How Radical API Design Changed the Way We Access Databases

One of the early design decisions we made at MongoDB was to focus on interaction
with the database using a pure object-based API. There would be no query
language. Instead, every request to the database would be described as a set of
objects that were intended to be constructed by a computer as much as by a human
(in many cases, more often by a computer). This approach allowed programmers to
treat a complex query the same as creating a piece of imperative code. Want to
retrieve all the animals in your database that have exactly two legs? Then
create an object, set a member, “legs,” to two and query the database for
matching objects. What you get back is an array of objects. This model extends
to even the most complex operations. This approach enabled developers to build
database queries as code — it was a leap from a query language mindset to a
programmer’s mindset. This would significantly speed up development time and
improve query performance. This API approach to database operations helped
kickstart MongoDB’s rapid adoption and growth in our early years.
Software Techniques for Lemmings

The performance of a system with thousands of threads will be far from
satisfying. Threads take time to create and schedule, and their stacks consume a
lot of memory unless their sizes are engineered, which won't be the case in a
system that spawns them mindlessly. We have a little job to do? Let's fork a
thread, call join, and let it do the work. This was popular enough before the
advent of <thread> in C++11, but <thread> did nothing to temper it.
I don't see <thread> as being useful for anything other than toy systems,
though it could be used as a base class to which many other capabilities would
then be added. Even apart from these Thread Per Whatever designs, some systems
overuse threads because it's their only encapsulation mechanism. They're not
very object-oriented and lack anything that resembles an application framework.
So each developer creates their own little world by writing a new thread to
perform a new function. The main reason for writing a new thread should be to
avoid complicating the thread loop of an existing thread.
Software development is changing again. These are the skills companies are looking for

The new normal means developers will work in a variety of ways with a broad
church of partners. As well as internal developers, Verastar uses outsourced
capability and works closely with some key digital transformation partners,
including Salesforce. "We have a very hybrid team. People need to learn to work
together and across different teams. We bring everything together with Agile and
sprints. Working in a virtual world means it's very rare you're all sat together
in the same office now," says Clarkson, "And that's certainly the case with us.
Although we've got a centre in Sale, Manchester, we've got developers that work
remote, our partner works remotely, and there'll be based either nearshore or
offshore as well, so you can end up with quite a wide team." Dal Virdi, IT
director at legal firm Shakespeare Martineau, is another tech chief who
recognises that a successful modern IT team relies on a hybrid blend of internal
developers and external specialists. Virdi recognised about 18 months ago that
his firm's ongoing digital transformation strategy, and the way in which the
business was introducing a broad range of technologies, meant they didn't need
to have internal specialists focused on one language or platform.
Concept drift vs data drift in machine learning

Concept and data drift are a response to statistical changes in the data.
Hence, approaches monitoring the model’s statistical properties, predictions,
and their correlation with other factors help identify the drift. But several
steps need to be taken post identification to ensure the model is accurate.
Two popular approaches are online machine learning and periodic retraininG.
Online learning involves updating the model to learn in real-time. This allows
the data to be sequential. This allows the models to take batches of samples
simultaneously and optimise the batch of data in one go. Online machine
learning allows us to update learners in real-time. In online learning the
models are learned in a setting where it takes the batches of samples with the
time and the learner optimises the batch of data in one go. Since these models
work on the fixed parameters of a data stream, they must retain the new
patterns of the data. Periodic retraining of the model is also critical. Since
an ML model degrades every three months on average, retraining them on regular
intervals can stop drift in its tracks.
The rise of zero-touch IT

First, zero-touch IT is a way to free your people from maintenance tasks, and
up-level your ops team to be more strategic. You’ve noticed the Great
Resignation — IT talent never grew on trees, and now there’s an epic drought.
Your team’s time and abilities shouldn’t be wasted on what can be automated.
Second, IT serves demanding customers. Corporate users have grown less tolerant
about waiting for IT to ride to their rescue, and they have sharper
expectations. After all, if they can find and load a CRM app on their phone in
one minute, why can’t your technology experts provide them with a new company
CRM in, say, 10 minutes? Users onboard, request privileges and carry out
operations in different time zones. Automation doesn’t sleep, making it a good
fit with asynchronous workforces. Third, zero-touch IT, when properly
implemented, reduces mistakes caused by fatigue and overload. One distracted IT
staffer can easily grant unauthorized data privileges to an outside contractor,
with dire consequences. There are options for zero-touch IT; independently
constructed workflows can be automated, but this can produce a spaghetti of
disparate procedures that behave differently and produce confusion.
Seeing the Unseen: A New Lens on Visibility at Work

In some sense, “seeing what you want to see” means seeing what you already
believe. That’s fine if you seek consensus, but it’s not a good formula for
innovative thinking. Pressure is necessary to effect real change. This often
involves challenging the status quo and stepping out of what has not been
recognized as a fixed perspective. Surrounding yourself with people with similar
experiences, beliefs, and perceptions about the world can foreclose on the
possibility of thinking differently. On teams, shared assumptions can result in
people coming up with the same or similar solutions to a set of challenges.
While these solutions may help people like you, they may fail to address the
needs of others who are not. Take, for example, the failure to optimize early
smartphone cameras for darker skin tones, or how facial recognition technologies
identify White faces with a higher degree of accuracy compared with those of
people of color. Technological biases of this kind ensure that some people are
seen, while others remain unseen or perhaps seen in a very unfavorable light.
Moore’s Law: Scientists Just Made a Graphene Transistor Gate the Width of an Atom
To be clear, the work is a proof of concept: The researchers haven’t
meaningfully scaled the approach. Fabricating a handful of transistors isn’t the
same as manufacturing billions on a chip and flawlessly making billions of those
chips for use in laptops and smartphones. Ren also points out that 2D materials,
like molybdenum disulfide, are still pricey and manufacturing high-quality stuff
at scale is a challenge. New technologies like gate-all-around silicon
transistors are more likely to make their way into your laptop or phone in the
next few years. Also, it’s worth noting that the upshot of Moore’s Law—that
computers will continue to get more powerful and cheaper at an exponential
rate—can also be driven by software tweaks or architecture changes, like using
the third dimension to stack components on top of one another. Still, the
research does explore and better define the outer reaches of miniaturization,
perhaps setting a lower bound that may not be broken for years. It also
demonstrates a clever way to exploit the most desirable properties of 2D
materials in chips.
New explanation emerges for robust superconductivity in three-layer graphene
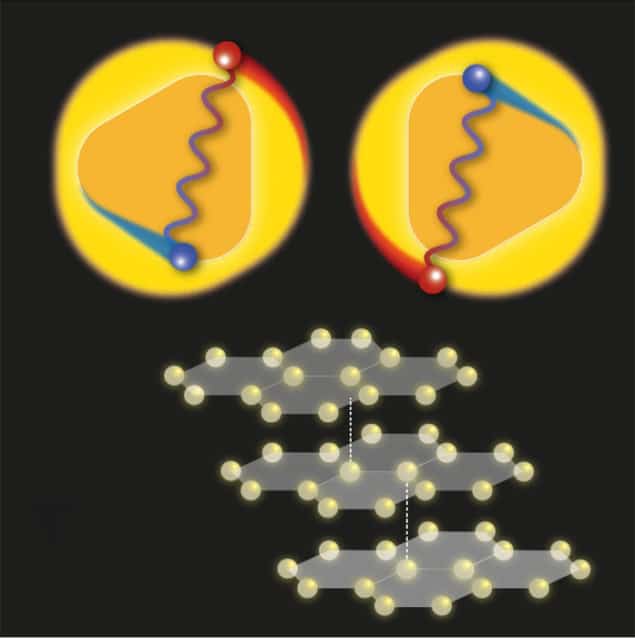
Graphene is an atomically-thin sheet of carbon atoms arranged in a 2D hexagonal
lattice. When two sheets of graphene are placed on top of each other and
slightly misaligned, the positions of the atoms form a moiré pattern or
“stretched” superlattice that dramatically changes the interactions between
their electrons. The degree of misalignment is very important: in 2018,
researchers at the Massachusetts Institute of Technology (MIT) discovered that
at a “magic” angle of 1.1°, the material switches from being an insulator to a
superconductor. The explanation for this is behaviour is that, as is the case
for conventional superconductors, electrons with opposite spins pair up to form
“Cooper pairs” that then move though the material without any resistance below a
certain critical transition temperature Tc (in this case, 1.7 K). Three years
later, the Harvard experimentalists observed something similar happening in
(rhombohedral) trilayer graphene, which they made by stacking three sheets of
the material at small twist angles with opposite signs. In their work, the twist
angle between the top and middle layer was 1.5° while that between the middle
and bottom layer was -1.5°.
Intelligent Diagramming Makes Sense of Cloud Complexities

One major issue IT leaders face is simply knowing what components their cloud
environments contain. At any point, a company can have SaaS apps, databases,
containers and workloads that sometimes spread across multiple cloud providers,
as well as on-premises systems. The first step in mitigating these cloud
complexities is to know what you have — in other words, to take inventory.
Depending on which cloud providers you use — Amazon Web Services (AWS),
Microsoft Azure or Google Cloud Platform (GCP) — you may need a variety of
inventory tools. Learn what your provider’s default management console offers.
In some cases, you may need to write scripts in order to pull data on every
resource type from every corner of your cloud environment (different regions,
for instance, might require separate queries). If your environment is complex
enough, management consoles and scripts won’t cut it. Automated inventory tools
can make it much easier to identify every component of your cloud environment.
But there are still opportunities to simplify how that inventory is pulled,
viewed and understood.
MLOps for Enterprise AI
There was a time when building machine learning (ML) models and taking them to
production was a challenge. There were challenges with sourcing and storing
quality data, unstable models, dependency on IT systems, finding the right
talent with a mix of Artificial Intelligence Markup Language (AIML) and IT
skills, and much more. However, times have changed. Though some of these issues
still exist, there has been an increase in the use of ML models amongst
enterprises. Organizations have started to see the benefits of ML models, and
they continue their investments to bridge the gap and grow the use of AIML.
Nevertheless, the growth of ML models in production leads to new challenges like
how to manage and maintain the ML assets and monitor the models. Since 2019,
there has been a surge in incorporating machine learning models into
organizations, and MLOps has started to emerge as a new trending keyword.
Although, it’s not just a trend; it’s a necessary element in the complete AIML
ecosystem.
Quote for the day:
"It's not about how smart you are--it's
about capturing minds." -- Richie Norton
No comments:
Post a Comment