Quote for the day:
"The real leader has no need to lead - he is content to point the way." -- Henry Miller
Four important lessons about context engineering
 Modern LLMs operate with context windows ranging from 8K to 200K+ tokens, with
some models claiming even larger windows. However, several technical realities
shape how we should think about context. ... Research has consistently shown
that LLMs experience attention degradation in the middle portions of long
contexts. Models perform best with information placed at the beginning or end
of the context window. This isn’t a bug. It’s an artifact of how transformer
architectures process sequences. ... Context length impacts latency and cost
quadratically in many architectures. A 100K token context doesn’t cost 10x a
10K context, it can cost 100x in compute terms, even if providers don’t pass
all costs to users. ... The most important insight: more context isn’t better
context. In production systems, we’ve seen dramatic improvements by reducing
context size and increasing relevance. ... LLMs respond better to structured
context than unstructured dumps. XML tags, markdown headers, and clear
delimiters help models parse and attend to the right information. ... Organize
context by importance and relevance, not chronologically or alphabetically.
Place critical information early and late in the context window. ... Each LLM
call is stateless. This isn’t a limitation to overcome, but an architectural
choice to embrace. Rather than trying to maintain massive conversation
histories, implement smart context management
Modern LLMs operate with context windows ranging from 8K to 200K+ tokens, with
some models claiming even larger windows. However, several technical realities
shape how we should think about context. ... Research has consistently shown
that LLMs experience attention degradation in the middle portions of long
contexts. Models perform best with information placed at the beginning or end
of the context window. This isn’t a bug. It’s an artifact of how transformer
architectures process sequences. ... Context length impacts latency and cost
quadratically in many architectures. A 100K token context doesn’t cost 10x a
10K context, it can cost 100x in compute terms, even if providers don’t pass
all costs to users. ... The most important insight: more context isn’t better
context. In production systems, we’ve seen dramatic improvements by reducing
context size and increasing relevance. ... LLMs respond better to structured
context than unstructured dumps. XML tags, markdown headers, and clear
delimiters help models parse and attend to the right information. ... Organize
context by importance and relevance, not chronologically or alphabetically.
Place critical information early and late in the context window. ... Each LLM
call is stateless. This isn’t a limitation to overcome, but an architectural
choice to embrace. Rather than trying to maintain massive conversation
histories, implement smart context managementWhat Fuels AI Code Risks and How DevSecOps Can Secure Pipelines
 AI-generated code refers to code snippets or entire functions produced by
Machine Learning models trained on vast datasets. While these models can
enhance developer productivity by providing quick solutions, they often lack
the nuanced understanding of security implications inherent in manual coding
practices. ... Establishing secure pipelines is the backbone of any resilient
development strategy. When code flows rapidly from development to production,
every step becomes a potential entry point for vulnerabilities. Without
careful controls, even well-intentioned automation can allow flawed or
insecure code to slip through, creating risks that may only surface once the
application is live. A secure pipeline ensures that every commit, every
integration, and every deployment undergo consistent security scrutiny,
reducing the likelihood of breaches and protecting both organizational assets
and user trust. Security in the pipeline begins at the earliest stages of
development. By embedding continuous testing, teams can identify
vulnerabilities before they propagate, identifying issues that traditional
post-development checks often miss. This proactive approach allows security to
move in tandem with development rather than trailing behind it, ensuring that
speed does not come at the expense of safety.
AI-generated code refers to code snippets or entire functions produced by
Machine Learning models trained on vast datasets. While these models can
enhance developer productivity by providing quick solutions, they often lack
the nuanced understanding of security implications inherent in manual coding
practices. ... Establishing secure pipelines is the backbone of any resilient
development strategy. When code flows rapidly from development to production,
every step becomes a potential entry point for vulnerabilities. Without
careful controls, even well-intentioned automation can allow flawed or
insecure code to slip through, creating risks that may only surface once the
application is live. A secure pipeline ensures that every commit, every
integration, and every deployment undergo consistent security scrutiny,
reducing the likelihood of breaches and protecting both organizational assets
and user trust. Security in the pipeline begins at the earliest stages of
development. By embedding continuous testing, teams can identify
vulnerabilities before they propagate, identifying issues that traditional
post-development checks often miss. This proactive approach allows security to
move in tandem with development rather than trailing behind it, ensuring that
speed does not come at the expense of safety. The New Role of Enterprise Architecture in the AI Era
 Traditional architecture assumes predictability in which once the code has
shipped, systems behave in a standard way. On the contrary, AI breaks that
assumption completely, given that the machine learning models continuously
change as data evolves and model performance keeps fluctuating as every new
dataset gets added. ... Architecture isn’t just a phase in the AI era; rather
it’s a continuous cycle that must operate across various interconnected stages
that follow well-defined phases. This process starts with discovery, where the
teams assess and identify AI opportunities that are directly linked to the
business objectives. Engage early with business leadership to define clear
outcomes. Next comes design, where architects create modular blueprints for
data pipelines and model deployment by reusing the proven patterns. In the
delivery phase, teams execute iteratively with governance built in from the
onset. Ethics, compliance and observability should be baked into the
workflows, not added later as afterthoughts. Finally, adaptation keeps the
system learning. Models are monitored, retrained and optimized continuously,
with feedback loops connecting system behavior back to business metrics and
KPIs (key performance indicators). When architecture operates this way, it
becomes a living ecosystem that learns, adapts and improves with every
iteration.
Traditional architecture assumes predictability in which once the code has
shipped, systems behave in a standard way. On the contrary, AI breaks that
assumption completely, given that the machine learning models continuously
change as data evolves and model performance keeps fluctuating as every new
dataset gets added. ... Architecture isn’t just a phase in the AI era; rather
it’s a continuous cycle that must operate across various interconnected stages
that follow well-defined phases. This process starts with discovery, where the
teams assess and identify AI opportunities that are directly linked to the
business objectives. Engage early with business leadership to define clear
outcomes. Next comes design, where architects create modular blueprints for
data pipelines and model deployment by reusing the proven patterns. In the
delivery phase, teams execute iteratively with governance built in from the
onset. Ethics, compliance and observability should be baked into the
workflows, not added later as afterthoughts. Finally, adaptation keeps the
system learning. Models are monitored, retrained and optimized continuously,
with feedback loops connecting system behavior back to business metrics and
KPIs (key performance indicators). When architecture operates this way, it
becomes a living ecosystem that learns, adapts and improves with every
iteration.Quenching Data Center Thirst for Power Now Is Solvable Problem
 “Slowing data center growth or prohibiting grid connection is a short-sighted
approach that embraces a scarcity mentality,” argued Wannie Park, CEO and
founder of Pado AI, an energy management and AI orchestration company, in
Malibu, Calif. “The explosive growth of AI and digital infrastructure is a
massive engine for economic, scientific, and industrial progress,” he told
TechNewsWorld. “The focus should not be on stifling this essential innovation,
but on making data centers active, supportive participants in the energy
ecosystem.” ... Planning for the full lifecycle of a data center’s power needs —
from construction through long-term operations — is essential, he continued.
This approach includes having solutions in place that can keep facilities
operational during periods of limited grid availability, major weather events,
or unexpected demand pressures, he said. ... The ITIF report also called for the
United States to squeeze more power from the existing grid without negatively
impacting customers, while also building new capacity. New technology can
increase supply from existing transmission lines and generators, the report
explained, which can bridge the transition to an expanded physical grid. On the
demand side, it added, there is spare capacity, but not at peak times. It
suggested that large users, such as data centers, be encouraged to shift their
demand to off-peak periods, without damaging their customers. Grids do some of
that already, it noted, but much more is needed.
“Slowing data center growth or prohibiting grid connection is a short-sighted
approach that embraces a scarcity mentality,” argued Wannie Park, CEO and
founder of Pado AI, an energy management and AI orchestration company, in
Malibu, Calif. “The explosive growth of AI and digital infrastructure is a
massive engine for economic, scientific, and industrial progress,” he told
TechNewsWorld. “The focus should not be on stifling this essential innovation,
but on making data centers active, supportive participants in the energy
ecosystem.” ... Planning for the full lifecycle of a data center’s power needs —
from construction through long-term operations — is essential, he continued.
This approach includes having solutions in place that can keep facilities
operational during periods of limited grid availability, major weather events,
or unexpected demand pressures, he said. ... The ITIF report also called for the
United States to squeeze more power from the existing grid without negatively
impacting customers, while also building new capacity. New technology can
increase supply from existing transmission lines and generators, the report
explained, which can bridge the transition to an expanded physical grid. On the
demand side, it added, there is spare capacity, but not at peak times. It
suggested that large users, such as data centers, be encouraged to shift their
demand to off-peak periods, without damaging their customers. Grids do some of
that already, it noted, but much more is needed.
A Waste(d) Opportunity: How can the UK utilize data center waste heat?
Walking into the data hall, you are struck by the heat resonating from the numerous server racks, each capable of handling up to 20kW of compute. However, rather than allowing this heat to dissipate into the atmosphere, the team at QMUL had another plan. Instead, in partnership with Schneider Electric, the university deployed a novel heat reuse system. ... Large water cylinders across campus act like thermal batteries, storing hot water overnight when compute needs are constant, but demand is low, then releasing it in the morning rush. As one project lead put it, there is “no mechanical rejection. All the heat we generate here is used. The gas boilers are off or dialed down - the computing heat takes over completely.” At full capacity, the data center could supply the equivalent of nearly 4 million ten-minute showers per year. ... Walking out, it’s easy to see why Queen Mary’s project is being held up as a model for others. In the UK, however, the project is somewhat of an oddity, but through the lens of QMUL you can see a glimpse of the future, where compute is not only solving the mysteries of our universe but heating our morning showers. The question remains, though, why data center waste heat utilization projects in the UK are few and far between, and how the country can catch up to regions such as the Nordics, which has embedded waste heat utilization into the planning and construction of its data center sector.Redefining cyber-resilience for a new era
 The biggest vulnerability is still the human factor, not the technology. Many
companies invest in expensive tools but overlook the behaviour and mindset of
their teams. In regions experiencing rapid digital growth, that gap becomes even
more visible. Phishing, credential theft and shadow IT remain common ways
attackers gain access. What’s needed is a shift in culture. Cybersecurity should
be seen as a shared responsibility, embedded in daily routines, not as a
one-time technical solution. True resilience begins with awareness, leadership
and clarity at all levels of the organisation. ... Leaders play a crucial role
in shaping that future. They need to understand that cybersecurity is not about
fear, but about clarity and long-term thinking. It is part of strategic
leadership. The leaders who make the biggest impact will be the ones who see
cybersecurity as cultural, not just technical. They will prioritise
transparency, invest in ethical and explainable technology, and build teams that
carry these values forward. ... Artificial Intelligence is already transforming
how we detect and respond to threats, but the more important shift is about
ownership. Who controls the infrastructure, the models and the data? Centralised
AI, controlled by a few major companies, creates dependence and limits
transparency. It becomes harder to know what drives decisions, how data is used
and where vulnerabilities might exist.
The biggest vulnerability is still the human factor, not the technology. Many
companies invest in expensive tools but overlook the behaviour and mindset of
their teams. In regions experiencing rapid digital growth, that gap becomes even
more visible. Phishing, credential theft and shadow IT remain common ways
attackers gain access. What’s needed is a shift in culture. Cybersecurity should
be seen as a shared responsibility, embedded in daily routines, not as a
one-time technical solution. True resilience begins with awareness, leadership
and clarity at all levels of the organisation. ... Leaders play a crucial role
in shaping that future. They need to understand that cybersecurity is not about
fear, but about clarity and long-term thinking. It is part of strategic
leadership. The leaders who make the biggest impact will be the ones who see
cybersecurity as cultural, not just technical. They will prioritise
transparency, invest in ethical and explainable technology, and build teams that
carry these values forward. ... Artificial Intelligence is already transforming
how we detect and respond to threats, but the more important shift is about
ownership. Who controls the infrastructure, the models and the data? Centralised
AI, controlled by a few major companies, creates dependence and limits
transparency. It becomes harder to know what drives decisions, how data is used
and where vulnerabilities might exist.Building Your Geopolitical Firewall Before You Need One
 In today’s world, where regulators are rolling out data sovereignty and
localization initiatives that turn every cross-border workflow into a compliance
nightmare, this is no theoretical exercise. Service disruption has shifted from
possibility to inevitability, and geopolitical moves can shut down operations
overnight. For storage engineers and data infrastructure leaders, the challenge
goes beyond mere compliance – it’s about building genuine operational
independence before circumstances force your hand. ... The reality is messier
than any compliance framework suggests. Data sprawls everywhere, from edge,
cloud and core to laptops and mobile devices. Building walls around everything
does not offer true operational independence. Instead, it’s really about having
the data infrastructure flexibility to move workloads when regulations shift,
when geopolitical tensions escalate, or when a foreign government’s legislative
reach suddenly extends into your data center. ... When evaluating sovereign
solutions, storage engineers typically focus on SLAs and certifications.
However, Oostveen argues that the critical question is simpler and more
fundamental: who actually owns the solution or the service provider? “If you’re
truly sovereign, my view is that you (the solution provider) are a company that
is owned and operated exclusively within the borders of that particular
jurisdiction,” he explains.
In today’s world, where regulators are rolling out data sovereignty and
localization initiatives that turn every cross-border workflow into a compliance
nightmare, this is no theoretical exercise. Service disruption has shifted from
possibility to inevitability, and geopolitical moves can shut down operations
overnight. For storage engineers and data infrastructure leaders, the challenge
goes beyond mere compliance – it’s about building genuine operational
independence before circumstances force your hand. ... The reality is messier
than any compliance framework suggests. Data sprawls everywhere, from edge,
cloud and core to laptops and mobile devices. Building walls around everything
does not offer true operational independence. Instead, it’s really about having
the data infrastructure flexibility to move workloads when regulations shift,
when geopolitical tensions escalate, or when a foreign government’s legislative
reach suddenly extends into your data center. ... When evaluating sovereign
solutions, storage engineers typically focus on SLAs and certifications.
However, Oostveen argues that the critical question is simpler and more
fundamental: who actually owns the solution or the service provider? “If you’re
truly sovereign, my view is that you (the solution provider) are a company that
is owned and operated exclusively within the borders of that particular
jurisdiction,” he explains.
The 5 elements of a good cybersecurity risk assessment
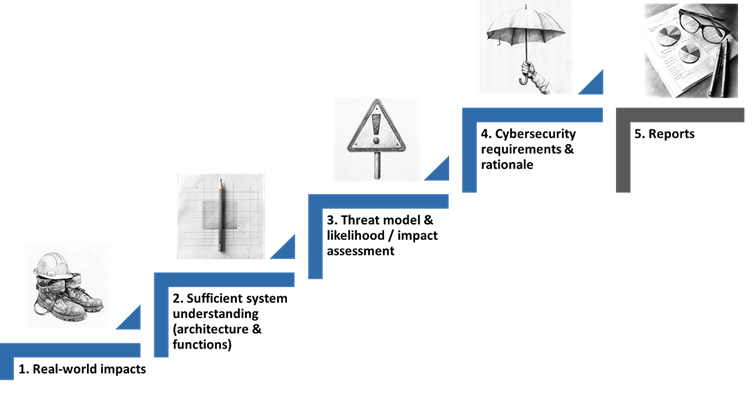 Companies can use a cybersecurity risk assessment to evaluate how effective
their security measures are. This provides a foundation for deciding which
security measures are important — and which are not. But also for deciding when
a product or system is secure enough and additional measures would be excessive.
When they’ve done enough cybersecurity. However, not every risk assessment
fulfills this promise. ... Too often, cybersecurity risk assessments take place
solely in cyberspace — but this doesn’t allow meaningful prioritizing of
requirements. “Server down” is annoying, but cyber systems never exist for their
own sake. That’s why risk assessments need a connection to real processes that
are mission critical for the organization — or perhaps not. ... Without system
understanding, there is no basis for attack modeling. Without attack modeling,
there is no basis for identifying the most important requirements. It shouldn’t
really be cybersecurity’s job to create system understanding. But since there is
often a lack of documentation in IT, OT, or for cyber systems in general,
cybersecurity is often left to provide it. And if cybersecurity is the first
team to finally create an overview of all cyber systems, then it’s a result that
is useful far beyond security risk assessment. ... Attack scenarios are a
necessary stepping stone to move your thinking from systems and real-world
impacts to meaningful security requirements — no more and no less.
Companies can use a cybersecurity risk assessment to evaluate how effective
their security measures are. This provides a foundation for deciding which
security measures are important — and which are not. But also for deciding when
a product or system is secure enough and additional measures would be excessive.
When they’ve done enough cybersecurity. However, not every risk assessment
fulfills this promise. ... Too often, cybersecurity risk assessments take place
solely in cyberspace — but this doesn’t allow meaningful prioritizing of
requirements. “Server down” is annoying, but cyber systems never exist for their
own sake. That’s why risk assessments need a connection to real processes that
are mission critical for the organization — or perhaps not. ... Without system
understanding, there is no basis for attack modeling. Without attack modeling,
there is no basis for identifying the most important requirements. It shouldn’t
really be cybersecurity’s job to create system understanding. But since there is
often a lack of documentation in IT, OT, or for cyber systems in general,
cybersecurity is often left to provide it. And if cybersecurity is the first
team to finally create an overview of all cyber systems, then it’s a result that
is useful far beyond security risk assessment. ... Attack scenarios are a
necessary stepping stone to move your thinking from systems and real-world
impacts to meaningful security requirements — no more and no less. Finding Strength in Code, Part 2: Lessons from Loss and the Power of Reflection
 Every problem usually has more than one solution. The engineers who grow the
fastest are the ones who can look at their own mistakes without ego, list what
they’re good at and what they're not, and then actually see multiple ways
forward. Same with life. A loss (a pet, a breakup, whatever) is a bug that
breaks your personal system. ... Solo debugging has limits. On sprawling
systems, we rally the squad—frontend, backend, QA—to converge faster. Similarly,
grief isn't meant for isolation. I've leaned on my network: a quick Slack thread
with empathetic colleagues or a vulnerability share in my dev community. It
distributes the load and uncovers blind spots you might miss on your own. ...
Once a problem is solved, it is essential to communicate the solution. The list
of lessons from that solution: some companies solve problems, but never put the
effort into documenting the process in a way that prevents them from happening
again. I know it is impossible to avoid problems, as it is impossible not to
make mistakes in our lives. The true inefficiency? Skipping the "why" and "how
next time." ... Borrowed from incident response, it's a structured debrief that
prevents recurrence without finger-pointing. In engineering, it ensures
resilience; in life, it builds emotional antifragility. There are endless
flavours of postmortems—simple Markdown outlines to full-blown docs—but the gold
standard is "blameless," focusing on systems over scapegoats.
Every problem usually has more than one solution. The engineers who grow the
fastest are the ones who can look at their own mistakes without ego, list what
they’re good at and what they're not, and then actually see multiple ways
forward. Same with life. A loss (a pet, a breakup, whatever) is a bug that
breaks your personal system. ... Solo debugging has limits. On sprawling
systems, we rally the squad—frontend, backend, QA—to converge faster. Similarly,
grief isn't meant for isolation. I've leaned on my network: a quick Slack thread
with empathetic colleagues or a vulnerability share in my dev community. It
distributes the load and uncovers blind spots you might miss on your own. ...
Once a problem is solved, it is essential to communicate the solution. The list
of lessons from that solution: some companies solve problems, but never put the
effort into documenting the process in a way that prevents them from happening
again. I know it is impossible to avoid problems, as it is impossible not to
make mistakes in our lives. The true inefficiency? Skipping the "why" and "how
next time." ... Borrowed from incident response, it's a structured debrief that
prevents recurrence without finger-pointing. In engineering, it ensures
resilience; in life, it builds emotional antifragility. There are endless
flavours of postmortems—simple Markdown outlines to full-blown docs—but the gold
standard is "blameless," focusing on systems over scapegoats.
Cyber resilience is a business imperative: skills and strategy must evolve
 Cyber upskilling must be built into daily work for both technical and
non-technical employees. It’s not a one-off training exercise; it’s part of how
people perform their roles confidently and securely. For technical teams,
staying current on certifications and practicing hands-on defense is essential.
Labs and sandboxes that simulate real-world attacks give them the experience
needed to respond effectively when incidents happen. For everyone else, the
focus should be on clarity and relevance. Employees need to understand exactly
what’s expected of them; how their individual decisions contribute to the
organization's resilience. Role-specific training makes this real: finance teams
need to recognize invoice fraud attempts; HR should know how to handle sensitive
data securely; customer service needs to spot social engineering in live
interactions. ... Resilience should now sit alongside financial performance and
sustainability as a core board KPI. That means directors receiving regular
updates not only on threat trends and audit findings, but also on recovery
readiness, incident transparency, and the cultural maturity of the
organization's response. Re-engaging boards on this agenda isn’t about assigning
blame—it’s about enabling smarter oversight. When leaders understand how
resilience protects trust, continuity, and brand, cybersecurity stops being a
technical issue and becomes what it truly is: a measure of business strength.
Cyber upskilling must be built into daily work for both technical and
non-technical employees. It’s not a one-off training exercise; it’s part of how
people perform their roles confidently and securely. For technical teams,
staying current on certifications and practicing hands-on defense is essential.
Labs and sandboxes that simulate real-world attacks give them the experience
needed to respond effectively when incidents happen. For everyone else, the
focus should be on clarity and relevance. Employees need to understand exactly
what’s expected of them; how their individual decisions contribute to the
organization's resilience. Role-specific training makes this real: finance teams
need to recognize invoice fraud attempts; HR should know how to handle sensitive
data securely; customer service needs to spot social engineering in live
interactions. ... Resilience should now sit alongside financial performance and
sustainability as a core board KPI. That means directors receiving regular
updates not only on threat trends and audit findings, but also on recovery
readiness, incident transparency, and the cultural maturity of the
organization's response. Re-engaging boards on this agenda isn’t about assigning
blame—it’s about enabling smarter oversight. When leaders understand how
resilience protects trust, continuity, and brand, cybersecurity stops being a
technical issue and becomes what it truly is: a measure of business strength.































