Take My Drift Away
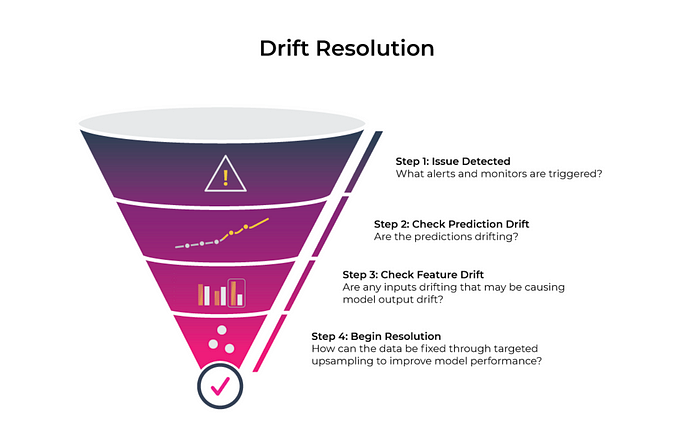
Drift is a change in distribution over time. It can be measured for model
inputs, outputs, and actuals. Drift can occur because your models have grown
stale, bad data is flowing into your model, or even because of adversarial
inputs. Now that we know what drift is, how can we keep track of it?
Essentially, tracking drift in your models amounts to keeping tabs on what had
changed between your reference distribution, like when you were training your
model, and your current distribution (production). Models are not static. They
are highly dependent on the data they are trained on. Especially in hyper-growth
businesses where data is constantly evolving, accounting for drift is important
to ensure your models stay relevant. Change in the input to the model is almost
inevitable, and your model can’t always handle this change gracefully. Some
models are resilient to minor changes in input distributions; however, as these
distributions stray far from what the model saw in training, performance on the
task at hand will suffer. This kind of drift is known as feature drift or data
drift. It would be amazing if the only things that could change were the inputs
to your model, but unfortunately, that’s not the case.
7 best practices for enterprise attack surface management

To mount a proper defense, you must understand what digital assets are exposed,
where attackers will most likely target a network, and what protections are
required. So, increasing attack surface visibility and building a strong
representation of attack vulnerabilities is critical. The types of
vulnerabilities to look for include older and less secure computers or servers,
unpatched systems, outdated applications, and exposed IoT devices. Predictive
modeling can help create a realistic depiction of possible events and their
risks, further strengthening defense and proactive measures. Once you understand
the risks, you can model what will happen before, during and after an event or
breach. What kind of financial loss can you expect? What will be the
reputational damage of the event? Will you lose business intelligence, trade
secrets or more? “The successful [attack surface mapping] strategies are pretty
straightforward: Know what you are protecting (accurate asset inventory);
monitor for vulnerabilities in those assets; and use threat intelligence to know
how attackers are going after those assets with those vulnerabilities,” says
John Pescatore, SANS director of emerging security trends.
How Chainyard built a blockchain to bring rivals together

There’s the technology of building the blockchain, and then there’s building the
network and the business around that. So there are multiple legs to the stool,
and the technology is actually the easiest piece. That’s just establishing
architecturally how you want to embody that network, how many nodes, how many
channels, how your data is going to be structured, and how information is going
to move among the blockchain. But the more interesting and challenging exercise,
as is true with any network, is participation. I think it was Marc Andreessen
who famously said “People are on Facebook because people are on Facebook.” You
have to drive participation, so you have to consider how to bring participants
to this network, how organizations can be engaged, and what’s going to make it
compelling for them. What’s the value proposition? What are they going to get
out of it? How do you monetize and how do you operate it? And you can’t figure
that on the fly. So we went out to bring the top-of-the-food-chain organizations
in various industries on board, so they can help establish the inertia for the
network to take off.
Strategies, tools, and frameworks for building an effective threat intelligence team
The big three frameworks are the Lockheed Martin Cyber Kill Chain®, the Diamond
Model, and MITRE ATT&CK. If there’s a fourth, I would add VERIS, which is
the framework that Verizon uses for their annual Data Breach Investigations
Report. I often get asked which framework is the best, and my favorite answer as
an analyst is always, “It depends on what you’re trying to accomplish.” The
Diamond Model offers an amazing way for analysts to cluster activity together.
It’s very simple and covers the four parts of an intrusion event. For example,
if we see an adversary today using a specific malware family plus a specific
domain pattern, and then we see that combination next week, the Diamond Model
can help us realize those look similar. The Kill Chain framework is great for
communicating how far an incident has gotten. We just saw reconnaissance or an
initial phish, but did the adversary take any actions on objectives? MITRE
ATT&CK is really useful if you’re trying to track down to the TTP level.
What are the behaviors an adversary is using? You can also incorporate these
different frameworks.
Bulding a Scalable Data Service in the Modern Microservices World

The microservices architecture not only makes the whole application much more
decoupled and cohesive, it also makes the teams more agile to make frequent
deployments without interrupting or depending on others. The communication among
services is most commonly done using HyperText Transfer Protocol. The Request
and Response format (XML or JSON) is known as API Contract and that’s what binds
services together to form the complete behaviour of the application. In the
given example above, we are talking about an application that serves both Web
and Mobiles users, and allows external services to integrate using REST API
endpoints provided to end-users. Each of the use cases have their own endpoints
exposed in front of individual Load Balancers that manages Incoming Requests
with best available resources. Each of the internal services contains a Web
Server that handles all incoming requests and forwards them to the right
services or sends it to in-house application, an Application Server that hosts
all the business logic of the microservice, and a quasi-persistent layer, a
Local Replication of the Database based on Spatial and/or Temporal locality of
data.
Validation of Autonomous Systems
Autonomous systems have complex interactions with the real world. This raises
many questions about the validation of autonomous systems: How to trace back
decision making and judge afterwards about it? How to supervise learning,
adaptation, and especially correct behaviors – specifically when critical corner
cases are observed? Another challenge would be how to define reliability in the
event of failure. With artificial intelligence and machine learning, we need to
satisfy algorithmic transparency. For instance, what are the rules in an
obviously not anymore algorithmically tangible neural network to determine how
an autonomous system might react with several hazards at the same time? Classic
traceability and regression testing will certainly not work. Rather, future
verification and validation methods and tools will include more intelligence
based on big data exploits, business intelligence, and their own learning, to
learn and improve about software quality in a dynamic way.
The New Future Of Work Requires Greater Focus On Employee Engagement

When it comes down to it, engagement is all about employee empowerment—helping
employees not just be satisfied in their work but feeling like a valued member
of the team. Unfortunately 1 in 4 is planning to look for work with a new
employer once the pandemic is over largely due to a lack of empowerment in the
workplace—a lack of advancement, upskilling opportunities, and more.
Organizations like Amazon, Salesforce, Microsoft, AT&T, Cognizant and
others have started upskilling initiatives designed to help employees,
wherever they are in the company, advance to new positions. These
organizations are taking an active role in the lives of their employees and
are helping them grow. These reasons are likely why places like Amazon
repeatedly top the list for best places to work. Before the pandemic, just 24%
of businesses felt employee engagement was a priority. Following the pandemic,
the number hit nearly 36%. Honestly, that’s still shockingly low! It’s just
common sense that engaged employees will serve a company better.
Architectural Considerations for Creating Cloud Native Applications
The ability to deploy applications with faster development cycles also opens
the door to more flexible, innovative, and better-tailored solutions. All this
undoubtedly positively impacts customer loyalty, increases sales, and lowers
operating costs, among other factors. As we mentioned, microservices are the
foundation of cloud native applications. However, their real potential can be
leveraged by containers, which allows them to package the entire runtime
environment and all its dependencies, libraries, binaries, etc., into a
manageable, logical unit. Application services can then be transported,
cloned, stored or used on-demand as required. From a developer’s perspective,
the combination of microservices and containers can support the 12-Factor App
methodology. This methodology aims primarily to avoid the most common problems
programmers face when developing modern cloud native applications. The
benefits of following the guidelines proposed by the 12 Factors methodology
are innumerable.
How to be successful on the journey to the fully automated enterprise

When first embarking on automation, many businesses feel like they would like
to keep their options open and use the time available to explore what
automation can do for their teams and their businesses. The first step in
journey to full automation is often a testing phase which relies on proving a
return on investment and consequently convincing the C-suite, departmental
heads, and IT of its benefits. Next, once automation has been added to the
agenda, in order to support with providing a centralised view and governance,
organizations should create an RPA Centre of Excellence to champion and drive
use of the technology. At this stage, select processes are chosen, often in
isolation, based on the fact that they have high-potential but are low-value
tasks which can quickly be automated and show immediate returns in terms of
increased productivity or customer satisfaction. This top-down,
process-by-process approach, implemented by RPA experts, will help automation
programs get off the ground. NHS Shared Business Service (SBS), for example,
chose the highly labour-intensive task of maintaining cashflow files as its
first large-scale automation.
SOC burnout is real: 3 preventative steps every CISO must take
While most technology solutions aim to make the SOC/IR more efficient and
effective, all too often organizations take one step forward and two steps
back if the solution creates ancillary workloads for the team. The first
measurement of a security tool is if it addresses the pain or gap that the
organization needs to fill. The second measurement is if the tool is
purpose-built by experts who understand the day-to-day responsibilities of the
SOC/IR team and consider those as requirements in the design of their
solution. As an example, there is a trend in the network detection and
response (NDR) market to hail the benefits of machine learning (ML). Yes, ML
helps to identify adversary behavior faster than manual threat hunting, but at
what cost? Most anomaly-based ML NDR solutions require staff to perform
in-depth “detection training” for four weeks plus tedious ongoing training to
attempt to make the number of false positives “manageable.” Some security
vendors are redefining their software as a service (SaaS) offering as
Guided-SaaS. Guided-SaaS security allows teams to focus on what matters –
adversary detection and response.
Quote for the day:
"Leaders dig into their business to
learn painful realities rather than peaceful illusion." --
Orrin Woodward
No comments:
Post a Comment