Why scrum has become irrelevant
 The purpose of the retrospective is just that: to reflect. We look at what
worked, what didn’t work, and what kinds of experiments we want to
try.Unfortunately, what it boils down to is putting the same Post-its of “good
teamwork” and “too many meetings” in the same swim lanes as “what went well,”
“what went wrong,” and “what we will do better.” ... Scrum is often the enemy of
productivity, and it makes even less sense in the remote, post-COVID world. The
premise of scrum should not be that one cookie cutter fits every development
team on the planet. A lot of teams are just doing things by rote and with zero
evidence of their effectiveness. An ever-recurring nightmare of standups, sprint
grooming, sprint planning and retros can only lead to staleness. Scrum does not
promote new and fresh ways of working; instead, it champions repetition. Let
good development teams self-organize to their context. Track what gets shipped
to production, add the time it took (in days!) after the fact, and track that.
Focus on reality and not some vaguely intelligible burndown chart. Automate all
you can and have an ultra-smooth pipeline. Eradicate all waste.
The purpose of the retrospective is just that: to reflect. We look at what
worked, what didn’t work, and what kinds of experiments we want to
try.Unfortunately, what it boils down to is putting the same Post-its of “good
teamwork” and “too many meetings” in the same swim lanes as “what went well,”
“what went wrong,” and “what we will do better.” ... Scrum is often the enemy of
productivity, and it makes even less sense in the remote, post-COVID world. The
premise of scrum should not be that one cookie cutter fits every development
team on the planet. A lot of teams are just doing things by rote and with zero
evidence of their effectiveness. An ever-recurring nightmare of standups, sprint
grooming, sprint planning and retros can only lead to staleness. Scrum does not
promote new and fresh ways of working; instead, it champions repetition. Let
good development teams self-organize to their context. Track what gets shipped
to production, add the time it took (in days!) after the fact, and track that.
Focus on reality and not some vaguely intelligible burndown chart. Automate all
you can and have an ultra-smooth pipeline. Eradicate all waste. Your data, your choice
These days, people are much more aware of the importance of shredding paper copies of bills and financial statements, but they are perfectly comfortable handing over staggering amounts of personal data online. Most people freely give their email address and personal details, without a second thought for any potential misuse. And it’s not just the tech giants – the explosion of digital technologies means that companies and spin-off apps are hoovering up vast amounts of personal data. It’s common practice for businesses to seek to “control” your data and to gather personal data that they don’t need at the time on the premise that it might be valuable someday. The other side of the personal data conundrum is the data strategy and governance model that guides an individual business. At Nephos, we use our data expertise to help our clients solve complex data problems and create sustainable data governance practices. As ethical and transparent data management becomes increasingly important, younger consumers are making choices based on how well they trust you will handle and manage their data.How Kafka Can Make Microservice Planet a Better Place
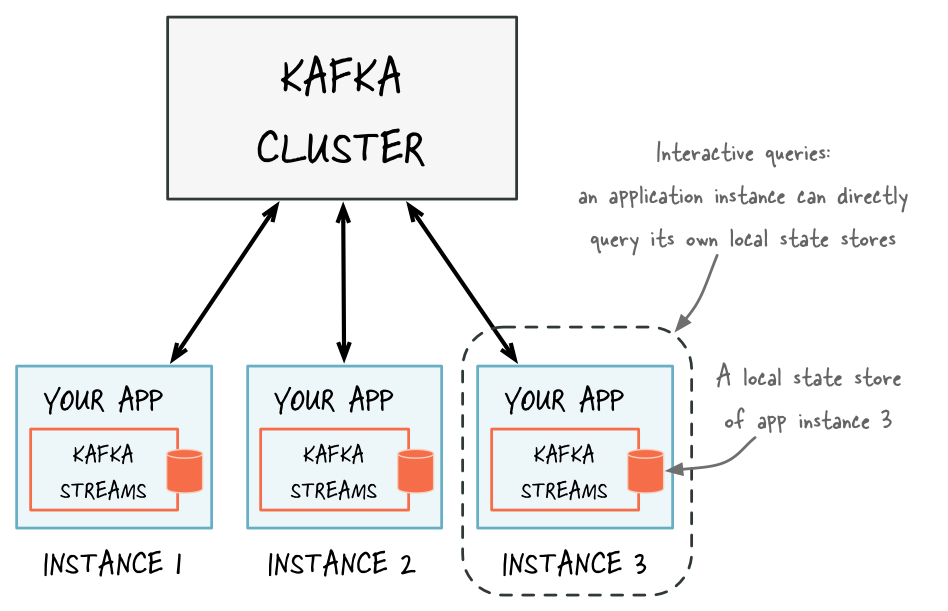 Originally Kafka was developed under the Apache license but later Confluent
forked on it and delivered a robust version of it. Actually Confluent delivers
the most complete distribution of Kafka with Confluent Platform. Confluent
Platform improves Kafka with additional community and commercial features
designed to enhance the streaming experience of both operators and developers in
production, at a massive scale. You can find thousands of documents about
learning Kafka. In this article, we want to focus on using it in the
microservice architecture, and we need an important concept named Kafka Topic
for that. ... The final topic that we should learn about is before starting our
stream processing project is Kstream. KStream is an abstraction of a record
stream of KeyValue pairs, i.e., each record is an independent entity/event. In
the real world, Kafka Streams greatly simplifies the stream processing from
topics. Built on top of Kafka client libraries, it provides data parallelism,
distributed coordination, fault tolerance, and scalability. It deals with
messages as an unbounded, continuous, and real-time flow of records.
Originally Kafka was developed under the Apache license but later Confluent
forked on it and delivered a robust version of it. Actually Confluent delivers
the most complete distribution of Kafka with Confluent Platform. Confluent
Platform improves Kafka with additional community and commercial features
designed to enhance the streaming experience of both operators and developers in
production, at a massive scale. You can find thousands of documents about
learning Kafka. In this article, we want to focus on using it in the
microservice architecture, and we need an important concept named Kafka Topic
for that. ... The final topic that we should learn about is before starting our
stream processing project is Kstream. KStream is an abstraction of a record
stream of KeyValue pairs, i.e., each record is an independent entity/event. In
the real world, Kafka Streams greatly simplifies the stream processing from
topics. Built on top of Kafka client libraries, it provides data parallelism,
distributed coordination, fault tolerance, and scalability. It deals with
messages as an unbounded, continuous, and real-time flow of records.What Happens When ‘If’ Turns to ‘When’ in Quantum Computing?
Quantum computers will not replace the traditional computers we all use now. Instead they will work hand-in-hand to solve computationally complex problems that classical computers can’t handle quickly enough by themselves. There are four principal computational problems for which hybrid machines will be able to accelerate solutions—building on essentially one truly “quantum advantaged” mathematical function. But these four problems lead to hundreds of business use cases that promise to unlock enormous value for end users in coming decades. ... Not only is this approach inefficient, it also lacks accuracy, especially in the face of high tail risk. And once options and derivatives become bank assets, the need for high-efficiency simulation only grows as the portfolio needs to be re-evaluated continuously to track the institution’s liquidity position and fresh risks. Today this is a time-consuming exercise that often takes 12 hours to run, sometimes much more. According to a former quantitative trader at BlackRock, “Brute force Monte Carlo simulations for economic spikes and disasters can take a whole month to run.”Can companies build on their digital surge?
 If digital is the heart of the modern organization, then data is its
lifeblood. Most companies are swimming in it. Average broadband consumption,
for example, increased 47 percent in the first quarter of 2020 over the same
quarter in the previous year. Used skillfully, data can generate insights that
help build focused, personalized customer journeys, deepening the customer
relationship. This is not news, of course. But during the pandemic, many
leading companies have aggressively recalibrated their data posture to reflect
the new realities of customer and worker behavior by including models for
churn or attrition, workforce management, digital marketing, supply chain, and
market analytics. One mining company created a global cash-flow tool that
integrated and analyzed data from 20 different mines to strengthen its
solvency during the crisis. ... While it’s been said often, it still bears
repeating: technology solutions cannot work without changes to talent and how
people work. Those companies getting value from tech pay as much attention to
upgrading their operating models as they do to getting the best tech.
If digital is the heart of the modern organization, then data is its
lifeblood. Most companies are swimming in it. Average broadband consumption,
for example, increased 47 percent in the first quarter of 2020 over the same
quarter in the previous year. Used skillfully, data can generate insights that
help build focused, personalized customer journeys, deepening the customer
relationship. This is not news, of course. But during the pandemic, many
leading companies have aggressively recalibrated their data posture to reflect
the new realities of customer and worker behavior by including models for
churn or attrition, workforce management, digital marketing, supply chain, and
market analytics. One mining company created a global cash-flow tool that
integrated and analyzed data from 20 different mines to strengthen its
solvency during the crisis. ... While it’s been said often, it still bears
repeating: technology solutions cannot work without changes to talent and how
people work. Those companies getting value from tech pay as much attention to
upgrading their operating models as they do to getting the best tech. Understanding Direct Domain Adaptation in Deep Learning
AI: The Next Generation Anti-Corruption Technology
 Artificial intelligence, according to Oxford Insights, is the “next step in
anti-corruption,” partially because of its capacity to uncover patterns in
datasets that are too vast for people to handle. Humans may focus on specifics
and follow up on suspected abuse, fraud, or corruption by using AI to discover
components of interest. Mexico is an example of a country where artificial
intelligence alone may not be enough to win the war. ... As a result, the cost
of connectivity has decreased significantly, and the government is currently
preparing for its largest investment ever. By 2024, the objective is to have a
4G mobile connection available to more than 90% of the population. In a society
moving toward digital state services, the affordable connection is critical. The
next stage is for the country to establish an AI strategy. The next national AI
strategy will include initiatives such as striving toward AI-based solutions to
offer government services for less money or introducing AI-driven smart
procurement. In brief, Mexico aspires to be one of the world’s first 10
countries to adopt a national AI policy.
Artificial intelligence, according to Oxford Insights, is the “next step in
anti-corruption,” partially because of its capacity to uncover patterns in
datasets that are too vast for people to handle. Humans may focus on specifics
and follow up on suspected abuse, fraud, or corruption by using AI to discover
components of interest. Mexico is an example of a country where artificial
intelligence alone may not be enough to win the war. ... As a result, the cost
of connectivity has decreased significantly, and the government is currently
preparing for its largest investment ever. By 2024, the objective is to have a
4G mobile connection available to more than 90% of the population. In a society
moving toward digital state services, the affordable connection is critical. The
next stage is for the country to establish an AI strategy. The next national AI
strategy will include initiatives such as striving toward AI-based solutions to
offer government services for less money or introducing AI-driven smart
procurement. In brief, Mexico aspires to be one of the world’s first 10
countries to adopt a national AI policy.Introduction to the Node.js reference architecture, Part 5: Building good containers
 Why should you avoid using reserved (privileged) ports (1-1023)? Docker or
Kubernetes will just map the port to something different anyway, right? The
problem is that applications not running as root normally cannot bind to ports
1-1023, and while it might be possible to allow this when the container is
started, you generally want to avoid it. In addition, the Node.js runtime has
some limitations that mean if you add the privileges needed to run on those
ports when starting the container, you can no longer do things like set
additional certificates in the environment. Since the ports will be mapped
anyway, there is no good reason to use a reserved (privileged) port. Avoiding
them can save you trouble in the future. ... A common question is, "Why does
container size matter?" The expectation is that with good layering and caching,
the total size of a container won't end up being an issue. While that can often
be true, environments like Kubernetes make it easy for containers to spin up and
down and do so on different machines. Each time this happens on a new machine,
you end up having to pull down all of the components.
Why should you avoid using reserved (privileged) ports (1-1023)? Docker or
Kubernetes will just map the port to something different anyway, right? The
problem is that applications not running as root normally cannot bind to ports
1-1023, and while it might be possible to allow this when the container is
started, you generally want to avoid it. In addition, the Node.js runtime has
some limitations that mean if you add the privileges needed to run on those
ports when starting the container, you can no longer do things like set
additional certificates in the environment. Since the ports will be mapped
anyway, there is no good reason to use a reserved (privileged) port. Avoiding
them can save you trouble in the future. ... A common question is, "Why does
container size matter?" The expectation is that with good layering and caching,
the total size of a container won't end up being an issue. While that can often
be true, environments like Kubernetes make it easy for containers to spin up and
down and do so on different machines. Each time this happens on a new machine,
you end up having to pull down all of the components. Now is the time to prepare for the quantum computing revolution
 We've proven that it can happen already, so that is down the line. But it's in
the five- to 10-year range that it's going to take until we have that hardware
available. But that's where a lot of the promises for these exponentially faster
algorithms. So, these are the algorithms that will use these fault-tolerant
computers to basically look at all the options available in a combinatorial
matrix. So, if you have something like Monte Carlo simulation, you can try
significantly all the different variables that are possible and look at every
possible combination and find the best optimal solution. So, that's really,
practically impossible on today's classical computers. You have to choose what
variables you're going to use and reduce things and take shortcuts. But with
these fault-tolerant computers, for significantly many of the possible solutions
in the solution space, we can look at all of the combinations. So, you can
imagine almost an infinite amount or an exponential amount of variables that you
can try out to see what your best solution is.
We've proven that it can happen already, so that is down the line. But it's in
the five- to 10-year range that it's going to take until we have that hardware
available. But that's where a lot of the promises for these exponentially faster
algorithms. So, these are the algorithms that will use these fault-tolerant
computers to basically look at all the options available in a combinatorial
matrix. So, if you have something like Monte Carlo simulation, you can try
significantly all the different variables that are possible and look at every
possible combination and find the best optimal solution. So, that's really,
practically impossible on today's classical computers. You have to choose what
variables you're going to use and reduce things and take shortcuts. But with
these fault-tolerant computers, for significantly many of the possible solutions
in the solution space, we can look at all of the combinations. So, you can
imagine almost an infinite amount or an exponential amount of variables that you
can try out to see what your best solution is.Ragnarok Ransomware Gang Bites the Dust, Releases Decryptor
 The gang is the latest ransomware group to shutter operations, due in part to
mounting pressures and crackdowns from international authorities that already
have led some key players to cease their activity. In addition to Avaddon and
SyNack, two heavy hitters in the game — REvil and DarkSide – also closed up shop
recently. Other ransomware groups are feeling the pressure in other ways. An
apparently vengeful affiliate of the Conti Gang recently leaked the playbook of
the ransomware group after alleging that the notorious cybercriminal
organization underpaid him for doing its dirty work. However, even as some
ransomware groups are hanging it up, new threat groups that may or may not have
spawned from the previous ranks of these organizations are sliding in to fill
the gaps they left. Haron and BlackMatter are among those that have emerged
recently with intent to use ransomware to target large organizations that can
pay million-dollar ransoms to fill their pockets. Indeed, some think Ragnarok’s
exit from the field also isn’t permanent, and that the group will resurface in a
new incarnation at some point.
The gang is the latest ransomware group to shutter operations, due in part to
mounting pressures and crackdowns from international authorities that already
have led some key players to cease their activity. In addition to Avaddon and
SyNack, two heavy hitters in the game — REvil and DarkSide – also closed up shop
recently. Other ransomware groups are feeling the pressure in other ways. An
apparently vengeful affiliate of the Conti Gang recently leaked the playbook of
the ransomware group after alleging that the notorious cybercriminal
organization underpaid him for doing its dirty work. However, even as some
ransomware groups are hanging it up, new threat groups that may or may not have
spawned from the previous ranks of these organizations are sliding in to fill
the gaps they left. Haron and BlackMatter are among those that have emerged
recently with intent to use ransomware to target large organizations that can
pay million-dollar ransoms to fill their pockets. Indeed, some think Ragnarok’s
exit from the field also isn’t permanent, and that the group will resurface in a
new incarnation at some point.Quote for the day:
"Leadership is a matter of having people look at you and gain confidence, seeing how you react. If you're in control, they're in control." -- Tom Laundry
No comments:
Post a Comment