Identity security: a more assertive approach in the new digital world
 Perimeter-based security, where organisations only allow trusted parties with
the right privileges to enter and leave doesn’t suit the modern digitalised,
distributed environment of remote work and cloud applications. It’s just not
possible to put a wall around a business that’s spread across multiple private
and public clouds and on-premises locations. This has led to the emergence of
approaches like Zero-Trust – an approach built on the idea that organisations
should not automatically trust anyone or anything – and the growth of identity
security as a discipline, which incorporates Zero-Trust principles at the scale
and complexity required by modern digital business. Zero-Trust frameworks demand
that anyone trying to access an organisation’s system is verified every time
before granting access on a ‘least privilege’ basis, which is particularly
useful in the context of the growing need to audit machine identities.
Typically, they operate by collecting information about the user, endpoint,
application, server, policies and all activities related to them and feeding it
into a data pool which fuels machine learning (ML).
Perimeter-based security, where organisations only allow trusted parties with
the right privileges to enter and leave doesn’t suit the modern digitalised,
distributed environment of remote work and cloud applications. It’s just not
possible to put a wall around a business that’s spread across multiple private
and public clouds and on-premises locations. This has led to the emergence of
approaches like Zero-Trust – an approach built on the idea that organisations
should not automatically trust anyone or anything – and the growth of identity
security as a discipline, which incorporates Zero-Trust principles at the scale
and complexity required by modern digital business. Zero-Trust frameworks demand
that anyone trying to access an organisation’s system is verified every time
before granting access on a ‘least privilege’ basis, which is particularly
useful in the context of the growing need to audit machine identities.
Typically, they operate by collecting information about the user, endpoint,
application, server, policies and all activities related to them and feeding it
into a data pool which fuels machine learning (ML).How Can We Make It Easier To Implant a Brain-Computer Interface?
As for implantable BCIs, so far there is only the Blackrock NeuroPort Array (Utah Array) implant, which also has the largest number of subjects implanted and the longest documented implantation times, and the Stentrode from Synchron, that has just recorded its first two implanted patients. The latter is essentially based on a stent that is inserted into the blood vessels in the brain and used to record EEG-type data (local field potentials (LFPs)). It is a very clever solution and surgical approach, and I do believe that it has great potential for a subset of use cases that do not require the high level of spatial and temporal resolution that our electrodes are offering. I am also looking forward to seeing the device’s long term performance. Our device records single unit action potentials (i.e., signals from individual neurons) and LFPs with high temporal and spatial resolution and high channel count, allowing significant spatial coverage of the neural tissue. It is implanted by a neurosurgeon who creates a small craniotomy (i.e., opens a small hole in the skull and dura), inserts the devices in the previously determined location by manually placing it in the correct area.Artificial Intelligence (AI): 4 characteristics of successful teams
Software Testing in the World of Next-Gen Technologies
If there is a technology that has gained momentum during the past decade, it is nothing other than artificial intelligence. AI offers the potential to mimic human tasks and improvise the operations through its own intellect, the logic it brings to business shows scope for productive inferences. However, the benefit of AI can only be achieved by feeding computers with data sets, and this needs the right QA and testing practices. As long as automation testing implementation needs to be done for deriving results, performance could only be achieved by using the right input data leading to effective processing. Moreover, the improvement of AI solutions is beneficial not only for other industries, but QA itself, since many of the testing and quality assurance processes depend on automation technology powered by artificial intelligence. The introduction of artificial intelligence into the testing process has the potential to enable smarter testing. So, the testing of AI solutions could enable software technologies to work on better reasoning and problem-solving capabilities.What Makes Agile Transformations Successful? Results From A Scientific Study
 The ultimate test of any model is to test it with every Scrum team and every
organization. Since this is not practically feasible, scientists use advanced
statistical techniques to draw conclusions about the population from a smaller
sample of data from that population. Two things are important here. The first
is that the sample must be big enough to reliably distinguish effects from the
noise that always exists in data. The second is that the sample must be
representative enough of the larger population in order to generalize findings
to it. It is easy to understand why. Suppose that you’re tasked with testing
the purity of the water in a lake. You can’t feasibly check every drop of
water for contaminants. But you can sample some of the water and test it. This
sample has to be big enough to detect contaminants and small enough to remain
feasible. It's also possible that contaminants are not equally distributed
across the lake. So it's a good idea to sample and test a bucket of water at
various spots from the lake. This is effectively what happens here.
The ultimate test of any model is to test it with every Scrum team and every
organization. Since this is not practically feasible, scientists use advanced
statistical techniques to draw conclusions about the population from a smaller
sample of data from that population. Two things are important here. The first
is that the sample must be big enough to reliably distinguish effects from the
noise that always exists in data. The second is that the sample must be
representative enough of the larger population in order to generalize findings
to it. It is easy to understand why. Suppose that you’re tasked with testing
the purity of the water in a lake. You can’t feasibly check every drop of
water for contaminants. But you can sample some of the water and test it. This
sample has to be big enough to detect contaminants and small enough to remain
feasible. It's also possible that contaminants are not equally distributed
across the lake. So it's a good idea to sample and test a bucket of water at
various spots from the lake. This is effectively what happens here.OAuth 2.0 and OIDC Fundamentals for Authentication and Authorization
The main goal of OAuth 2.0 is delegated authorization. In other words, as we saw earlier, the primary purpose of OAuth 2.0 is to grant an app access to data owned by another app. OAuth 2.0 does not focus on authentication, and as such, any authentication implementation using OAuth 2.0 is non-standard. That’s where OpenID Connect (OIDC) comes in. OIDC adds a standards-based authentication layer on top of OAuth 2.0. The Authorization Server in the OAuth 2.0 flows now assumes the role of Identity Server (or OIDC Provider). The underlying protocol is almost identical to OAuth 2.0 except that the Identity Server delivers an Identity Token (ID Token) to the requesting app. The Identity Token is a standard way of encoding the claims about the authentication of the user. We will talk more about identity tokens later. ... For both these flows, the app/client must be registered with the Authorization Server. The registration process results in the generation of a client_idand a client_secret which must then be configured on the app/client requesting authentication.How Biometric Solutions Are Shaping Workplace Security
 Today, the corporate world and biometric technology go hand in hand. Companies
cannot operate seamlessly without biometrics. Regular security checks just
don’t cut it in companies anymore. Since biometric technologies are designed
specifically to offer the highest level of security, there is limited to no
room when it comes to defrauding these systems. Thus, technologies like ID
Document Capture, Selfie Capture, 3D Face Map Creation, etc., are becoming the
best way to secure the workplace. Biometric technology allows for specific
data collection. It doesn’t just reduce the risk of a data breach but also
protects important data in offices. Whether it’s cards, passwords, documents,
etc., biometric technology eliminates the need for such hackable security
implementations at the workplace. All biometric data like fingerprints, facial
mapping, and so on are extremely difficult to replicate. Certain biological
characteristics don’t change with time, and that prevents authentication
errors. Hence, there’s limited scope for identity replication or mimicry.
Customized personal identity access control has become an employee’s right of
sorts.
Today, the corporate world and biometric technology go hand in hand. Companies
cannot operate seamlessly without biometrics. Regular security checks just
don’t cut it in companies anymore. Since biometric technologies are designed
specifically to offer the highest level of security, there is limited to no
room when it comes to defrauding these systems. Thus, technologies like ID
Document Capture, Selfie Capture, 3D Face Map Creation, etc., are becoming the
best way to secure the workplace. Biometric technology allows for specific
data collection. It doesn’t just reduce the risk of a data breach but also
protects important data in offices. Whether it’s cards, passwords, documents,
etc., biometric technology eliminates the need for such hackable security
implementations at the workplace. All biometric data like fingerprints, facial
mapping, and so on are extremely difficult to replicate. Certain biological
characteristics don’t change with time, and that prevents authentication
errors. Hence, there’s limited scope for identity replication or mimicry.
Customized personal identity access control has become an employee’s right of
sorts.
How to avoid being left behind in today’s fast-paced marketplace
 The ability to speed up processes and respond more quickly to a highly dynamic
market is the key to survival in today’s competitive business environment. For
many large businesses, the ERP system forms a crucial part of the digital
core, which is supplemented by best-of-breed applications in areas such as
customer experience, supply chain, and asset management. When it comes to
digitalisation, organisations will often focus on these applications and the
connections between them. However, we often see businesses forget to automate
processes in the digital core itself — an oversight that can negatively impact
other digitalisation efforts. For example, the ability to analyse demand
trends on social media in the customer-focused application can offer valuable
insights, but if it takes months for the product data needed to launch a new
product variant to be accessed, customer trends are likely to have already
moved on. If we look more closely at the process of launching a new product to
market, this is a prime example of where digital transformation can be applied
to help manufacturers remain agile and respond to market trends more
quickly.
The ability to speed up processes and respond more quickly to a highly dynamic
market is the key to survival in today’s competitive business environment. For
many large businesses, the ERP system forms a crucial part of the digital
core, which is supplemented by best-of-breed applications in areas such as
customer experience, supply chain, and asset management. When it comes to
digitalisation, organisations will often focus on these applications and the
connections between them. However, we often see businesses forget to automate
processes in the digital core itself — an oversight that can negatively impact
other digitalisation efforts. For example, the ability to analyse demand
trends on social media in the customer-focused application can offer valuable
insights, but if it takes months for the product data needed to launch a new
product variant to be accessed, customer trends are likely to have already
moved on. If we look more closely at the process of launching a new product to
market, this is a prime example of where digital transformation can be applied
to help manufacturers remain agile and respond to market trends more
quickly.
FireEye, CISA Warn of Critical IoT Device Vulnerability
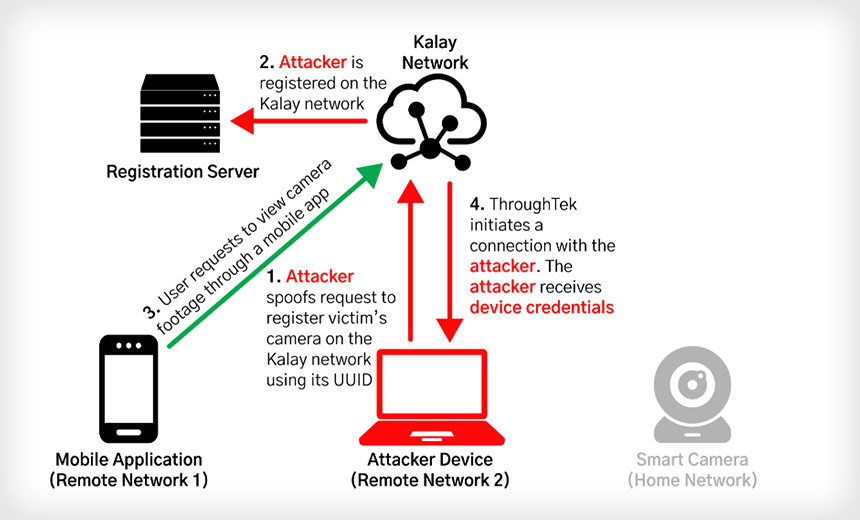 Kalay is a network protocol that helps devices easily connect to a software
application. In most cases, the protocol is implemented in IoT devices through
a software development kit that's typically installed by original equipment
manufacturers. That makes tracking devices that use the protocol difficult,
the FireEye researchers note. The Kalay protocol is used in a variety of
enterprise IoT and connected devices, including security cameras, but also
dozens of consumer devices, such as "smart" baby monitors and DVRs, the
FireEye report states. "Because the Kalay platform is intended to be used
transparently and is bundled as part of the OEM manufacturing process,
[FireEye] Mandiant was not able to create a complete list of affected devices
and geographic regions," says Dillon Franke, one of the three FireEye
researcher who conducted the research on the vulnerability. FireEye's Mandiant
Red Team first uncovered the vulnerability in 2020. If exploited, the flaw can
allow an attacker to remotely control a vulnerable device, "resulting in the
ability to listen to live audio, watch real-time video data and compromise
device credentials for further attacks based on exposed device functionality,"
the security firm reports.
Kalay is a network protocol that helps devices easily connect to a software
application. In most cases, the protocol is implemented in IoT devices through
a software development kit that's typically installed by original equipment
manufacturers. That makes tracking devices that use the protocol difficult,
the FireEye researchers note. The Kalay protocol is used in a variety of
enterprise IoT and connected devices, including security cameras, but also
dozens of consumer devices, such as "smart" baby monitors and DVRs, the
FireEye report states. "Because the Kalay platform is intended to be used
transparently and is bundled as part of the OEM manufacturing process,
[FireEye] Mandiant was not able to create a complete list of affected devices
and geographic regions," says Dillon Franke, one of the three FireEye
researcher who conducted the research on the vulnerability. FireEye's Mandiant
Red Team first uncovered the vulnerability in 2020. If exploited, the flaw can
allow an attacker to remotely control a vulnerable device, "resulting in the
ability to listen to live audio, watch real-time video data and compromise
device credentials for further attacks based on exposed device functionality,"
the security firm reports.
An Introduction to Blockchain
 The distributed ledger created using blockchain technology is unlike a
traditional network, because it does not have a central authority common in a
traditional network structure. Decision-making power usually resides with a
central authority, who decides in all aspects of the environment. Access to
the network and data is subject to the individual responsible for the
environment. The traditional database structure therefore is controlled by
power. This is not to say that a traditional network structure is not
effective. Certain business functions may best be managed by a central
authority. However, such a network structure is not without its challenges.
Transactions take time to process and cost money; they are not validated by
all parties due to limited network participation, and they are prone to error
and vulnerable to hacking. To process transactions in a traditional network
structure also requires technical skills. In contrast, the distributed ledger
is control by rules, not a central authority. The database is accessible to
all the members of the network and installed on all the computers that use the
database. Consensus between members is required to add transactions to the
database.
The distributed ledger created using blockchain technology is unlike a
traditional network, because it does not have a central authority common in a
traditional network structure. Decision-making power usually resides with a
central authority, who decides in all aspects of the environment. Access to
the network and data is subject to the individual responsible for the
environment. The traditional database structure therefore is controlled by
power. This is not to say that a traditional network structure is not
effective. Certain business functions may best be managed by a central
authority. However, such a network structure is not without its challenges.
Transactions take time to process and cost money; they are not validated by
all parties due to limited network participation, and they are prone to error
and vulnerable to hacking. To process transactions in a traditional network
structure also requires technical skills. In contrast, the distributed ledger
is control by rules, not a central authority. The database is accessible to
all the members of the network and installed on all the computers that use the
database. Consensus between members is required to add transactions to the
database.
Quote for the day:
"Nothing is less productive than to make more efficient what should not be done at all." -- Peter Drucker
No comments:
Post a Comment