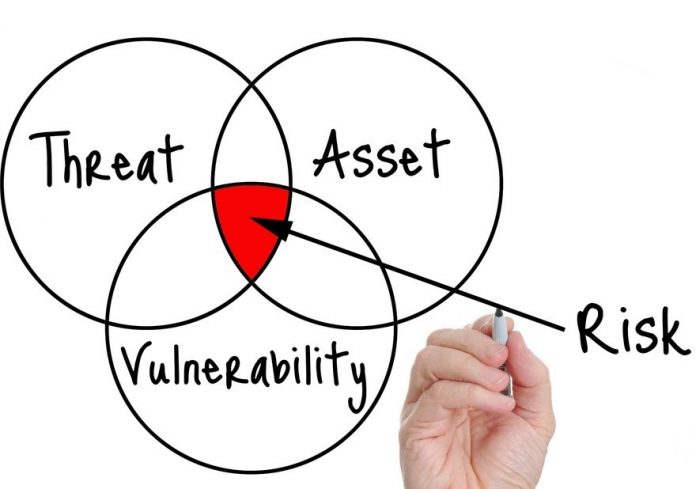
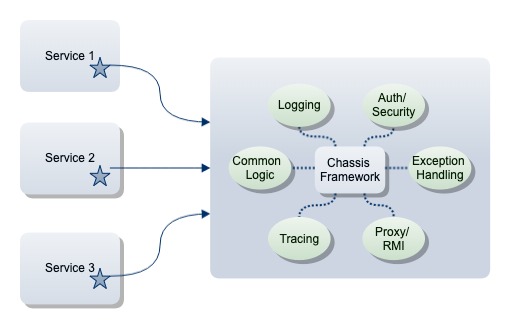
Why AI is here to stay

So here’s why AI is not a fad: in real life, there’s no way I’m giving up my ability to fall back on teaching with examples if I’m not clever enough to come up with the instructions. Absolutely not! I’m pretty sure I use examples more than instructions to communicate with other humans when I stumble around the real world. AI means I can communicate with computers that second way — via examples — not only by instructions, are you seriously asking me to suddenly gag my own mouth? Remember, in the old days we had to rely primarily on instructions only because we couldn’t do it the other way, in part because processing all those examples would strain the meager CPUs of last century’s poor desktops. But now that humanity has unlocked its ability to express itself to machines via examples, why would we suddenly give that option up entirely? A second way of talking to computers is too important to drop like yesterday’s shoulderpads. What we should drop is our expectation that there’s a one-size-fits-all way of communicating with computers about every problem. Say what you mean and say it the way that works best.
Pledges to Not Pay Ransomware Hit Reality
"I don't think you can make a blanket statement of 'pay the ransom' or 'don't pay the ransom,'" says Adam Kujawa, director of the research labs at security firms Malwarebytes. "If you have failed to segment your data or your network, or failed to check your backups or other measures to get your company back on track quickly, then you will have to deal with the fallout." One problem for companies: Ransomware operators have shifted away from blanketing consumers and businesses with opportunistic ransomware attacks and now almost exclusively target business and municipalities. Along with that shift, the cost of ransoms has quickly grown because such organizations can afford to pay. Now, many organizations are faced with seven-digit ransom demands, Zelonis says. "That's a heck of a payday," he adds. The increase in ransom demands is driven by attackers' targeting and research on victims, he says.
End of the line for Internet Explorer 10 might mean updating embedded systems

Microsoft hasn't given specific dates yet; IE11 is coming to the Update Catalog sometime in spring 2019 (which likely means before the end of June), with the other upgrade options coming later in 2019. That means you won't have many months to test and validate IE11 on any systems where you're still using IE10, so you will want to plan your test labs and pilot rings now. Microsoft deliberately didn't put the new Edge browsing engine into IE11 because of enterprise concerns that it might cause compatibility problems. Instead, it still uses the Trident engine and includes document modes that emulate the IE5, IE7, IE8, IE9 and IE10 rendering engines. There are also specific Enterprise Modes to emulate IE8, and IE8 in Compatibility View, but if your sites worked in IE 10 you won't need those. What you will need to change are sites that have the x-ua-compatible meta tag or HTTP header set to 'IE=edge'; in IE10 that means Internet Explorer 10 mode, but in IE11 it means Internet Explorer 11 mode, because it's just asking for the latest IE version. Set it to 'IE=10' if the site has problems.
Expect graph database use cases for the enterprise to take off
As useful as graph databases are for many certain types of queries and analysis, graph tools will present several challenges to CIOs, Moore warned. Data engineers and business experts need to learn new skill sets and create new workflows for defining and refining the graph data models used for these applications. Classical SQL databases were optimized to conserve memory and CPU. They are still the best technology for many kinds of applications such as ERP that involve doing a lot of columnar addition. But joining database tables together to do new kinds of queries can add considerable overhead to SQL databases. As a result, new types of queries can be limited by memory capacity. In contrast, graph databases, as noted, precompute these relationships in a way that speeds analytics and shrinks the size of the data store. In one project, Moore said he managed to shrink a 5 TB SQL database into a 2 TB graph database. A big challenge that must be factored into graph database use cases is their slower performance when writing to the database.
7 Types Of Artificial Intelligence

Since AI research purports to make machines emulate human-like functioning, the degree to which an AI system can replicate human capabilities is used as the criterion for determining the types of AI. Thus, depending on how a machine compares to humans in terms of versatility and performance, AI can be classified under one, among the multiple types of AI. Under such a system, an AI that can perform more human-like functions with equivalent levels of proficiency will be considered as a more evolved type of AI, while an AI that has limited functionality and performance would be considered a simpler and less evolved type. Based on this criterion, there are two ways in which AI is generally classified. One type is based on classifying AI and AI-enabled machines based on their likeness to the human mind, and their ability to “think” and perhaps even “feel” like humans. According to this system of classification, there are four types of AI or AI-based systems: reactive machines, limited memory machines, theory of mind, and self-aware AI.
The logic of digital change
Disruption may be a yawn, but the fact is that the internet is changing things slowly but surely, and specifically it began when cloud and APIs allowed start-ups to bootstrap and launch on a shoestring. Now, there are 12,000 start-ups globally getting investments that have been doubling down each year – $111.8 billion last year – and so there is something happening. Don’t be complacent. Nothing may have happened in the last quarter century but something will happen in the next, and only the banks that adapt will survive, as Charles Darwin would say. ... there is specifically a fourth revolution of humanity occurring where the people who historically could not be reached by banks are now being reached by technology. The financially illiterate, the folks who aren’t worth it, the financially vulnerable, the unbankable, are all getting to be included because that’s what digital does. In a world where we distribute money physically, you cannot afford to deal with someone in a remote African village; in a world where distribute money digitally, even the guy sitting in a village near the base camp of Mount Everest can trade and transact.
A.I. Ethics Boards Should Be Based on Human Rights

Human rights are imperfect ideals, subject to conflicting interpretations, and embedded in agendas with “outsized expectations.” Though supposedly global, human rights aren’t honored everywhere. Nevertheless, the United Nations Universal Declaration of Human Rights is the best statement ever crafted for establishing all-around social and legal equality and fundamental individual freedoms. The Institute of Electrical and Electronics Engineers rightly notes that human rights are a viable benchmark, even among diverse ethical traditions. “Whether our ethical practices are Western (Aristotelian, Kantian), Eastern (Shinto, Confucian), African (Ubuntu), or from a different tradition, by creating autonomous and intelligent systems that explicitly honor inalienable human rights and the beneficial values of their users, we can prioritize the increase of human well-being as our metric for progress in the algorithmic age.” Technology companies should embrace this standard by explicitly committing to a broadly inclusive and protective interpretation of human rights as the basis for corporate strategy regarding A.I. systems. They should only invite people to their A.I. ethics boards who endorse human rights for everyone.
Accelerating Digital Innovation Inside & Out

Not only are digitally maturing companies more likely to use cross-functional teams, those teams generally function differently in more mature organizations than in less mature organizations. They’re given greater autonomy, and their members are often evaluated as a unit. Participants on these teams are also more likely to say that their cross-functional work is supported by senior management. For more advanced companies, the organizing principle behind cross-functional teams is shifting from projects toward products. Digitally maturing companies are more agile and innovative, but as a result they require greater governance. Organizations need policies that create sturdy guardrails around the increased autonomy their networking strength allows. Digitally maturing companies are more likely to have ethics policies in place to govern digital business. Policies alone, however, are not sufficient. Only 35% of respondents across maturity levels say their company is talking enough about the social and ethical implications of digital business.
Three hacking trends you need to know about to help protect yourself

"The blurred lines between the techniques used by nation-state actors and those used by criminal actors have really gotten a lot fuzzier," says Jen Ayers, vice president of OverWatch cyber intrusion detection and security response at CrowdStrike. "Many criminal organisations are still very loud, but the fact is rather than going the traditional spam email route that they have been before, they are actively intruding onto enterprise networks, they are targeting unsecured web servers and going in, stealing credentials and doing reconnaissance," she adds. This is another tactic which malicious threat actors are beginning to deploy in order to both avoid detection and make attacks more effective – conducting campaigns that don't focus on Windows PCs and other common devices used in the enterprise. With these devices sitting in front of users every single day, and a top priority for antivirus software, there's a higher chance that an attack on these devices will either be prevented by security measures or spotted by users.
Data Strategy: Essential elements to enhance it
Elena Alfaro, head of data and open innovation at the client solutions division of the Spanish bank BBVA, described her organization's work of "spreading the culture of data" and ensuring that the senior leadership of an organization is on board with the data initiatives. "What I've learned is if the person you're sitting with doesn't understand, it is very difficult to get to something big," said Alfaro. For the past two years, Forrester has ranked the BBVA's mobile app the best in the banking business. Forrester's Aurelie L'Hostis credited the bank's app for "striking a superb balance between useful functionality and excellent user experience," a product that Alfaro says grew out of a data strategy with the end user in mind. "Digital banks listen to their customers, they're clever with data, and they work hard on making it easy for customers to manage their financial lives," L'Hostis writes. "It's not a small feat, but that's what your customers are demanding." But regardless of the industry, Wixom argues that companies with a successful data strategy implement a framework that ensures a high level of data integrity and makes sure that it is broadly and easily accessible.
Quote for the day:
"Each day you are leading by example. Whether you realize it or not or whether it's positive or negative, you are influencing those around you." -- Rob Liano