What is an office for now?

Working from home does work for a lot of people; I’ve been working from home
since way before it was cool. But it can be terrible — isolating and
uncomfortable, with blurred boundaries that make it too easy to keep working
well past “office hours” but equally too easy to drift away from your desk to
load the dishwasher. One survey on working from home, conducted by the
Institute for Employment Studies in the U.K. early in its lockdown, found that
more than half of respondents reported new musculoskeletal complaints,
including neck and back pain, while their diet and exercise suffered. Many of
them said they slept less and worried more. ... Additionally, asking employees
to turn their home into an office makes employers more responsible for what
happens there, while simultaneously making it more difficult to assess worker
well-being. “I’ve spent a lot of my time making sure that people are OK in a
way that you can do very, very swiftly in the office,” Sam Bompas, director at
Bompas & Parr, a London-based experience design studio with approximately
20 employees, told me. “In the same way that for children, school provides an
important social security function, if there’s anything wrong in [employees’]
personal life, the office can do that as well.”
Most IoT Hardware Dangerously Easy to Crack
One of the easiest methods is to gain access to UART, or Universal
Asynchronous Receiver/Transmitter, a serial interface used for diagnostic
reporting and debugging in all IoT products, among other things. An attacker
can use the UART to gain root shell access to an IoT device and then download
the firmware to learn its secrets and inspect for weaknesses. "UART is only
supposed to be used by the manufacturer. When you get access to it, in most
cases you get complete root access," Rogers said. Protecting access to UART,
or at least configuring it against interactive access, should be a fairly
straightforward task for manufacturers; however, most don't make the effort.
"They simply allow you to have complete interactive shell. It is the easiest
way to hack every piece of IoT hardware," Rogers noted. Several devices even
have UART pin names labeled on the board so it is easy to find the interface.
Multiple tools are available to help find them if they are not labeled.
Another, only slightly more challenging, route to completely pwning an IoT
device is via JTAG, a microcontroller-level interface that is used for
multiple purposes including testing integrated circuits and programming flash
memory.
Principles for Microservice Design: Think IDEALS, Rather than SOLID

The goal of interface segregation for microservices is that each type of
frontend sees the service contract that best suits its needs. For example: a
mobile native app wants to call endpoints that respond with a short JSON
representation of the data; the same system has a web application that uses
the full JSON representation; there’s also an old desktop application that
calls the same service and requires a full representation but in XML.
Different clients may also use different protocols. For example, external
clients want to use HTTP to call a gRPC service. Instead of trying to impose
the same service contract (using canonical models) on all types of service
clients, we "segregate the interface" so that each type of client sees the
service interface that it needs. How do we do that? A prominent alternative is
to use an API gateway. It can do message format transformation, message
structure transformation, protocol bridging, message routing, and much more. A
popular alternative is the Backend for Frontends (BFF) pattern. In this case,
we have an API gateway for each type of client -- we commonly say we have a
different BFF for each client, as illustrated in this figure.
Ethical and professional data science needed to avoid further algorithm controversies

Identifying weaknesses in the attempts to ensure objectivity, the BCS report
also said there is a need for clarity around what information systems are
intended to achieve at the individual level, and that this should be
established “right at the start” of the process. For example, distributing
grades based on the characteristics of different cohorts of students so they
are statistically in line with previous years – which is what the Ofqual
algorithm did – is different to ensuring each individual student is treated as
fairly as possible, something which should have been discussed and understood
by all stakeholders from the beginning, it said. In terms of accountability,
BCS said: “It is essential to develop effective mechanisms for the joint
governance of the design and development of information systems right at the
start.” Although it refrained from apportioning blame, it added: “The current
exam-grading situation should not be attributed to any single government
department or office.” CEO of the RSS, Stian Westlake, however, told Sky News
the results fiasco was “a predictable surprise” because of DfE’s demand that
Ofqual reduce grade inflation.
Why you shouldn’t mistake AI for automation

AI and automation cannot be mistaken for the same thing—where there’s
automation, there is no requirement that artificial intelligence is involved.
Indeed, automation has been around for centuries, far longer than we’ve had
computers: traditional milling used water wheels to automate manual processes
that human labor would otherwise have been required for. Water spins the
wheel, which turns the millstone—an automated process that’s decidedly
unintelligent. Simple automation has been the cornerstone of many businesses
for years. For example, a process of sending out invoices may be automated
once inputs into spreadsheets have been confirmed by people in the accounts
department. Automation means that machines are replicating human tasks. But AI
demands that the machines are also replicating human thinking. This means
programming that can reflect on its own procedures and make decisions outside
the scope of its own programming. Ultimately, machine learning requires a
machine to react dynamically to changing variables. This is a fundamentally
different objective to automation, which is essentially about teaching
machines to perform repetitive tasks with predictable inputs. For this reason,
applying machine learning to any automated process may be a case of
overengineering.
Convert PDFs to Audiobooks with Machine Learning
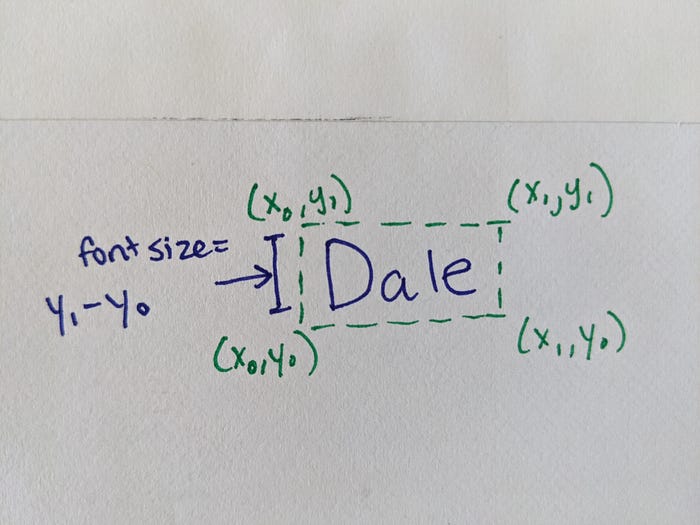
When you look at a research paper, it’s probably easy for you to gloss over
the irrelevant bits just by noting the layout: titles are large and bolded;
captions are small; body text is medium-sized and centered on the page. Using
spatial information about the layout of the text on the page, we can train a
machine learning model to do that, too. We show the model a bunch of examples
of body text, header text, and so on, and hopefully it learns to recognize
them. This is the approach that Kaz, the original author of this project, took
when trying to turn textbooks into audiobooks. Earlier in this post, I
mentioned that the Google Cloud Vision API returns not just text on the page,
but also its layout. ... The book Kaz was converting was, obviously, in
Japanese. For each chunk of text, he created a set of features to describe it:
how many characters were in the chunk of text? How large was it, and where was
it located on the page? What was the aspect ratio of the box enclosing the
text (a narrow box, for example, might just be a side bar)? Notice there’s
also a column named “label” in that spreadsheet above. That’s because, in
order to train a machine learning model, we need a labeled training dataset
from which the model can “learn.”
Zero-trust framework ripe for modern security challenges

Adopting a zero-trust security model is not an overnight process. "Younger
companies with advanced architectures and less legacy equipment have an
advantage since they are already utilizing new technology and are up to speed
on new technology," said Pete Lindstrom, vice president of security research
with IDC's IT Executive Program. Legacy infrastructure is an obstacle
companies face when trying to shift to a zero-trust approach. A common yet
misguided course of action is to conduct a massive overhaul of security
infrastructure. "Companies often make the mistake of trying to boil the ocean
and go way too broad in scope," Cunningham said. "They should focus in on
granular things they can achieve one at a time, like enabling multifactor
authentication, remote access control and disabling file shares." Since
zero-trust security is a hot buzzword, businesses should be wary in terms of
how they evaluate potential vendors since many like to pitch their products as
zero trust when they really aren't. "Rule No. 1: Companies should make sure
the vendor is using zero trust [in its own network] so they are buying
something from someone who understand their pains," Cunningham said.
.NET CLI Templates in Visual Studio
One of the values of using tools for development is the productivity they provide in helping start projects, bootstrapping dependencies, etc. One way that we’ve seen developers and companies deliver these bootstrapping efforts is via templates. Templates serve as a useful tool to start projects and add items to existing projects for .NET developers. Visual Studio has had templates for a long time and .NET Core’s command-line interface (CLI) has also had the ability to install templates and use them via `dotnet new` commands. However, if you were an author of a template and wanted to have it available in the CLI as well as Visual Studio you had to do extra work to enable the set of manifest files and installers to make them visible in both places. We’ve seen template authors navigate to ensuring one works better and that sometimes leaves the other without visibility. We wanted to change that. Starting in Visual Studio 16.8 Preview 2 we’ve enabled a preview feature that you can turn on that enables all templates that are installed via CLI to now show as options in Visual Studio as well.How to predict new consumer behaviour in the Covid-19 era

Keeping tabs on what consumers are buying is the easiest way to get your data
– predicting which products will grow and which won’t is where the gold is.
While some product changes will be obvious — it’s unsurprising that purchase
of medical supplies and non-perishable foodstuffs has increased — a 652% rise
in the purchase of bread machines suggests that we don’t quite have the skills
of Paul Hollywood just yet. There is also insight to be had in observing the
products which have decreased in popularity over lockdown. Camera sales
reduced by 64% over the previous 4 months. As social events such as holidays,
birthdays and weddings were cancelled, so was the need to bag a new ‘social
accessory’ for the occasion. Think about how your product suite fits around
these trends and whether these trends are short term reactions, or long term
shifts in behaviour. Can you scale back on a certain line of products or
diversify your range to meet a new product demand? A shift to working — and
playing — from home has driven significant demand for new purchases. With 43%
of adults now working from home, companies that can help transform our homes
into multipurpose activity hubs are rising in popularity.
How to make complicated machine learning developer problems easier to solve

Many of the difficulties in building efficient AI companies happen when facing
long-tailed distributions of data….It's becoming clear that long-tailed
distributions are also extremely common in machine learning, reflecting the
state of the real world and typical data collection practices…. Current ML
techniques are not well equipped to handle [long-tail distributions of data].
Supervised learning models tend to perform well on common inputs (i.e. the head
of the distribution) but struggle where examples are sparse (the tail). Since
the tail often makes up the majority of all inputs, ML developers end up in a
loop--seemingly infinite, at times--collecting new data and retraining to
account for edge cases. And ignoring the tail can be equally painful, resulting
in missed customer opportunities, poor economics, and/or frustrated users.
Unfortunately, the answer isn't to throw more computational horsepower or data
at the problem. The very problem of disparate data across diverse customer
inputs contributes to diseconomies of scale, whereby it may cost 10X more (in
terms of data, infrastructure, and more) to generate a 2X improvement.
Quote for the day:
“Our greatest glory is not in never failing, but in rising up every time we fail.” -- Ralph Waldo Emerson
No comments:
Post a Comment