Quote for the day:
“The more you loose yourself in something bigger than yourself, the more energy you will have.” - Norman Vincent Peale
🎧 Listen to this digest on YouTube Music
▶ Play Audio DigestDuration: 17 mins • Perfect for listening on the go.
The architectural decision shaping enterprise AI
 In "The architectural decision shaping enterprise AI," Shail Khiyara argues
that the long-term success of enterprise AI initiatives hinges on an
often-overlooked architectural choice: how a system finds, relates, and
reasons over information. The article outlines three primary patterns—vector
embeddings, knowledge graphs, and context graphs—each offering unique
advantages and trade-offs. Vector embeddings excel at identifying semantically
similar unstructured data, making them ideal for rapid RAG deployments, yet
they lack deep relational understanding. Knowledge graphs provide precise,
traceable answers by mapping explicit relationships between entities, though
they are resource-intensive to maintain. Crucially, Khiyara introduces context
graphs, which capture the dynamic reasoning behind decisions to ensure
continuity across multi-step workflows. Unlike static models, context graphs
treat reasoning as a first-class data artifact, allowing AI to understand the
"why" behind previous actions. The most effective enterprise strategies do not
choose one in isolation but instead layer these patterns to balance speed,
precision, and contextual awareness. Ultimately, Khiyara warns that leaving
these decisions to default configurations leads to "confident mistakes" and
trust erosion. For CIOs, intentional architectural design is not just a
technical necessity but a fundamental business imperative to transition from
isolated pilots to scalable, reliable AI ecosystems that deliver genuine
organizational value.
In "The architectural decision shaping enterprise AI," Shail Khiyara argues
that the long-term success of enterprise AI initiatives hinges on an
often-overlooked architectural choice: how a system finds, relates, and
reasons over information. The article outlines three primary patterns—vector
embeddings, knowledge graphs, and context graphs—each offering unique
advantages and trade-offs. Vector embeddings excel at identifying semantically
similar unstructured data, making them ideal for rapid RAG deployments, yet
they lack deep relational understanding. Knowledge graphs provide precise,
traceable answers by mapping explicit relationships between entities, though
they are resource-intensive to maintain. Crucially, Khiyara introduces context
graphs, which capture the dynamic reasoning behind decisions to ensure
continuity across multi-step workflows. Unlike static models, context graphs
treat reasoning as a first-class data artifact, allowing AI to understand the
"why" behind previous actions. The most effective enterprise strategies do not
choose one in isolation but instead layer these patterns to balance speed,
precision, and contextual awareness. Ultimately, Khiyara warns that leaving
these decisions to default configurations leads to "confident mistakes" and
trust erosion. For CIOs, intentional architectural design is not just a
technical necessity but a fundamental business imperative to transition from
isolated pilots to scalable, reliable AI ecosystems that deliver genuine
organizational value.The Evidence and Control Layer for Enterprise AI
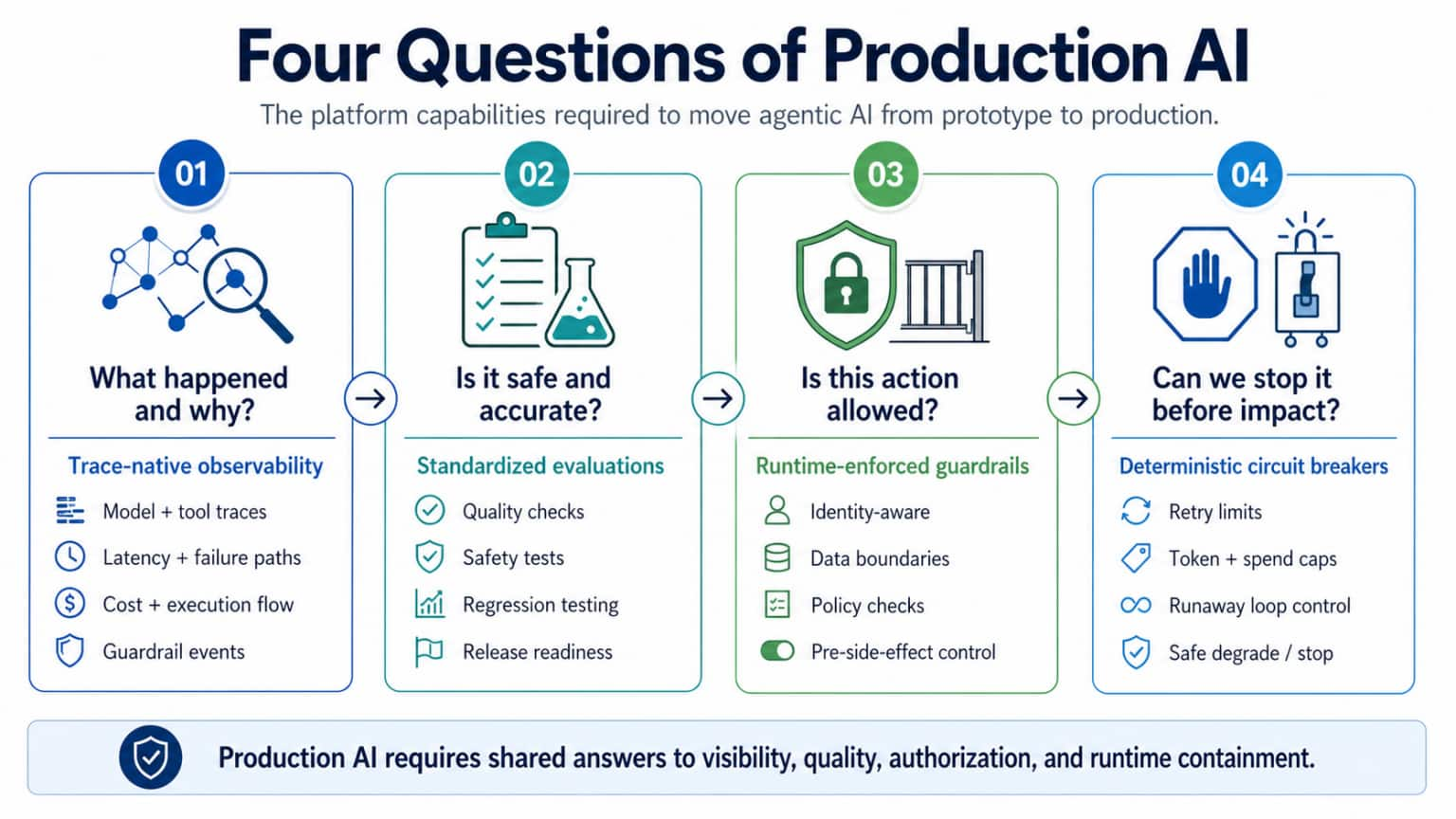 The article "The Evidence and Control Layer for Enterprise AI" by Kishore
Pusukuri argues that the transition from AI prototypes to production requires
a robust architectural layer to manage the inherent unpredictability of
agentic systems. This "Evidence and Control Layer" acts as a shared platform
substrate that mediates between agentic workloads and enterprise resources,
shifting governance from retrospective reviews to proactive, in-path execution
controls. The framework is built upon three core pillars: trace-native
observability, continuous trace-linked evaluations, and runtime-enforced
guardrails. Unlike traditional logging, trace-native observability captures
the complete execution path and decision context, providing the foundation for
operational trust. Continuous evaluations act as quality gates, while runtime
guardrails evaluate proposed actions—such as tool calls or data
transfers—before side effects occur, ensuring safety and compliance in
real-time. By formalizing policy-as-code and generating structured evidence
events, the layer ensures that every material action is explicit, auditable,
and cost-bounded. Ultimately, this centralized approach accelerates enterprise
adoption by providing reusable governance defaults, effectively closing the
"stochastic gap" and transforming black-box agents into trusted, scalable
enterprise assets that operate with clear authority and within defined budget
constraints.
The article "The Evidence and Control Layer for Enterprise AI" by Kishore
Pusukuri argues that the transition from AI prototypes to production requires
a robust architectural layer to manage the inherent unpredictability of
agentic systems. This "Evidence and Control Layer" acts as a shared platform
substrate that mediates between agentic workloads and enterprise resources,
shifting governance from retrospective reviews to proactive, in-path execution
controls. The framework is built upon three core pillars: trace-native
observability, continuous trace-linked evaluations, and runtime-enforced
guardrails. Unlike traditional logging, trace-native observability captures
the complete execution path and decision context, providing the foundation for
operational trust. Continuous evaluations act as quality gates, while runtime
guardrails evaluate proposed actions—such as tool calls or data
transfers—before side effects occur, ensuring safety and compliance in
real-time. By formalizing policy-as-code and generating structured evidence
events, the layer ensures that every material action is explicit, auditable,
and cost-bounded. Ultimately, this centralized approach accelerates enterprise
adoption by providing reusable governance defaults, effectively closing the
"stochastic gap" and transforming black-box agents into trusted, scalable
enterprise assets that operate with clear authority and within defined budget
constraints.Organizational Culture As An Operating System, Not A Values System
 In the article "Organizational Culture As An Operating System, Not A Values
System," the author argues that the traditional definition of culture as a
static set of internal values is no longer sufficient in a hyper-connected
world. Modern organizational culture must be reframed as a dynamic operating
system that bridges internal decision-making with external community
engagement. While internal culture dictates how information flows and
authority is exercised, external culture defines how a brand interacts with
decentralized movements in art, fashion, and social identity. The disconnect
often arises because corporate hierarchies prioritize control and
predictability, whereas external cultural trends move at a high velocity from
the periphery. To remain relevant, organizations must shift from a "broadcast"
model to one of "co-creation," where authority is distributed to those closest
to social signals and speed is enabled by trust rather than bureaucratic
process. By treating culture with the same rigor as any other core business
function, leaders can diagnose internal friction and align incentives to
ensure the organization moves at the "speed of culture." Ultimately, success
depends on building internal systems that allow companies to participate in
and shape cultural conversations in real time, moving beyond corporate
manifestos to authentic community collaboration.
In the article "Organizational Culture As An Operating System, Not A Values
System," the author argues that the traditional definition of culture as a
static set of internal values is no longer sufficient in a hyper-connected
world. Modern organizational culture must be reframed as a dynamic operating
system that bridges internal decision-making with external community
engagement. While internal culture dictates how information flows and
authority is exercised, external culture defines how a brand interacts with
decentralized movements in art, fashion, and social identity. The disconnect
often arises because corporate hierarchies prioritize control and
predictability, whereas external cultural trends move at a high velocity from
the periphery. To remain relevant, organizations must shift from a "broadcast"
model to one of "co-creation," where authority is distributed to those closest
to social signals and speed is enabled by trust rather than bureaucratic
process. By treating culture with the same rigor as any other core business
function, leaders can diagnose internal friction and align incentives to
ensure the organization moves at the "speed of culture." Ultimately, success
depends on building internal systems that allow companies to participate in
and shape cultural conversations in real time, moving beyond corporate
manifestos to authentic community collaboration.Re‑Architecting Capability for AI: Governance, SMEs, and the Talent Pipeline Paradox
The article "Re-architecting Capability for AI Governance: SMEs and the Talent
Pipeline Paradox" examines the profound obstacles small and medium-sized
enterprises encounter while attempting to establish formal AI oversight.
Central to the discussion is the "talent pipeline paradox," which describes
how the concentration of AI expertise within large technology firms creates a
vacuum that leaves smaller organizations vulnerable. To address this, the
author advocates for a strategic shift from talent acquisition to capability
re-architecting. Rather than competing for scarce high-end specialists, SMEs
should integrate AI governance into their existing business architecture
through modular and risk-based frameworks. This approach emphasizes the
importance of leveraging cross-functional internal teams, automated tools, and
external partnerships to manage algorithmic risks effectively. By focusing on
scalable governance patterns and clear accountability, SMEs can achieve
ethical and regulatory compliance without the overhead of massive
administrative departments. Ultimately, the piece suggests that the key to
overcoming resource limitations lies in structural agility and the
democratization of governance tasks. This enables smaller firms to harness the
transformative power of artificial intelligence safely while maintaining a
competitive edge in an increasingly automated global marketplace where talent
remains the ultimate bottleneck.
The AI scaffolding layer is collapsing. LlamaIndex's CEO explains what survives
 In this VentureBeat interview, LlamaIndex CEO Jerry Liu explores the
significant transformation occurring within the "AI scaffolding" layer—the
software stack connecting large language models to external data and
applications. As frontier models increasingly incorporate native reasoning and
retrieval capabilities, Liu suggests that simplistic RAG wrappers are rapidly
losing their utility, leading to a "collapse" of the middle layer. To survive
this consolidation, infrastructure tools must evolve from thin architectural
shells into robust systems that manage complex data pipelines and orchestrate
sophisticated agentic workflows. Liu emphasizes that while base models are
becoming more powerful, they still lack the specialized, proprietary context
required for high-stakes enterprise tasks. Consequently, the future of AI
development lies in solving "hard" data problems, such as handling
heterogeneous sources and ensuring data quality at scale. Developers are
encouraged to pivot away from basic integration toward building deep,
specialized intelligence layers that provide the structured context models
inherently lack. Ultimately, the survival of platforms like LlamaIndex depends
on their ability to offer advanced orchestration and data management that
transcends the capabilities of the base models alone, marking a shift toward
more resilient and professionalized AI engineering.
In this VentureBeat interview, LlamaIndex CEO Jerry Liu explores the
significant transformation occurring within the "AI scaffolding" layer—the
software stack connecting large language models to external data and
applications. As frontier models increasingly incorporate native reasoning and
retrieval capabilities, Liu suggests that simplistic RAG wrappers are rapidly
losing their utility, leading to a "collapse" of the middle layer. To survive
this consolidation, infrastructure tools must evolve from thin architectural
shells into robust systems that manage complex data pipelines and orchestrate
sophisticated agentic workflows. Liu emphasizes that while base models are
becoming more powerful, they still lack the specialized, proprietary context
required for high-stakes enterprise tasks. Consequently, the future of AI
development lies in solving "hard" data problems, such as handling
heterogeneous sources and ensuring data quality at scale. Developers are
encouraged to pivot away from basic integration toward building deep,
specialized intelligence layers that provide the structured context models
inherently lack. Ultimately, the survival of platforms like LlamaIndex depends
on their ability to offer advanced orchestration and data management that
transcends the capabilities of the base models alone, marking a shift toward
more resilient and professionalized AI engineering.Guide for Designing Highly Scalable Systems
The "Guide for Designing Highly Scalable Systems" by GeeksforGeeks provides a
comprehensive roadmap for building architectures capable of managing
increasing traffic and data volume without performance degradation.
Scalability is defined as a system’s ability to grow efficiently while
maintaining stability and fast response times. The guide highlights two
primary scaling strategies: vertical scaling, which involves enhancing a
single server’s capacity, and horizontal scaling, which distributes workloads
across multiple machines. To achieve high scalability, the article emphasizes
the importance of architectural decomposition and loose coupling, often
implemented through microservices or service-oriented architectures. Key
components discussed include load balancers for even traffic distribution,
caching mechanisms like Redis to reduce backend load, and advanced data
management techniques such as sharding and replication to prevent database
bottlenecks. Furthermore, the guide covers essential architectural patterns
like CQRS and distributed systems to improve fault tolerance and resource
utilization. Modern applications must account for various non-functional
requirements such as availability and consistency while scaling. By
prioritizing stateless designs and avoiding single points of failure,
organizations can create robust systems that handle peak usage and
unpredictable growth effectively. Ultimately, designing for scalability
requires balancing cost, performance, and complexity to ensure long-term
reliability in a dynamic digital landscape.
Why Debugging is Harder than Writing Code?
 The article "Why Debugging is Harder than Writing Code" from BetterBugs
examines the fundamental reasons why developers spend nearly half their time
fixing issues rather than creating new features. The core difficulty lies in
the disparity between the "happy path" of initial development and the
exponential state space of potential failures. While writing code involves
building a single successful outcome, debugging requires navigating a
combinatorially vast range of unexpected inputs and conditions. This process
imposes a significant cognitive load, as developers must maintain a massive
context window—often jumping between different files, servers, and logs—which
incurs heavy switching costs. Furthermore, modern complexities like
distributed systems, non-deterministic concurrency, and discrepancies between
local and production environments add layers of friction. In concurrent
systems, for instance, the mere act of observing a bug can change the timing
and make the issue disappear. Ultimately, the article argues that debugging is
more demanding because it forces engineers to move beyond theoretical models
and confront the messy realities of hardware limits, memory leaks, and network
latency. To manage these challenges, the author suggests that teams must
prioritize observability and evidence-based reporting tools to bridge the gap
between mental models and actual system behavior, ensuring more predictable
software lifecycles.
The article "Why Debugging is Harder than Writing Code" from BetterBugs
examines the fundamental reasons why developers spend nearly half their time
fixing issues rather than creating new features. The core difficulty lies in
the disparity between the "happy path" of initial development and the
exponential state space of potential failures. While writing code involves
building a single successful outcome, debugging requires navigating a
combinatorially vast range of unexpected inputs and conditions. This process
imposes a significant cognitive load, as developers must maintain a massive
context window—often jumping between different files, servers, and logs—which
incurs heavy switching costs. Furthermore, modern complexities like
distributed systems, non-deterministic concurrency, and discrepancies between
local and production environments add layers of friction. In concurrent
systems, for instance, the mere act of observing a bug can change the timing
and make the issue disappear. Ultimately, the article argues that debugging is
more demanding because it forces engineers to move beyond theoretical models
and confront the messy realities of hardware limits, memory leaks, and network
latency. To manage these challenges, the author suggests that teams must
prioritize observability and evidence-based reporting tools to bridge the gap
between mental models and actual system behavior, ensuring more predictable
software lifecycles.Cybersecurity: Board oversight of operational resilience planning
The A&O Shearman guidance emphasizes that as cyberattacks grow more
sophisticated and regulatory scrutiny intensifies, boards must adopt a
proactive stance toward operational resilience. With the emergence of
unpredictable criminal gangs and AI-driven threats, it is no longer sufficient
to treat cybersecurity as a purely technical issue; it is a critical
governance priority. To exercise effective oversight, boards should appoint
dedicated individuals or committees to monitor cyber risks and ensure that
Business Continuity and Disaster Recovery (BCDR) plans are robust, defensible,
and accessible offline. Practical preparations must include clear
decision-making protocols and alternative communication channels, such as
Signal or WhatsApp, for use during systems outages. Additionally, leadership
should oversee the development of pre-approved communication templates for
stakeholders and define strict Recovery Time Objectives (RTOs). A cornerstone
of this framework is the implementation of regular tabletop exercises and
technical recovery drills that involve third-party providers to identify
vulnerabilities. By documenting these proactive measures and integrating
lessons learned into evolving strategies, boards can meet regulatory
expectations for evidence-based oversight. Ultimately, this comprehensive
approach to resilience planning helps organizations minimize the risk of
material revenue loss and navigate the complexities of a volatile global
digital landscape.
 In "Beyond the Region," Flavia Ballabene argues that software architects must
evolve their definition of resilience from surviving mechanical failures to
navigating "Sovereign Fault Domains." Traditionally, redundancy across
Availability Zones addressed physical infrastructure outages; however, modern
geopolitical shifts and evolving privacy laws now create "blast radii" where
data becomes legally trapped or AI models suddenly non-compliant. Ballabene
highlights an "AI-HR Integrity Gap," where centralized systems fail to account
for regional jurisdictional constraints. To bridge this, she proposes shifting
toward sovereignty-aware infrastructures. Key strategies include Managed
Sovereign Cloud Models, which leverage localized partner-led controls like
S3NS or T-Systems, and Cell-Based Regional Architectures, which deploy
independent stacks for each major market to eliminate reliance on a global
control plane. These approaches allow organizations to maintain operational
continuity even when specific regions face regulatory upheavals. By auditing
AI dependency graphs and prioritizing data residency, executives can transform
compliance from a burden into a competitive advantage. Ultimately, the article
suggests that in a fragmented global cloud, the most resilient HR and
technology stacks are those built on digital trust and localized integrity,
ensuring they remain robust against both technical glitches and the
unpredictable tides of international policy.
In "Beyond the Region," Flavia Ballabene argues that software architects must
evolve their definition of resilience from surviving mechanical failures to
navigating "Sovereign Fault Domains." Traditionally, redundancy across
Availability Zones addressed physical infrastructure outages; however, modern
geopolitical shifts and evolving privacy laws now create "blast radii" where
data becomes legally trapped or AI models suddenly non-compliant. Ballabene
highlights an "AI-HR Integrity Gap," where centralized systems fail to account
for regional jurisdictional constraints. To bridge this, she proposes shifting
toward sovereignty-aware infrastructures. Key strategies include Managed
Sovereign Cloud Models, which leverage localized partner-led controls like
S3NS or T-Systems, and Cell-Based Regional Architectures, which deploy
independent stacks for each major market to eliminate reliance on a global
control plane. These approaches allow organizations to maintain operational
continuity even when specific regions face regulatory upheavals. By auditing
AI dependency graphs and prioritizing data residency, executives can transform
compliance from a burden into a competitive advantage. Ultimately, the article
suggests that in a fragmented global cloud, the most resilient HR and
technology stacks are those built on digital trust and localized integrity,
ensuring they remain robust against both technical glitches and the
unpredictable tides of international policy.
Beyond the Region: Architecting for Sovereign Fault Domains and the AI-HR Integrity Gap
In "Beyond the Region," Flavia Ballabene argues that software architects must
evolve their definition of resilience from surviving mechanical failures to
navigating "Sovereign Fault Domains." Traditionally, redundancy across
Availability Zones addressed physical infrastructure outages; however, modern
geopolitical shifts and evolving privacy laws now create "blast radii" where
data becomes legally trapped or AI models suddenly non-compliant. Ballabene
highlights an "AI-HR Integrity Gap," where centralized systems fail to account
for regional jurisdictional constraints. To bridge this, she proposes shifting
toward sovereignty-aware infrastructures. Key strategies include Managed
Sovereign Cloud Models, which leverage localized partner-led controls like
S3NS or T-Systems, and Cell-Based Regional Architectures, which deploy
independent stacks for each major market to eliminate reliance on a global
control plane. These approaches allow organizations to maintain operational
continuity even when specific regions face regulatory upheavals. By auditing
AI dependency graphs and prioritizing data residency, executives can transform
compliance from a burden into a competitive advantage. Ultimately, the article
suggests that in a fragmented global cloud, the most resilient HR and
technology stacks are those built on digital trust and localized integrity,
ensuring they remain robust against both technical glitches and the
unpredictable tides of international policy.






