Software Ate The World, Now AI Is Eating Software

The extent in which Andreessen’s cherished software companies are weaving AI into their products is however often limited. Instead, a new slew of start-ups now incorporates an infrastructure based around the above mentioned AI-facilitating processes from their very foundation. Driven by an increase in efficiency, these new companies use AI to automate and optimize the very core processes of their business. As an example, no less than 148 start-ups are aiming to automate the very costly process of drug development in the pharmaceutical industry according to a recent update on BenchSci. Likewise, AI start-ups in the transportation sector create value by optimizing shipments, thus vastly reducing the amount of empty or idle transports. Also, the process of software development itself is affected. AI-powered automatic code completion and generation tools such as TabNine, TypeSQL and BAYOU, are being created and made ready to use.
The disruption effort began after Avast in March traced back a rise in stealthy cryptocurrency mining infections to variants of a worm called Retadup, written in both AutoIt and AutoHotkey scripts. Researchers began studying the command-and-control communications being used to control infected endpoints, or bots, says Jan Vojtesek, a malware researcher at Avast, in a research report. "After analyzing Retadup more closely, we found that while it is very prevalent, its C&C communication protocol is quite simple," he says. "We identified a design flaw in the C&C protocol that would have allowed us to remove the malware from its victims' computers had we taken over its C&C server." Avast alerted France's national cybercrime investigation team, C3N, that servers in France appeared to be hosting the majority of the command-and-control infrastructure for distributing and controlling the Retadup worm - in other words, self-replicating malware. Avast also shared a technique that it thought might allow authorities to neutralize existing infections.

Unlike some companies where departmental work groups are not always accessible to those outside those groups, Facebook employees can participate in any group. “Most of those groups are what we call open QA. What that means is that people outside of those groups can also see the information. And you’ll be surprised how this tackles a number of challenging problems as the company grows,” Nguyen said. For one, open work groups will help to prevent duplication of projects, since developers can see what other teams are doing, and avoid building the same things. In cases where duplicate projects are already being built, Nguyen would step in to bring the teams together in an open dialogue. “There were a few teams within infrastructure and Instagram that were building different technologies for logging of data,” Nguyen recalled. “One of the engineers at Instagram escalated [the issue] to me and I set up a meeting for them to work together.”
4 Cybersecurity Professionals That Can Benefit from Threat Intelligence
The first layer of defense that most organizations rely on is their own security operation center (SOC). Whether outsourced or in-house, security operations analysts need to possess a broad set of skills to be effective. This includes capabilities in log monitoring, penetration testing, incident response, access management, and more. Each one of these tasks requires a different group of systems and solutions to work well, which are usually not integrated. This means that SOCs often have to deal with unending alerts and big data that may not come with much context. Threat intelligence enriches alert management. It provides context to help SOCs know which alerts need to be prioritized. Some threat intelligence platforms readily offer this kind of automation using machine learning (ML) or similar technologies. Just like SOCs, incident response teams face the challenge of getting information that lacks context. They are also bombarded with numerous alerts from their security information and event management (SIEM) solutions and so are forced to choose which ones to prioritize.
Cloud Storage Is Expensive? Are You Doing it Right?

A common solution, adopted by a significant number of organizations now, is data repatriation. Bringing back data on premises (or a colocation service provider), and accessing it locally or from the cloud. Why not? At the end of the day, the bigger the infrastructure the lower the $/GB and, above all, no other fees to worry about. When thinking about petabytes, there are several ways to optimize and take advantage of which can lower the $/GB considerably: fat nodes with plenty of disks, multiple media tiers for performance and cold data, data footprint optimizations, and so on, all translating into low and predictable costs. At the same time, if this is not enough, or you want to keep a balance between CAPEX and OPEX, go hybrid. Most storage systems in the market allow to tier data to S3-compatible storage systems now, and I’m not talking only about object stores – NAS and block storage systems can do the same. I covered this topic extensively in this report but check with your storage vendor of choice and I’m sure they’ll have solutions to help out with this.
The First Artificial Memory Has Been Successfully Created and Implanted
Previous research had shown that it was possible to partially transfer memories from one rodent to another via reproducing the electrical activity associated with a specific memory in one mouse and jolting it into the brain of another mouse. This new experiment is different. This time the memory was created completely artificially from the ground up. This consisted of a few parts. First, they used a technique called optogenetics. This involves fiber optic cables surgically implanted into the olfactory region of the mice’s brain so that light can be used to turn on proteins associated with specific smells. To do that, the mice had to be genetically engineered to only produce the light-sensitive protein in the region associated with acetophenone—AKA the scent of cherry blossoms. Now they could artificially create the scent of cherry blossoms in the brain of a mouse. So we’re already into some wacky stuff, but don’t worry. It gets wackier.
Semi-supervised learning explained

Self-training uses a model’s own predictions on unlabeled data to add to the labeled data set. You essentially set some threshold for the confidence level of a prediction, often 0.5 or higher, above which you believe the prediction and add it to the labeled data set. You keep retraining the model until there are no more predictions that are confident. This begs the question of the actual model to be used for training. As in most machine learning, you probably want to try every reasonable candidate model in the hopes of finding one that works well. Self-training has had mixed success. The biggest flaw is that the model is unable to correct its own mistakes: one high-confidence (but wrong) prediction on, say, an outlier, can corrupt the whole model. Multi-view training trains different models on different views of the data, which may include different feature sets, different model architectures, or different subsets of the data. There are a number of multi-view training algorithms, but one of the best known is tri-training.
Sprint Reviews With Kanban
Kanban is sometimes thought of as a soft option because “flow” is misinterpreted as “whatever gets delivered gets delivered”. A team will start with what it is, realistically, doing now. There is no need to vamp Sprints. The odious Sprint Goal and the contrived forecast of work in the Sprint Backlog are dispensed with. It looks as if the team can no longer be held hostage to fortune. In Kanban there is no Great Lie to be fabricated about a planned Sprint outcome, and, it is assumed, there is no great commitment that can hang over team members’ heads like the Sword of Damocles. What possible use for a monstrous Sprint Review can there be? Instead, there ought to be a succession of mini-reviews with the Product Owner as each item is completed. Having mini-reviews can be useful and timely, and they are all very well. In truth, however, a professional Kanban team will not escape from making a serious commitment, nor would a team ever seek to do so. For one thing, its members will need to understand and define a commitment point in their workflow.
Hackers Hit Unpatched Pulse Secure and Fortinet SSL VPNs
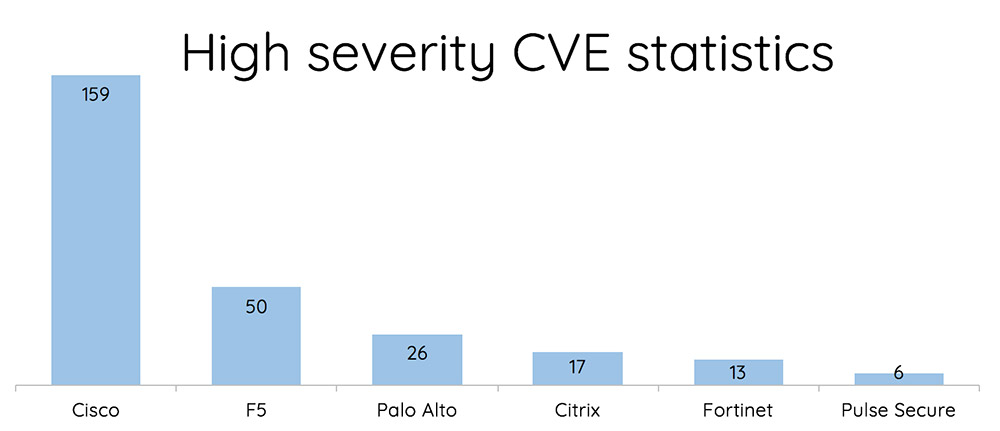
Based on their count of recent publicly exposed common vulnerabilities and exposures in SSL VPNs, it appeared that Cisco equipment would be the riskiest to use. To test that hypothesis, the researchers began looking at SSL VPNs and found exploitable flaws in both Pulse Secure and Fortinet equipment. The researchers reported flaws to Fortinet on Dec. 11, 2018, and to Pulse Secure on March 22. ... In response, Fortinet released a security advisory on May 24 and updates to fix 10 flaws, some of which could be exploited to gain full, remote access to a device and the network it was meant to be protecting. In particular, it warned that one of the flaws, "a path traversal vulnerability in the FortiOS SSL VPN web portal" - CVE-2018-13379 - could be exploited to enable "an unauthenticated attacker to download FortiOS system files through specially crafted HTTP resource requests." Such FortiOS system files contain sensitive information, including passwords, meaning attackers could quickly give themselves a way to gain full access to an enterprise network.
How to bolster IAM strategies using automation

Litton argues that automation is also important for protecting critical data assets. “An example of this is when an employee leaves an organisation or a technology supplier relationship ends,” he says. “Automation can ensure that their accounts do not remain in an active state, thus eliminating a potential avenue through which bad actors can access data. When implemented properly, automated IAM solutions can also identify orphan accounts automatically and alert system owners.” Identity management systems comprise users, applications and policies, all of which govern how people are able to use software. Litton says automated IAM systems can fully automate identity creation at scale; automatically manage user access; apply role- and attribute-driven policies; and completely remove the need for passwords, helping to improve the user experience, while decreasing the helpdesk support burden.
Quote for the day:
"Leaders keep their eyes on the horizon, not just on the bottom line." -- Warren G. Bennis
No comments:
Post a Comment