Is Your Innovation Project Condemned To Succeed?

The challenge in most organizations is that leaders are looking to make big
bets on a few projects. These bets are typically based on asking innovation
teams to create a business case before they receive investment. A business
case showing good returns will receive investment with the expectation that it
will succeed. The team is given no room for failure. ... This problem is
exacerbated if your team has received a large investment to work on the
project. Most innovation teams lose the discipline to test their ideas if they
have large budgets to spend. In most cases they burn through the money while
executing on their original idea. By the time they learn that the idea may not
work, they have already spent millions of dollars. At this point, admitting
failure is career suicide. ... Imagine being the CEO’s pet project, having a
large investment and then being publicly celebrated as a lighthouse project
before you have made any money for the company. This public celebration of a
single innovation project puts a lot of pressure on innovation teams to
succeed.
Which cloud workloads are right for repatriation?

Look at the monthly costs and values of each platform. This is the primary
reason we either stay put on the cloud or move back to the enterprise data
center. Typically the workload has already been on the cloud for some time, so
we have a good understanding of the costs, talent needed, and other
less-quantifiable benefits of cloud, such as agility and scalability. You
would think that these are relatively easy calculations to make, but it
becomes complex quickly. Some benefits are often overlooked and architects
make mistakes that cost the business millions. All costs and benefits of being
on premises should be considered, including the cost of the humans needed to
maintain the platforms (actual hardware and software), data center space (own
or rent), depreciation, insurance, power, physical security, compliance,
backup and recovery, water, and dozens of other items that may be specific to
your enterprise. Also consider the true value of agility and scalability that
will likely be lost or reduced if the workloads return to your own data
center.
Network automation: What architects need to know

It's great to strive for an automation-first culture and find innovative ways
to use technology as a competitive advantage, but I recommend first targeting
low-risk, high-reward tasks. Try to create reusable building blocks to operate
more efficiently. One example is automating the collection and parsing of
operational data from the network, such as routing protocol sessions state,
VPN service status, or other relevant metrics to produce actionable or
consumable outputs. Gathering this information is a read-only activity, so the
risk is low. The reward is high because this task is a time-consuming,
repetitive process. Also, you can use this data for various purposes, such as
creating reports, running audits, filling in trouble tickets, performing
pre-and post-checks during maintenance windows, and so on. You don't need to
wait until you get everything right to start. Improve on your automation
solution iteratively. Small initial steps can make a big difference in your
network. For example, for the data collection example above, you don't need
the full list of key performance indicators (KPIs) on day 1; your users will
let you know what you're missing over time.
Finding Adequate Metrics for Outer, Inner, and Process Quality in Software Development
/filters:no_upscale()/articles/metrics-quality-software/en/resources/9figure-2-1673957572756.jpg)
Quite an obvious criteria for outer quality is the question of if the users
like the product. If your product has customer support, you could simply count
the number of complaints or contacts. Additionally, you can categorize these
to gain more information. While this is in fact a lot of effort and far from
trivial, it is a very direct measure and might yield a lot of valuable
information on top. One problem here is selection bias. We are only counting
those who are getting in contact, ignoring those who are not annoyed enough to
bother (yet). Another similar problem is survivorship bias. We ignore those
users who simply quit due to an error and never bother to get in contact. Both
biases may lead us to over-focus on issues of a complaining minority, while we
should rather further improve things users actually like about the product.
Besides these issues, the complaint rate can also be gamed: simply make it
really hard to contact customer support by hiding contact information or
increase waiting time in the queue.
Platform Engineering Won’t Kill the DevOps Star

“The movement to ‘shift left’ has forced developers to have an end-to-end
understanding of an ever-increasing amount of complex tools and workflows.
Oftentimes, these tools are infrastructure-centric, meaning that developers
have to be concerned with the platform and tooling their workloads run on,”
Humanitec’s Luca Galante writes in his platform engineering trends in 2023,
which demands more infrastructure abstraction. Indeed, platform engineering
could be another name for cloud engineering, since so much of developers’
success relies on someone obscuring the complexity out of the cloud — and so
many challenges are found in that often seven layers thick stack. Therefore
you could say platform engineering takes the spirit of agile and DevOps and
extends it within the context of a cloud native world. She pointed to platform
engineering’s origins in Team Topologies, where “the platform is designed to
enable the other teams. The key thing about it is kind of this self-service
model where app teams get what they want from the platform to deliver business
value,” Kennedy said.
The Concept of Knowledge Graph, Present Uses and Potential Future Applications
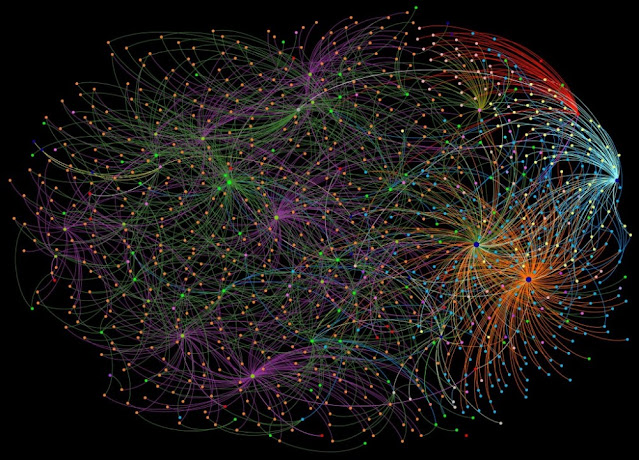
A knowledge graph is a database that uses a graph structure to represent and
store knowledge. It is a way to express and organize data that is easy for
computers to understand and reason about and which can be used to perform
tasks such as answering questions or making recommendations. The graph
structure consists of nodes, which represent entities or concepts, and edges,
which represent relationships between the nodes. For example, a node
representing the concept "Apple" might have advantages over nodes representing
the concepts "Fruit," "Cupertino, California," and "Tim Cook," which represent
relationships such as "is a type of," "is located in," and "has a CEO of,"
respectively. In a knowledge graph, the relationships between nodes are often
explicitly defined and stored, which allows computers to reason about the data
and make inferences based on it. This is in contrast to traditional databases,
which store data in tables and do not have direct relationships between the
data points.
4 tips to broaden and diversify your tech talent pool

Apprenticeships are extremely valuable for both employers and candidates. For
employers, apprenticeships are a cost-effective way to groom talent, providing
real-world training and a skilled employee at the end of the program.
Apprenticeship programs also reduce the ever-present risk of hiring a
full-time entry-level employee, who may prove to not be up to the required
standard or decide for themselves that the organization or industry is not a
fit. For workers, an apprenticeship is essentially a crash course providing
the opportunity to earn while they learn. With the average college graduate
taking on $30,000 in debt (and many taking on much more), a degree has
increasingly become out of financial reach for many Americans. Apprenticeships
are an excellent way for people to gain tangible work experience and
applicable skills while also providing a trial run to determine whether a
career in cybersecurity is right for them. For me, apprenticeship programs are
a true win-win. During National Apprenticeship Week this year, we joined the
Department of Labor’s event at the White House to celebrate the culmination of
the 120-day Cybersecurity Apprenticeship Sprint.
Debugging Threads and Asynchronous Code
Let’s discuss deadlocks. Here we have two threads each is waiting on a monitor
held by the other thread. This is a trivial deadlock but debugging is trivial
even for more complex cases. Notice the bottom two threads have a MONITOR
status. This means they’re waiting on a lock and can’t continue until it’s
released. Typically, you’d see this in Java as a thread is waiting on a
synchronized block. You can expand these threads and see what’s going on and
which monitor is held by each thread. If you’re able to reproduce a deadlock
or a race in the debugger, they are both simple to fix. Stack traces are
amazing in synchronous code, but what do we do when we have asynchronous
callbacks? Here we have a standard async example from JetBrains that uses a
list of tasks and just sends them to the executor to perform on a separate
thread. Each task sleeps and prints a random number. Nothing to write home
about. As far as demos go this is pretty trivial. Here’s where things get
interesting. As you can see, there’s a line that separates the async stack
from the current stack on the top.
3 requirements for developing an effective cloud governance strategy

Governance is not a one-size-fits-all proposition, and each organization may
prefer a different approach to governance depending on its objectives. Digital
transformation is no longer a novel concept. But continuous innovation is
required to improve and remain competitive, making automation critical for
operational efficiency. According to IDC's Worldwide Artificial Intelligence
and Automation 2023 Predictions, AI-driven features are expected to be
embedded across business technology categories by 2026, with 60% of
organizations actively utilizing such features to drive better outcomes.
Automation is critical for increasing efficiency in cloud management
operations, such as billing and cost transparency, right-sizing computer
resources, and monitoring cost anomalies. The use of automated tools can
improve security, lower administrative overhead, decrease rework, and lower
operational costs. Definable metrics and key performance indicators (KPIs) can
be used to assess outcomes with the right cost transparency tool. ...
Automation can also aid in resolving personnel issues, which can cause
migration projects to stall.
Styles of machine learning: Intro to neural networks

What makes the neural network powerful is its capacity to learn based on
input. This happens by using a training data set with known results, comparing
the predictions against it, then using that comparison to adjust the weights
and biases in the neurons. ... A common approach is gradient descent, wherein
each weight in the network is isolated via partial derivation. For example,
according to a given weight, the equation is expanded via the chain rule and
fine-tunings are made to each weight to move overall network loss lower. Each
neuron and its weights are considered as a portion of the equation, stepping
from the last neuron(s) backwards. You can think of gradient descent this way:
the error function is the graph of the network's output, which we are trying
to adjust so its overall shape (slope) lands as well as possible according to
the data points. In doing gradient backpropagation, you stand at each neuron’s
function and modify it slightly to move the whole graph a bit closer to the
ideal solution. The idea here is that you consider the entire neural network
and its loss function as a multivariate equation depending on the weights and
biases.
Quote for the day:
"The secret of leadership is simple:
Do what you believe in. Paint a picture of the future. Go there. People will
follow." -- Seth Godin
No comments:
Post a Comment