Robotic Process Automation: The Ultimate Way Forward for Smart Data Centers

As we enter this new shift in how companies work, each bit of data must be treated and properly used to maximize their value. This would not be possible without cost-effective storage and increasingly incredible hardware, digital transformation, and the associated new business models. For quite a while, experts have anticipated that the automation developments introduced in manufacturing plants worldwide will later be extended to data centers. In all realities, with the use of Robotic Process Automation (RPA) and machine learning in the data center setting, we are fast advancing this possibility. Human error is an essential explanation for network failure by a wide margin. Software defects and breakdowns lead this down. Despite almost zero knowledge of how the equipment operates, the step must be made after the downtime has just occurred. The cost effect is much higher as the emphasis is deviated from other issues to deal with the cause for the problem, along with the impact of the actual downtime of the network. To have an increasingly efficient data center, dependability, cost, and management have to be set. That can be supported by automation.
How The Remote Workforce Impacts GDPR & CCPA Compliance
So to achieve GDPR and CCPA compliance, organizations must ensure not only that explicit policies and procedures are in place for handling personal information, but also the ability to prove that those policies and procedures are being followed and operationally enforced. The new normal of remote workforces is a critical challenge that must be addressed. What has always been needed is gaining immediate visibility into unstructured distributed data across the enterprise, including on laptops and other unstructured data maintained by remote workforces, through the ability to search and report across several thousand endpoints and other unstructured data sources, and return results within minutes instead of days or weeks. The need for such an operational capability provided by best practices technology is further heightened by the urgency of CCPA and GDPR compliance. Solving this collection challenge is X1 Distributed Discovery, which is specially designed to address the challenges presented by remote and distributed workforces.
Thinking about Microservices
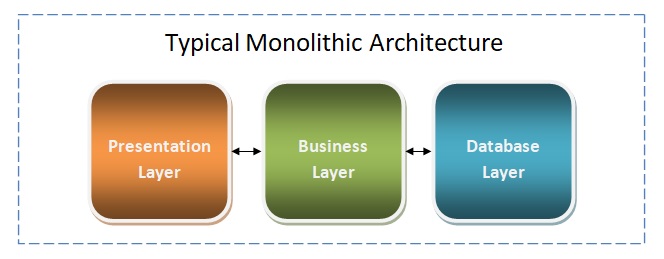
As the name implies, this architecture is based on services. This architecture is more than SOA architecture. Services are typically separated by either business capabilities or sub-domain. Once modules/components are defined, they can be implemented through a different set of teams. These teams would be the same or different technology stack teams. In this way, individual components can be scaled up when needed and quickly scaled down once the need is over. ... Now we talked about the benefits of Microservices, but it does not mean that every single application architecture should be drawn in Microservices. Before adopting Microservice architecture- ask yourself “Do you really need a Microservices based application?” Judge your decision by asking a simple set of questions before moving ahead with Microservices. ... Now you have a good overview of Microservice architecture, but having said that, practical implementation still has lot of differences compared to Monolithic. They are really not the same as traditional Monolithic architecture.
3 Keys to Efficient Enterprise Microservices Governance
An enterprise normally has a few thousand microservices, having autonomy for each team in selecting its own choice of the technology stack. Therefore, it’s inevitable that an enterprise should have a microservices governance mechanism to avoid building an unmanageable and unstable architecture. Any centralized governance goes against the core principle of microservices architectures i.e. “provide autonomy and agility to the team.” But that also doesn’t mean that we should not have a centralized policy, standards, and best practices that each team should follow. With an enterprise-scale of integrations with multiple systems and complex operations, the question is, “How do we effectively provide decentralized governance?” We need to have a paradigm shift in our thinking while implementing a microservices governance strategy. The governance strategy should align with core microservices principles – independent and self-contained services, single responsibility, and cross-functional teams aligning with the business as well as policies and best practices.
Artificial intelligence is evolving all by itself

Artificial intelligence (AI) is evolving—literally. Researchers have created software that borrows concepts from Darwinian evolution, including “survival of the fittest,” to build AI programs that improve generation after generation without human input. The program replicated decades of AI research in a matter of days, and its designers think that one day, it could discover new approaches to AI. “While most people were taking baby steps, they took a giant leap into the unknown,” says Risto Miikkulainen, a computer scientist at the University of Texas, Austin, who was not involved with the work. “This is one of those papers that could launch a lot of future research.” Building an AI algorithm takes time. Take neural networks, a common type of machine learning used for translating languages and driving cars. These networks loosely mimic the structure of the brain and learn from training data by altering the strength of connections between artificial neurons. Smaller subcircuits of neurons carry out specific tasks—for instance spotting road signs—and researchers can spend months working out how to connect them so they work together seamlessly.
HowTo Secure Distributed Cloud Systems in Enterprise Environments
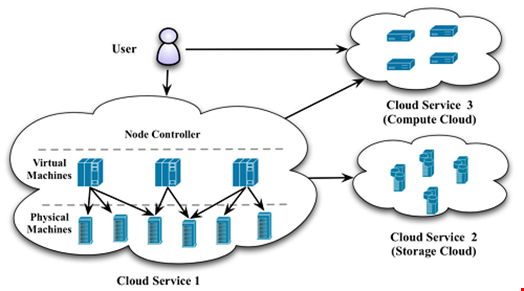
Rapidly increasing workloads call for improved IT infrastructure scaling in businesses. Cloud resources are designed to be scalable by changing several lines of code and increasing spending. This ease of scaling, however, can lull organizations into scaling too much without considering the side effects. Scaling cloud resources would require an equal expansion in security systems. If an enterprise’s security measures cannot keep up with the rate at which its cloud environment is growing, it’s only going to increase the attack surface for costly breaches. To avoid this problem, enterprises should consider the scalability of their security systems first before expanding cloud environments. Security applications should also be integrated into the environment, not as a separate or external resource, to maintain business continuity. Automation is a must for good distributed cloud management. Again, an increased number of applications and dependencies make it almost impossible for it to be done efficiently by hand. The time saved from automation can then be funneled towards higher-level, strategic work.
3 Steps for Deploying Robotic Process Automation

The first step to adopting RPA is discerning which processes in your organization can, and should, be automated. Look at which tasks require critical thinking, emotional intelligence and add the most value to your customer. Then, automate tasks that are manual, repetitive and prone to error. For example, you could automate processes like collecting data, monitoring and prioritizing emails and filling out forms, which are tedious tasks that would otherwise take hours of your employees’ time. We thought critically about how to use RPA to better support our people -- allowing them to dedicate more time advising customers, while bots pulled the information needed to assist in that counsel. ... To note, deploying RPA is not a one-and-done initiative. Adopting RPA is a dynamic process that you need to continually update to support your company’s unique and growing business needs. We deployed a timeboxed approach over the course of 20 weeks. Rather than attempt to deploy as many bots as possible, we first established a sound foundation for RPA within our operations from which we could scale in automated measures.
OpenTelemetry Steps up to Manage the Mayhem of Microservices

The goal with OpenTelemetry is not to provide a platform for observability, but rather to provide a standard substrate to collect and convey operational data so it can be used in monitoring and observational platforms, either of the open source or commercial variety. Historically, when an enterprise would purchase a package for systems monitoring, all the agents that would be attached to the resources would be specific to that provider’s implementation. If a customer wanted to change out, the applications and infrastructure would have to be entirely re-instrumented, Sigelman explained. By using the OpenTelemetry, users could instrument their systems once and pick the best and visualization and analysis products for their workloads, and not worry about lock-in. In addition to Honeycomb and Lightstep, some of the largest vendors in the monitoring field, as well as the largest end-users are participating, including Google, Microsoft, Splunk, Postmates, and Uber. The new collector is crucial, explained Honeycomb’s Fong-Jones, in that it narrows the minimum scope of what vendors must support in order to ingest telemetry.
Steps to Implementing Voice Authentication and Securing Biometric Data

Fraud prevention is a key driver for implementation and companies are looking both internally as well as externally. Insider threats can be reduced as staff access privileges are tightened up alongside voice biometric introduction. What are the steps to implementing a voice verification system, and how should the voiceprint data be secured, while ensuring compliance? Before implementing, the current system of authentication needs to be analyzed and compared to the desired process. Companies need to answer a number of questions. What is the current authentication process? For example passwords, PINs, set questions. How will this process change by using voice biometrics? Will Voice biometry replace OR extend current authentication steps? This depends on the geography. EU regulations such as PSD2 require strong authentication such as a biometric factor and something in your possession, such as an app. It also depends on their motivation. Some banks want voice biometrics to help with compliance, some want it to slash verification time – for example, if a bank currently asks five questions, they can safely cut it down to only one.
Working With Data in Microservices
A computer program is a set of instructions for manipulating data. Data will be stored (and transferred) in a machine-readable structured way that is easy to process by programs. Every year there are programming languages, frameworks, and technologies that emerge to optimize data processing in computer programs. Without the proper support from languages or frameworks, the developer won’t be able to write their programs in a way that’s easy to process and get meaningful information out of the data. Languages such as Python and R have adapted to specialize in data processing jobs and Matlab and Octave specialize in complex numbers for numerical computing processing. However, for microservice development where the programs are network distributed, traditional languages are yet to specialize for their unique needs. Ballerina is a new open-source programming language, which provides a unique developer experience to working with data in network-distributed programs.
Quote for the day:
"Leadership is getting someone to do what they don't want to do, to achieve what they want to achieve." -- Tom Landry
No comments:
Post a Comment