Instead, they need to validate information early, establish automated checks
for unusual patterns, and handle security rules strictly within the data
infrastructure rather than relying on the model to enforce them. As artificial
intelligence matures, success depends far less on picking the perfect model
and far more on maintaining strict engineering discipline. Reliable systems
require treating data infrastructure as the core foundation for enterprise
intelligence rather than just a background function.