
Once you know your team’s current skillsets, you are ready to identify the gaps
between the skills you have and the skills you need. This requires peering into
your crystal ball to anticipate the skills you will need to be future-ready. You
can do this by benchmarking your team’s skills against the skills hired by your
most innovative peers, gathering data on the skills that are growing fastest in
your industry, and assessing the capabilities you need to meet your business
goals. ... The last step is to determine whether it is more efficient to buy or
build the skills your team needs by comparing the effort each of these will
take. To assess the effort to buy a skill, consider how prevalent it is in the
market and whether it is likely to come with a salary premium. Is it a common
skill that many workers have, or is it still rare? Will requesting that skill
drive up the salary you must pay? The lower a skill’s supply and the higher its
salary premium, the greater your training ROI is likely to be if you can build
that skill internally. Even if the effort to build a skill is prohibitive, you
may still need to buy it, even if it is hard or expensive to find.
Cybersecurity burnout is real. And it's going to be a problem for all of us
Burnout threatens cybersecurity in multiple ways. First, on the employee side.
"Human error is one of the biggest causes of data breaches in organisations, and
the risk of causing a data breach or falling for a phishing attack is only
heightened when employees are stressed and burned out," says Josh Yavor, chief
information security officer (CISO) at enterprise security solutions provider
Tessian. A study conducted by Tessian and Stanford University in 2020 found that
88% of data breach incidents were caused by human error. Nearly half (47%) cited
distraction as the top reason for falling for a phishing scam, while 44% blamed
tiredness or stress. "Why? Because when people are stressed or burned out, their
cognitive load is overwhelmed and this makes spotting the signs of a phishing
attack so much more difficult," Yavor tells ZDNet. Threat actors are wise to
this fact, too: "Not only are they making spear-phishing campaigns more
sophisticated, but they are targeting recipients during the afternoon slump,
when people are most likely to be tired or distracted. Our data showed that most
phishing attacks are sent between 2pm and 6pm."
Master Data Management in Data Mesh
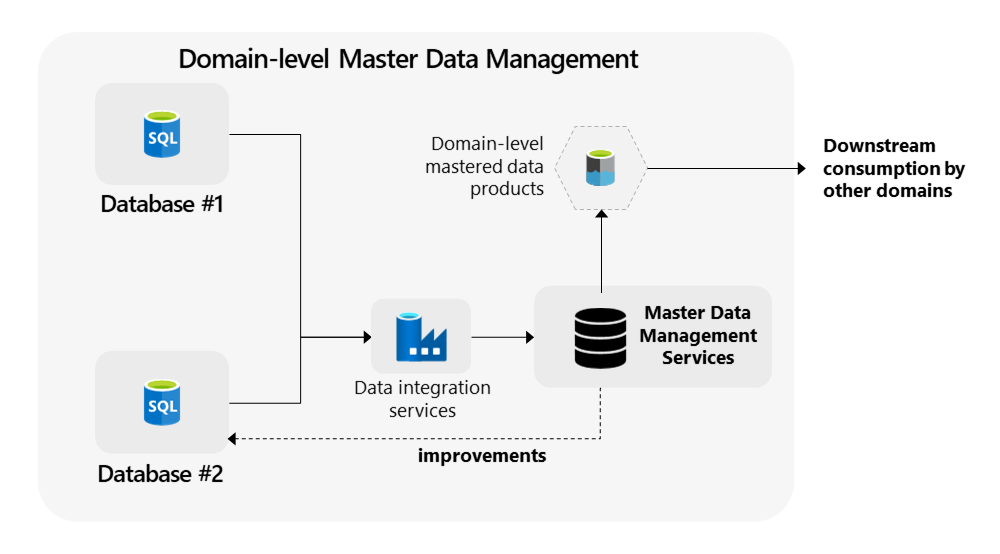
The importance of master data management is obvious: users can only make the
correct decisions if the data they use is consistent and correct. MDM ensures
consistency and quality on cross-domain level. Organizations need to find a
balance. Introducing too many areas of master data or reference values will
introduce too much cross-domain alignment. No enterprise data at all makes it
impossible to compare any results. A practical way to begin implementing MDM
into your organization is to start with the simplest way of master data
management: implementing a repository. With a repository you can quickly deliver
value by learning what data needs to be aligned or is of bad quality without
adjusting any of your domain systems. A next step will be setting clearer scope.
Don’t fall into the trap of enterprise data unification by selecting all data.
Start with subjects that add most value, such as customers, contracts,
organizational units, or products. Only select the most important fields to
master. The number of attributes should be in the tens, not the hundreds.
Why Mutability Is Essential for Real-Time Data Analytics
Data warehouses popularized immutability because it eased scalability,
especially in a distributed system. Analytical queries could be accelerated by
caching heavily-accessed read-only data in RAM or SSDs. If the cached data was
mutable and potentially changing, it would have to be continuously checked
against the original source to avoid becoming stale or erroneous. This would
have added to the operational complexity of the data warehouse; immutable data,
on the other hand, created no such headaches. Immutability also reduces the risk
of accidental data deletion, a significant benefit in certain use cases. Take
health care and patient health records. Something like a new medical
prescription would be added rather than written over existing or expired
prescriptions so that you always have a complete medical history. More recently,
companies tried to pair stream publishing systems such as Kafka and Kinesis with
immutable data warehouses for analytics. The event systems captured IoT and web
events and stored them as log files.
Mark Zuckerberg wants to build a voice assistant that blows Alexa and Siri away
:format(webp)/cdn.vox-cdn.com/uploads/chorus_image/image/70542866/metaverse_image_zuckerberg.0.png)
While Meta’s Big Tech competitors — Amazon, Apple, and Google — already have
popular voice assistant products, either on mobile or as standalone hardware
like Alexa, Meta doesn’t. “When we have glasses on our faces, that will be the
first time an AI system will be able to really see the world from our
perspective — see what we see, hear what we hear, and more,” said Zuckerberg.
“So the ability and expectation we have for AI systems will be much higher.” To
meet those expectations, the company says it’s been developing a project called
CAIRaoke, a self-learning AI neural model (that’s a statistical model based on
biological networks in the human brain) to power its voice assistant. This model
uses “self-supervised learning,” meaning that rather than being trained on large
datasets the way many other AI models are, the AI can essentially teach itself.
“Before, all the blocks were built separately, and then you sort of glued them
together,” Meta’s managing director of AI research, Joëlle Pineau, told Recode.
“As we move to self-supervised learning, we have the ability to learn the whole
conversation.”
Samsung Shattered Encryption on 100M Phones

Paul Ducklin, principal research scientist for Sophos, called out Samsung coders
for committing “a cardinal cryptographic sin.” Namely, “They used a proper
encryption algorithm (in this case, AES-GCM) improperly,” he explained to
Threatpost via email on Thursday. “Loosely speaking, AES-GCM needs a fresh burst
of securely chosen random data for every new encryption operation – that’s not
just a ‘nice-to-have’ feature, it’s an algorithmic requirement. In internet
standards language, it’s a MUST, not a SHOULD,” Ducklin emphasized. “That
fresh-every-time randomness (12 bytes’ worth at least for the AES-GCM cipher
mode) is known as a ‘nonce,’ short for Number Used Once – a jargon word that
cryptographic programmers should treat as an *command*, not merely as a noun.”
Unfortunately, Samsung’s supposedly secure cryptographic code didn’t enforce
that requirement, Ducklin explained. “Indeed, it allowed an app running outside
the secure encryption hardware component not only to influence the nonces used
inside it, but even to choose those nonces exactly, deliberately and
malevolently, repeating them as often as the app’s creator wanted.”
Big banks will blaze the enterprise GPT-3 AI trail
The use cases for GPT-3 in financial services are broad and already encompassed
in specific machine-learning packages. For instance, sentiment analysis (using
social media and articles to capture the temperature of the market), entity
recognition (classification of documents), and translation are all widely
available and used. Where GPT-3 will likely come into play for banks is in
language generation – the ability to handle claims and fill information into
forms, for example. This might be a small, consumer-focused start, but with
enough training data, GPT-3 could start taking an active role in risk management
and investment decisions. Getting a handle on the current return on RoI for this
tech in banking is difficult. These ML elements exist, but as data volumes grow,
the need for massive industry and even bank-specific trained models is clearer.
One big problem for financial institutions able to access the model (OpenAI is
less closed these days but GPT-3 is limited in terms of pre-training, downstream
task fine-tuning, plus no industry-specific corpus) is finding the people to
make it all work.
A New Dawn: Blockchain Tech Is Rising On The Auto Horizon

Given an accident between two vehicles, multiple pieces of information can be
easily shared and/or recorded for financial transactions including insurance
coverage, the costs of subsequent repairs or medical bills, the percent
culpability by both parties, etc. Over time, this creates a digital history of
a vehicle, which can be used to avoid deceit. “Fraud is big expense for
insurance carriers,” explains Shivani Govil, Chief Product Officer at CCC
Intelligent Solutions, “In the U.S. alone, fraud costs the insurance industry
over $40 billion annually. ... In the coming years, manufacturers,
governments, repair shops and suppliers will need to track cybersecurity
certifications based upon software versions of every part, especially since
soon some countries will requires proof of cybersecurity management systems
and software update capability. The vast Bill of Materials for a given vehicle
might include hundreds of parts with different versions software which may
have been replaced last week after an accident. Does the replacement part have
updated code?
Touchless tech: Why gesture-based computing could be the next big thing
This move towards new forms of interaction is a trend that resonates with Mia
Sorgi, director of digital product and experience at food and drink giant
PepsiCo Europe, whose company ran a gesture-based project recently that
allowed customers in a KFC restaurant to be served by moving their hands, with
no contact required. "I'm really proud of the work we did here," she says. "I
believe that gesture is a very important emerging interface option. I think it
is something that we will be doing more of in the future. I think it's really
valuable to get an understanding of how to win in that space, and how to
create something successful that people can use." While PepsiCo's
gesture-based project received fresh impetus during the pandemic, Sorgi
explains to ZDNet that the company has been experimenting with touchless
technology for the past three years. Those initial investigations into gesture
were scaled up and explored in a business environment last year.
What the retail sector can learn from supply chain disruption

Technology has undoubtably become influential in all aspects of our daily
lives and has hit every part of the retail ecosystem. The impacts of the
pandemic created a boom of online shoppers, who aren’t going away any time
soon. Consumers are now more inclined to search and buy products online, with
unlimited options as the tantalising grip – retailers though must endeavour to
continuously adapt to keep ever with ever evolving customer demands. This goes
for physical stores too, as customers that become more tech savvy increasingly
expect brick-and-mortar stores to keep up with exciting and new digital
innovations. An additional part of this retail ecosystem that can be
revolutionised by technology is the industry’s operations, which can and
should be stabilised and made more efficient. Whilst no retailer can predict
what will happen in the future, they can invest in technology that helps cope
with erratic seasonal or supply rise and falls and help prepare for whatever
lies ahead. Investing in software solutions that can help to stabilise
operations and prepare for unknown terrains is a good place to start.
Quote for the day:
"Confident and courageous leaders have
no problems pointing out their own weaknesses and ignorance." --
Thom S. Rainer
No comments:
Post a Comment