Defining the Possible Approaches to Optimum Metadata Management

Metadata has been the focus of a lot of recent work, both in academia and
industry. As more and more electronic data is generated, stored, and managed,
metadata generation, storage, and management promise to improve the utilization
of that data. Data and metadata are intrinsically linked, hence the concept can
be found in any possible application area and can take numerous forms depending
on its application context. However, it is found that metadata is often employed
in scientific computations just for the initial data selection; at the most,
metadata about query results are recovered after the query has been successfully
executed and correlated. As a result, throughout the query processing procedure,
a vast amount of information that may be useful for analyzing query results is
not utilized. Thus, the data need "refinements". There are two distinct
definitions of "refinements". The first is the addition of qualifiers that
clarify or enlarge an element's meaning. While such modifications may be
necessary or even necessary for a particular metadata application, for the sake
of interoperability, the values of such elements can be regarded as subtypes of
a broader element.
Data Contracts — ensure robustness in your data mesh architecture
In cases where many applications are coupled to each other, a cascading effect
sometimes can be seen. Even a small change to a single application can lead to
the adjustment of many applications at the same time. Therefore, many architects
and software engineers avoid building coupled architectures. Data contracts are
positioned to be the solution to this technical problem. A data contract
guarantees interface compatibility and includes the terms of service and service
level agreement (SLA). The terms of service describe how the data can be used,
for example, only for development, testing, or production. The SLA typically
also describes the quality of data delivery and interface. It also might include
uptime, error rates, and availability, as well deprecation, a roadmap, and
version numbers. Data contracts are in many cases part of a metadata-driven
ingestion framework. They’re stored as metadata records, for example, in a
centrally managed metastore, and play an important role for data pipeline
execution, validation of data types, schemas, interoperability standards,
protocol versions, defaulting rules on missing data, and so on. Therefore, data
contracts include a lot of technical metadata.
What’s behind the cloud talent crisis — and how to fix it

The problem is that there aren’t enough experienced, trained engineers necessary
to meet that need. And even folks who have been in the thick of cloud technology
from the start are finding themselves rushing to stay abreast of the evolution
of cloud technology, ensuring that they’re up on the newest skills and the
latest changes. Compounding the issue, it’s an employee’s market, where job
seekers are spoiled for choice by an endless number of opportunities. Companies
are finding themselves in fierce competition, fishing during a drought in a pool
that keeps shrinking. “It’s going to require so many more experienced, trained
engineers than we currently have,” said Cloudbusing host Jez Ward during the
Cloud Trends 2022 thought leadership podcast series at ReInvent. “We’re taking
it exceptionally seriously, and we probably have it as our number one risk that
we’re managing. As we talk to some of our partner organizations, they see this
in the same way.” Cloudbusting podcast hosts Jez Ward and Dave Chapman were
joined by Tara Tapper, chief people officer at Cloudreach and Holly Norman,
Cloudreach’s head of AWS marketing to talk about what’s behind the tech crisis,
and how companies can meet this challenge.
Meta AI’s Sparse All-MLP Model Doubles Training Efficiency Compared to Transformers
Transformer architectures have established the state-of-the-art on natural
language processing (NLP) and many computer vision tasks, and recent research
has shown that All-MLP (multi-layer perceptron) architectures also have strong
potential in these areas. However, although newly proposed MLP models such as
gMLP (Liu et al., 2021a) can match transformers in language modelling
perplexity, they still lag in downstream performance. In the new paper
Efficient Language Modeling with Sparse all-MLP, a research team from Meta AI
and the State University of New York at Buffalo extends the gMLP model with
sparsely activated conditional computation using mixture-of-experts (MoE)
techniques. Their resulting sMLP sparsely-activated all-MLP architecture
boosts the performance of all-MLPs in large-scale NLP pretraining, achieving
training efficiency improvements of up to 2x compared to transformer-based
mixture-of-experts (MoE) architectures, transformers, and gMLP.
How to build a better CIO-CMO relationship

The CIO should be regularly and actively engaging the CMO for assistance in
"telling the story" of new technology investments. For example, they should
share how the new HR system not only provided a good ROI and TCO, but made
employees' lives easier and better. Technology vendors are well aware of the
value of having their technology leaders "tell the story." The deputy CIO of
Zoom spends a considerable amount of time evangelizing about the company and
its products -- and is highly effective at it. Spotify has a well-regarded
series of videos about how its DevOps culture helps it succeed. CIOs at
non-technology companies -- or more accurately, at companies that produce
products other than hardware, software and cloud services -- would do well to
take a page from the technology CIO's playbook. CMOs and their teams can
assist CIOs and their teams with developing a campaign to market a new
technology implementation. They can ensure the campaign captures the
appropriate attention of the desired constituencies, up to and including
developing success metrics, so CIOs are able to assess how effective they're
being.
Matter smart home standard delayed until fall 2022
:format(webp)/cdn.vox-cdn.com/uploads/chorus_image/image/70634992/acastro_211117_4887_0001.0.jpg)
The CSA is also allowing more time for the build and verification of a larger
than expected number of platforms (OS’s and chipsets), which it hopes will see
Matter launch with a healthy slate of compatible Matter devices, apps, and
ecosystems. This need arose over the last year based on activity seen on the
project’s Github repository. More than 16 platforms, including OS platforms
like Linux, Darwin, Android, Tizen, and Zephyr, and chipset platforms from
Infineon, Silicon Labs, TI, NXP, Nordic, Espressif Systems and Synaptics will
now support Matter. “We had thought there would be four or five platforms, but
it’s now more than 16,” says Mindala-Freeman. “The volume at which component
and platform providers have gravitated to Matter has been tremendous.” The
knock-on effect of these SDK changes is that the CSA needs to give its 50
member companies who are currently developing Matter-capable products another
chance to test those devices before they go through the Matter certification
process. The CSA also shared details of that initial certification process
with The Verge. Following a specification validation event (SVE) this
summer
PyTorch Geometric vs Deep Graph Library
Arguably the most exciting accomplishment of deep learning with graphs so far
has been the development of AlphaFold and AlphaFold2 by DeepMind, a project
that has made major strides in solving the protein structure prediction
problem, a longstanding grand challenge of structural biology. With myriad
important applications in drug discovery, social networks, basic biology, and
many other areas, a number of open-source libraries have been developed for
working with graph neural networks. Many of these are mature enough to use in
production or research, so how can you go about choosing which library to use
when embarking on a new project? Various factors can contribute to the choice
of GNN library for a given project. Not least of all is the compatibility with
you and your team’s existing expertise: if you are primarily a PyTorch shop it
would make sense to give special consideration to PyTorch Geometric, although
you might also be interested in using the Deep Graph Library with PyTorch as
the backend (DGL can also use TensorFlow as a backend).
The No-Code Approach to Deploying Deep Learning Models on Intel® Hardware
Deep learning has two broad phases: training and inference. During training,
computers build artificial neural network models by analyzing thousands of
inputs—images, sentences, sounds—and guessing at their meaning. A feedback
loop tells the machine if the guesses are right or wrong. This process repeats
thousands of times, creating a multilayered network of algorithms. Once the
network reaches its target accuracy, it can be frozen and exported as a
trained model. During deep learning inference, a device compares incoming data
with a trained model and infers what the data means. For example, a smart
camera compares video frames against a deep learning model for object
detection. It then infers that one shape is a cat, another is a dog, a third
is a car, and so on. During inference, the device isn’t learning; it’s
recognizing and interpreting the data it receives. There are many popular
frameworks—like TensorFlow PyTorch, MXNet, PaddlePaddle—and a multitude of
deep learning topologies and trained models. Each framework and model has its
own syntax, layers, and algorithms.
Operational resilience is much more than cyber security

To a Chief Information Officer, for example, an IT department can’t be
considered operationally resilient without the accurate, actionable data
necessary to keep essential business services running. To a Chief Financial
Officer, meanwhile, resilience involves maintaining strong financial reporting
systems in order to maintain vigilance over spend and savings. This list could
run on and on, but while resilience manifests itself differently to different
departments, no aspect of an enterprise organisation exists in a vacuum. True
resilience involves understanding connections between different aspects of a
business – and the dependencies between the various facets of its
infrastructure. To understand the connections and dependencies between
business services, customer journeys, business applications, and cloud /
legacy infrastructure, and so on, large organisations need to invest in tools
like configuration management databases (CMDBs). With the visibility and
knowledge that a CMDB provides, organisations can strengthen their resilience
by understanding and anticipating how disruptions to one part of their
infrastructure will impact the rest
Deploying AI With an Event-Driven Platform
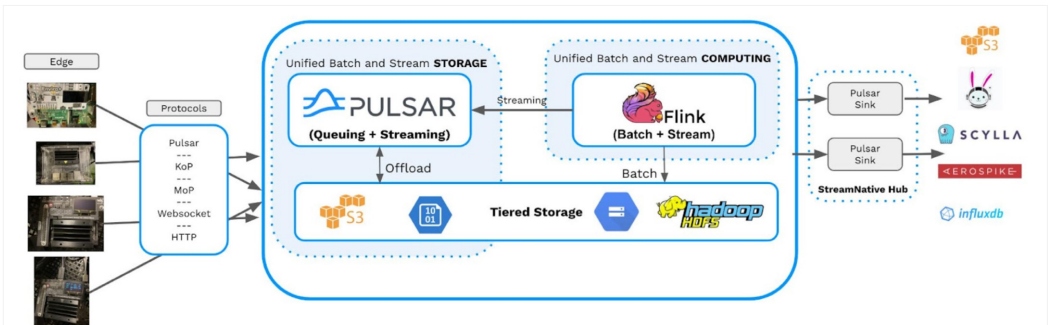
There are a number of crucial features required in an event-driven AI platform
to provide real-time access to models for all users. The platform needs to
offer self-service analytics to non-developers and citizen data scientists.
These users must be able to access all models and any data required for
training, context, or lookup. The platform also needs to support as many
different tools, technologies, notebooks, and systems as possible because
users need to access everything by as many channels and options as possible.
Further, almost all end users will require access to other types of data
(e.g., customer addresses, sales data, email addresses) to augment the results
of these AI model executions. Therefore, the platform should be able to join
our model classification data with live streams from different event-oriented
data sources, such as Twitter and Weather Feeds. This is why my first choice
for building an AI platform is to utilize a streaming platform such as Apache
Pulsar. Pulsar is an open-source distributed streaming and
publish/subscribe messaging platform that allows your machine learning
applications to interact with a multitude of application types
Quote for the day:
"As a leader, you set the tone for
your entire team. If you have a positive attitude, your team will achieve
much more." -- Colin Powell
No comments:
Post a Comment