Weekly health check of ISPs, cloud providers and conferencing services
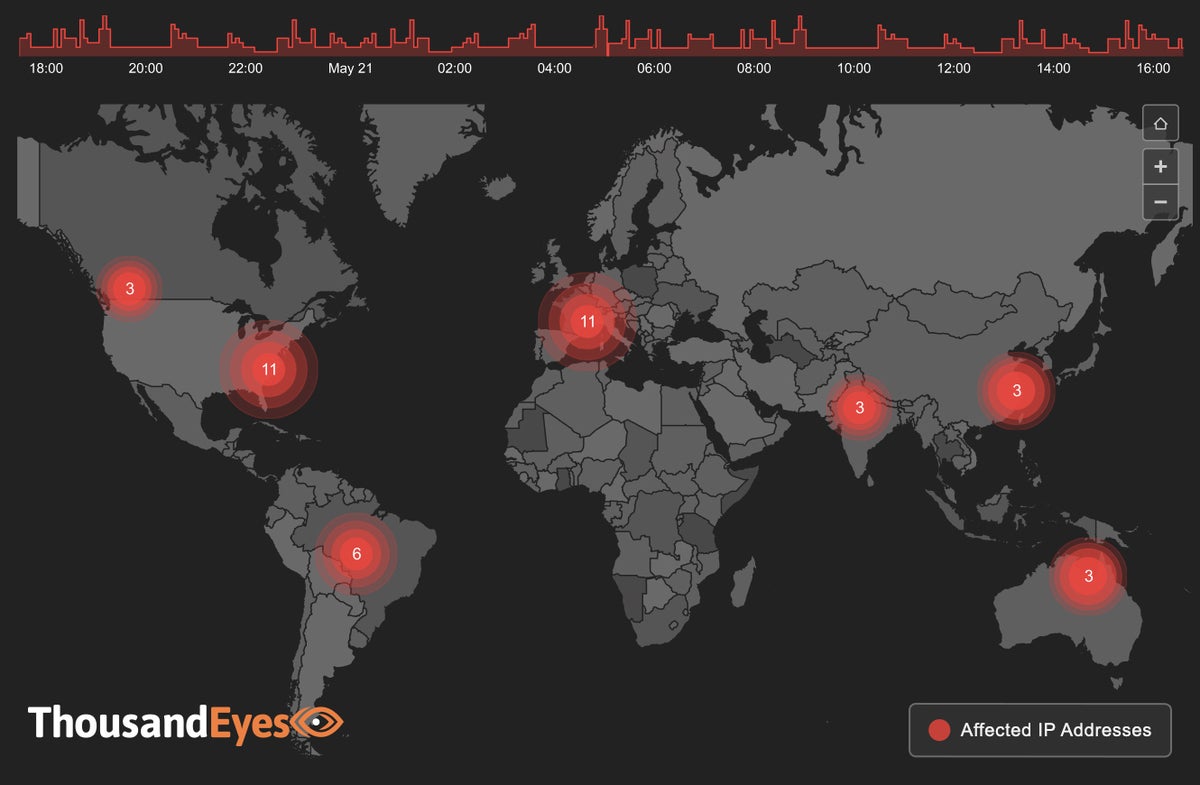
Outages for ISPs globally were down 9.13% during the week of March 30 from the week before, whereas U.S. outages were down 16.7%, dropping from 120 to 100. Worldwide the outages were also down, from 252 to 229. Public cloud outages rose worldwide from 22 to 25, and in the U.S. there was one outage, up from zero the previous week. Outages for collaboration apps rose dramatically, increasing more than 260% globally and more than 500% in the U.S. over the week before. The actual numbers were an increase from eight to 29 worldwide, and up from 4 to 25 in the U.S. ... During the week April 6-Apri 12, service outages for ISPs, cloud providers, and conferencing services dropped overall. They went from 298 down to 177 globally (40%, a six-week low), and in the U.S. dropped from 129 to 72 (44%). Globally, ISP outages were down from 229 to 141 (38%), and in the U.S. were down from 100 to 56 (44%). Cloud provider outages were also down overall from 25 to 19 (24%), ThousandEyes says, but jumped up from one to six (500%) in the U.S., which saw the highest rate of increase in seven weeks. Even so, the U.S. total was relatively low. “Again, cloud providers are doing quite well,” ThousandEyes says.
A Smattering of Thoughts About Applying Site Reliability Engineering principles
Google has a lot more detail on the principles of “on-call” rotation work compared to project-oriented work. Life of An On-Call Engineer. Of particular relevance is mention of capping the time that Site Reliability Engineers spend on purely operational work to 50% to ensure the other time is spent building solutions to impact the automation and service reliability in a proactive, rather than reactive manner. In addition, the challenges of operational reactive work and getting in the zone on solving project work with code can limit the ability to address the toil of continual fixes. Google's SRE Handbook also addresses this in mentioning that you should definitely not mix operational work and project work on the same person at the same time. Instead whoever is on call for that reactive work should focus fully on that, and not try to do project work at the same time. Trying to do both results in frustration and fragmentation in their effort. This is refreshing, as I known I've felt the pressure of needing to deliver a project, yet feeling that pressure of reactive work with operational issues taking precedence.
Coronavirus: Zoom user credentials for sale on dark web

Analysis of the database found that alongside personal accounts belonging to consumers, there were also corporate accounts registered to banks, consultancies, schools and colleges, hospitals, and software companies, among many others. IntSights said that whilst some of these accounts only included an email and password, others included Zoom meeting IDs, names and host keys. “The more specific and targeted the databases, the more it's going to cost you. A database of random usernames and passwords is probably going to go pretty cheap because it's harder to utilise,” Maor told Computer Weekly. “But if somebody says they have a database of Zoom users in the UK the price is going to get much higher because it's much more specific and much easier to use.” Whilst it is not uncommon at all for usernames and passwords to be shared or sold, Maor said that some of the discussions that followed had been intriguing, with the sale spawning a number of different posts and threads discussing different approaches to targeting Zoom users, many of them focused on credential stuffing attacks.
Remote work will be forever changed post-COVID-19
The problem with these two competing visions is that they assume we'll return to an extreme version of a pre-COVID-19 scenario, either doubling down on traditional remote working arrangements, or spending even more time traveling and sitting in offices, working the way we always did before the virus. I believe that the key lessons many of us will take from this period of enforced remote work are less about location, and more about time and work management. One thing I noticed and confirmed with several colleagues early in my COVID-19 experience was that productive video conferences were mentally more exhausting than an equivalent in-person meeting. A two-hour workshop over videoconference had the same mental drain as an all-day affair in an in-person meeting, especially for the presenters and facilitators. The medium seems to force more intense interactions, and more planning to successfully orchestrate. Collaborating in the same physical space was the pre-COVID-19 norm since it was easy.
Comparing Three Approaches to Multi-Cloud Security Management

IaC is a second approach to multi-cloud management. This approach arose in response to utility computing and second-generation web frameworks, which gave rise to widespread scaling problems for small businesses. Administrators took a pragmatic approach: they modeled their multi-cloud infrastructures with code, and were therefore able to write management tools that operated in a similar way to standard software. IaC sits in between the other approaches on this list, and represents a compromise solution. It gives more fine-grained control over cloud management and security processes than a CMP, especially when used in conjunction with SaaS security vendors whose software can apply a consistent security layer to a software model of your cloud infrastructure. This is important because SaaS is growing rapidly in popularity, with 86% of organizations expected to have SaaS meeting the vast majority of their software needs within two years. On the other hand, IaC requires a greater level of knowledge and vigilance than either CMP—or cloud-native approaches.
DevOps implementation is often unsuccessful. Here's why
The primary feature of DevOps is, to a certain extent, the automation of the software development process. Continuous integration and continuous delivery (CI/CD) principles are the cornerstones of this concept, and as you likely know, are very reliant on tools. Tools are awesome, they really are. They can bring unprecedented speed to the software delivery process, managing the code repository, testing, maintenance, and storage elements with relatively seamless ease. And if you’re managing a team of developers in a DevOps process, these tools and the people who use them are a vital piece of the puzzle in shipping quality software. However, while robots might take all our jobs and imprison us someday, they are definitely not there yet. Heavy reliance on tools and automation leaves a window wide open for errors. Scans and tests may not pick up everything, code may go unchecked, and that presents enormous quality (not to mention, security) issues down the track. An attacker only needs one back door to exploit to steal data, and forgoing the human element in quality and security control can have disastrous consequences.
Videoconferencing quick fixes need a rethink when the pandemic abates

A tier down from its immersive telepresence big brother is the multipurpose conference room. Inside offices, companies have designated multipurpose rooms, equipped more minimally with videoconferencing equipment. Instead of spending big bucks on devoting an entire room, with all of the bells and whistles, to an immersive telepresence system, why not outfit a conference room with enough cameras, screens and microphones to offer a good virtual meeting experience, while still leaving the room to be used for general meetings? These multipurpose rooms generally cost a few thousand dollars to outfit with a camera, a microphone array and maybe some integrated digital whiteboards, and a PC or iPad as a control mechanism, Kerravala says. It's a lot more affordable, but a multipurpose conference room still is bandwidth intensive. And it's likely to be tapping bandwidth on the shared network – instead of having its own pipe, as an immersive room would – and that needs to be taken into consideration in network capacity planning.
Information Age roundtable: Harnessing the power of data in the utilities sector
When it comes to data usage across the company, a major aspect to be considered is the trust that is placed in employees. For Graeme Wright, chief digital officer, manufacturing, utilities and services at Fujitsu UK, “data is only trusted with certain people. “Sometimes, it goes across organisational boundaries, because of the third-party suppliers that people are using, and I don’t know if people have really been really incentivised to exploit the value of that data.” Wright went on to explain that the field force “need a different method of interacting to make sure that the data flows freely from them into the actual centre so we can actually analyse it and understand what’s going on”. Steven Steer, head of data at Ofgem, also weighed in on this issue: “This is really central to the energy sector’s agenda over the last year or so. The Energy Data Task Force, an independent task force, published its findings in June, and one of the main findings was the presumption that data is open to all, not just within your own organisation.

At first glance, low-code and cloud-native don’t seem to have much to do with each other — but many of the low-code vendors are still making the connection. After all, microservices are chunks of software code, right? So why hand-code them if you could take a low-code approach to craft your microservices? Not so fast. Microservices generally focus on back-end functionality that simply doesn’t lend itself to the visual modeling context that low-code provides. Furthermore, today’s low-code tools tend to center on front-end application creation (often for mobile apps), as well as business process workflow design and automation. Bespoke microservices are unlikely to be on this list of low-code sweet spots. It's clear from the definition of microservices above that they are code-centric and thus might not lend themselves to low-code development. However, how organizations assemble microservices into applications is a different story. Some low-code vendors would have you believe that you can think of microservices as LEGO blocks that you can assemble into applications. Superficially, this LEGO metaphor is on the right track – but the devil is in the details.
Graph Knowledge Base for Stateful Cloud-Native Applications
As a rule, stateless applications do not persist any client application state between requests or events. “Statelessness” decouples cloud-native services from client applications to achieve desired isolation. The tenets of microservice and serverless architecture expressly prohibit retention of session-state or global-context. However, while the state doesn’t reside in the container, it still has to live somewhere. After all, a stateless function takes state as inputs. Application state didn’t go away, it moved. The trade-off is that state, and with it any global-context, must be re-loaded with every execution. The practical consequence of statelessness is a spike in network usage, which results in chatty, bandwidth and I/O intensive, inter-process communications. This comes at a price – in terms of both increased Cloud service expenditures, as well as latency and performance impacts on Client applications. Distributed computing had already weakened the bonds of data-gravity as a long-standing design principle, forcing applications to integrate with an ever-increasing number of external data sources. Cloud-native architecture flips-the-script completely - data ships to functions.
Quote for the day:
"Leaders must be good listeners. It's rule number one, and it's the most powerful thing they can do to build trusted relationships." -- Lee Ellis
No comments:
Post a Comment