How to survive below the cybersecurity poverty line

All types of businesses and sectors can fall below the cybersecurity poverty
line for different reasons, but generally, healthcare, start-ups, small- and
medium-size enterprises (SMEs), education, local governments, and industrial
companies all tend to struggle the most with cybersecurity poverty, says Alex
Applegate ... These include wide, cumbersome, and outdated networks in
healthcare, small IT departments and immature IT processes in smaller
companies/start-ups, vast network requirements in educational institutions,
statutory obligations and limitations on budget use in local governments, and
custom software built around specific functionality and configurations in
industrial businesses, he adds. Critical National Infrastructure (CNI) firms and
charities also commonly find themselves below the cybersecurity poverty line,
for similar reasons. The University of Portsmouth Cybercrime Awareness Clinic’s
work with SMEs for the UK National Cyber Security Centre (NCSC) revealed that
cybersecurity was a secondary issue for most micro and small businesses it
engaged with, evidence that it is often the smallest companies that find
themselves below the poverty line, Karagiannopoulos says.
The Importance of Testing in Continuous Deployment
Test engineers are usually perfectionists (I speak from my experience), that’s
why it’s difficult for them to take a risk of issues possibly reaching end
users. This approach has a hefty price tag and impacts the speed of delivery,
but it’s acceptable if you deliver only once or twice per month. The correct
approach would be automating critical paths in application both from a business
perspective and application reliability. Everything else can go to production
without thorough testing because with continuous deployment, you can fix issues
within hours or minutes. For example, if item sorting and filtering stops
working in production, users might complain, but the development team could fix
this issue quickly. Would it impact business? Probably not. Would you lose a
customer? Probably not. These are the risks that should be OK to take if you can
quickly fix issues in production. Of course, it all depends on the context – if
you’re providing document storing services for legal investigations, it would be
a good idea to have an automated test for sorting and filtering.
Why Trust and Autonomy Matter for Cloud Optimization

With organizations beginning to ask teams to do more with less, optimization —
of all kinds — is going to become a vital part of what technology teams
(development and operations alike) have to do. But for that to be really
effective, team autonomy also needs to be founded on confidence — you need to
know that what you’re investing time, energy and money on makes sense from the
perspective of the organization’s wider goals. Fortunately, Spot can help here
too. It gives teams the data they need to make decisions about automation, so
they can prioritize according to what matters most from a strategic perspective.
“People aren’t really sure what’s going to be happening six, nine, 10 months
down the road.” Harris says. “Making it easier for people to get that actionable
data no matter what part of the business you’re in, so that you can go in and
you can say, ‘Here’s what we’re doing right, here’s where we can optimize’ —
that’s a big focus for us.” One of the ways that Spot enables greater autonomy
is with automation features.
Keys to successful M&A technology integration

For large organisations merging together, unifying networks and technologies
may take years. But for SMBs (small and medium-sized businesses) utilising
more traditional technologies uch as VPNs, integrations may be accomplished
more quickly and with less friction. In scenarios where both the acquiring
company and the company being acquired utilise more sophisticated
SD-WAN networks, these technologies tend to be closed and proprietary in nature.
Therefore, if both companies utilise the same vendor, integration can be
managed more easily. On the other hand, if the vendors differ, it is not going
to interlink with other networks as easily and needs a more careful
step-by-step network transformation plan. ... Another key to a successful
technology merger is to truly understand where your applications are going.
For example, if two New York companies are joining forces, with most of the
data and applications residing in the US East Coast, it wouldn’t make sense to
interconnect networks in San Francisco. Along with this, it is important to
make sure your regional networks are strong, even within your global network.
In terms of where you are sending your traffic and data, it’s important to be
as efficient as possible.
Understanding service mesh?
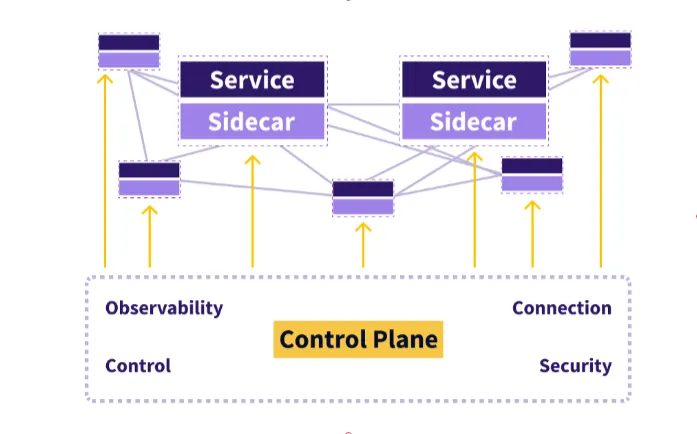
Service meshes don’t give an application’s runtime environment any additional
features. Service meshes are unique in that they abstract the logic governing
service-to-service communication to an infrastructure layer. This is
accomplished by integrating a service mesh as a collection of network proxies
into an application. proxies are frequently used to access websites.
Typically, a company’s web proxy receives requests for a web page and
evaluates them for security flaws before sending them on to the host server.
Prior to returning to the user, responses from the page are also forwarded to
the proxy for security checks. ... But service mesh is an essential
management system that helps all the different containers to work in harmony.
Here are several reasons why you will want to implement service mesh in an
orchestration framework environment. In a typical orchestration framework
environment, user requests are fulfilled through a series of steps, where each
of the steps is performed by a container Each one runs a service that plays a
different but vital role in fulfilling that request. Let us call this role
played by each container a business logic.
Chaos Engineering: Benefits of Building a Test Strategy

Many organizations struggle to get visibility into where their most sensitive
data is stored. Improper handling of that data can have disastrous
consequences, such as compliance violations or trade secrets falling into the
wrong hands. “Using chaos engineering could help identify vulnerabilities
that, unless remediated, could be exploited by bad actors within minutes,”
Benjamin says. Kelly Shortridge, senior principal of product technology at
Fastly, says organizations can use chaos engineering to generate evidence of
their systems’ resilience against adverse scenarios, like attacks. “By
conducting experiments, you can proactively understand how failure unfolds,
rather than waiting for a real incident to occur,” she says. The very nature
of experiments requires curiosity -- the willingness to learn from evidence --
and flexibility so changes can be implemented based on that evidence.
“Adopting security chaos engineering helps us move from a reactive posture,
where security tries to prevent all attacks from ever happening, to a
proactive one in which we try to minimize incident impact and continuously
adapt to attacks,” she notes.
How to get buy-in on new technology: 3 tips
When making a case for new technology, keep your audience in mind. Tailoring
your arguments to their role and goals will put you in a much better position
to capture their attention and generate enthusiasm. Sometimes this will
require you to shift away from strict business goals. If you need to speak
with the chief revenue officer and are trying to justify an additional
$100,000 for your tech stack, for example, you will need to focus on the
bottom line and the financial benefit your proposal could provide. On the
other hand, the head of engineering might not be interested in the finances
and would rather discuss how engineers can better avoid burnout or otherwise
become easier to manage. When advocating for stack improvements, working with
a partner helps substantially. It’s good to have a boss or teammate help, but
even better to find a leader on a different team or even in another
department. If multiple departments have team members who champion a specific
improvement, it makes a strong case that there’s a pervasive need for stack
enhancements across the entire company.
How organizations can keep themselves secure whilst cutting IT spending
The zero trust network access model has been a major talking point for CIOs,
CISOs and IT professionals for some time. While most organizations do not
fully understand what zero trust is, they recognize the importance of the
initiative. Enforcing principles of least privilege minimizes the impact of an
attack. In a zero trust model, an organization can authorize access in
real-time based on information about the account they have collected over
time. To make such informed decisions, security teams need accurate and
up-to-date user profiles. Without it, security teams can’t be 100% confident
that the user gaining access to a critical resource isn’t a threat. However,
with the sprawl of identity data – stored in the cloud and legacy systems – of
which are unable to communicate with each other, such decisions cannot be made
accurately. Ultimately, the issue of identity management isn’t only getting
more challenging with the digitalization of IT and migration to the cloud –
it’s now also halting essential security projects such as zero trust
implementation.
Economic headwinds could deepen the cybersecurity skills shortage

Look at anyone’s research and you’ll see that more organizations are turning
to managed services to augment overburdened and under-skilled internal
security staff. For example, recent ESG research on security operations
indicates that 85% of organizations use some type of managed detection and
response (MDR) service, and 88% plan to increase their use of managed services
in the future. As this pattern continues, managed security service providers
(MSSPs) will need to add headcount to handle increasing demand. Since service
provider business models are based on scaling operations through automation,
they will calculate a higher return on employee productivity and be willing to
offer more generous compensation than typical organizations. One aggressive
security services firm in a small city could easily gain a near monopoly on
local talent. At the executive level, we will also see increasing demand for
the services of virtual CISOs (vCISOs) to create and manage security programs
in the near term.
2023 Will Be the Year FinOps Shifts Left Toward Engineering

By enabling developers to adopt using dynamic logs for troubleshooting issues
in production without the need to redeploy and add more costly logs and
telemetry, developers can own the FinOps cost optimization responsibility
earlier in the development cycle and shorten the cost feedback loop. Dynamic
logs and developer native observability that are triggered from the developer
development environment (IDE) can be an actionable method to cut overall costs
and better facilitate cross-team collaboration, which is one of the core
principles of FinOps. “FinOps will become more of an engineering problem than
it was in the past, where engineering teams had fairly free reign on cloud
consumption. You will see FinOps information shift closer to the developer and
end up part of pull-request infrastructure down the line,” says Chris
Aniszczyk, CTO at the Cloud Native Computing Foundation. Keep in mind that
it’s not always easy to prioritize and decide when to pull the cost
optimization trigger.
Quote for the day:
"Inspired leaders move a business
beyond problems into opportunities." -- Dr. Abraham Zaleznik
1 comment:
You have done a good job by publishing this article about.Cyber Security Solutions Australia I appreciate your efforts which you have put into this article, It is a beneficial article for us. Thanks for sharing such informative thoughts.
Post a Comment