Quote for the day:
"Goals are for people who care about winning once. Systems are for people who care about winning repeatedly." -- James Clear
🎧 Listen to this digest on YouTube Music
▶ Play Audio DigestDuration: 21 mins • Perfect for listening on the go.
Digital devolution and taking back control
 The article discusses the shift from highly centralized technology management
to a model of digital devolution, where local organizations regain control
over their systems and data. For many years, massive top down technology
contracts locked public sector and enterprise groups into rigid, monolithic
platforms that often failed to address specific local needs. Now, there is a
growing movement to push decision making, budget, and technical authority away
from the center and back into the hands of the people actually delivering
frontline services. By taking back this control, local departments can choose
modern, flexible tools that solve their unique operational problems. However,
this decentralized approach does not mean a return to isolated silos. Instead,
it relies heavily on open standards, shared data registries, and common
technical platforms to ensure that different local systems can still talk to
one another smoothly. This transition requires a careful balance between
giving local leaders the freedom to innovate and maintaining enough central
coordination to prevent any overlapping financial costs and security risks.
Ultimately, giving power back to local teams enables much faster responses to
user needs, reduces reliance on expensive older legacy vendors, and builds a
more resilient technology landscape across the entire broader organization.
The article discusses the shift from highly centralized technology management
to a model of digital devolution, where local organizations regain control
over their systems and data. For many years, massive top down technology
contracts locked public sector and enterprise groups into rigid, monolithic
platforms that often failed to address specific local needs. Now, there is a
growing movement to push decision making, budget, and technical authority away
from the center and back into the hands of the people actually delivering
frontline services. By taking back this control, local departments can choose
modern, flexible tools that solve their unique operational problems. However,
this decentralized approach does not mean a return to isolated silos. Instead,
it relies heavily on open standards, shared data registries, and common
technical platforms to ensure that different local systems can still talk to
one another smoothly. This transition requires a careful balance between
giving local leaders the freedom to innovate and maintaining enough central
coordination to prevent any overlapping financial costs and security risks.
Ultimately, giving power back to local teams enables much faster responses to
user needs, reduces reliance on expensive older legacy vendors, and builds a
more resilient technology landscape across the entire broader organization.Mastering NHS Risk Management: A Guide to Best Practice
 The article outlines how NHS boards can transition from treating risk
management as a passive compliance exercise to using it as an active tool for
institutional assurance. Often, executive teams rely on massive risk registers
that blur the line between critical threats and minor operational friction.
Instead, boards need a unified framework that actively drives real-world
decision-making. A central theme is the need to break down silos between
clinical care, financial stability, and digital security, treating them as an
interconnected triad. A failure in finances or data security inevitably
compromises patient safety. For example, with over 260,000 cyber attacks
recorded in early 2026 and the increasing use of artificial intelligence,
digital risk is now a direct threat to clinical outcomes. To build true
resilience, the article advises leaders to use their Board Assurance Framework
not just to record problems, but to demonstrate clear, evidenced progress
toward long-term strategic goals, such as those in the 10-Year Health Plan.
Ultimately, effective governance requires boards to replace bureaucratic
rituals with practical judgment and institutional memory, ensuring that every
identified risk leads to a deliberate action to either mitigate a threat or
enable an opportunity for better healthcare delivery.
The article outlines how NHS boards can transition from treating risk
management as a passive compliance exercise to using it as an active tool for
institutional assurance. Often, executive teams rely on massive risk registers
that blur the line between critical threats and minor operational friction.
Instead, boards need a unified framework that actively drives real-world
decision-making. A central theme is the need to break down silos between
clinical care, financial stability, and digital security, treating them as an
interconnected triad. A failure in finances or data security inevitably
compromises patient safety. For example, with over 260,000 cyber attacks
recorded in early 2026 and the increasing use of artificial intelligence,
digital risk is now a direct threat to clinical outcomes. To build true
resilience, the article advises leaders to use their Board Assurance Framework
not just to record problems, but to demonstrate clear, evidenced progress
toward long-term strategic goals, such as those in the 10-Year Health Plan.
Ultimately, effective governance requires boards to replace bureaucratic
rituals with practical judgment and institutional memory, ensuring that every
identified risk leads to a deliberate action to either mitigate a threat or
enable an opportunity for better healthcare delivery.
Routine maintenance as a failure vector in modern networks
 In today's highly interconnected technology environments, "routine" network
maintenance is no longer a low-risk activity. While planned updates, such as
firewall adjustments, DNS modifications, or certificate renewals, are meant to
improve system reliability, they often trigger unexpected outages. This
happens because modern networks are incredibly complex, and a single user
transaction now crosses multiple layers, including load balancers, security
policies, and routing protocols. Consequently, a change to just one device can
easily break a hidden dependency elsewhere in the traffic path. The core issue
is that teams typically test only the specific component they changed, rather
than verifying the complete traffic flow. Preliminary checks and isolated test
environments are helpful, but they rarely mirror the true conditions of a live
network. To prevent these maintenance induced failures, professionals need to
map out traffic paths completely before making any changes. They should also
establish clear expectations for how systems will react and prepare precise
rollback plans that go beyond simply reverting a configuration. Ultimately,
organizations must stop viewing maintenance as a simple checklist of isolated
device updates. Instead, every maintenance window should be treated as a
practical exercise in network resilience, requiring collaboration across
security, application, and operations teams to ensure continuous service.
In today's highly interconnected technology environments, "routine" network
maintenance is no longer a low-risk activity. While planned updates, such as
firewall adjustments, DNS modifications, or certificate renewals, are meant to
improve system reliability, they often trigger unexpected outages. This
happens because modern networks are incredibly complex, and a single user
transaction now crosses multiple layers, including load balancers, security
policies, and routing protocols. Consequently, a change to just one device can
easily break a hidden dependency elsewhere in the traffic path. The core issue
is that teams typically test only the specific component they changed, rather
than verifying the complete traffic flow. Preliminary checks and isolated test
environments are helpful, but they rarely mirror the true conditions of a live
network. To prevent these maintenance induced failures, professionals need to
map out traffic paths completely before making any changes. They should also
establish clear expectations for how systems will react and prepare precise
rollback plans that go beyond simply reverting a configuration. Ultimately,
organizations must stop viewing maintenance as a simple checklist of isolated
device updates. Instead, every maintenance window should be treated as a
practical exercise in network resilience, requiring collaboration across
security, application, and operations teams to ensure continuous service.
Hacker Conversations: Jesse McGraw (GhostExodus), From Blackhat Hacker to Redemption
Jesse McGraw, formerly known as the malicious computer hacker GhostExodus, underwent a profound transformation from a cybercriminal to a dedicated cybersecurity advocate. His journey began in high school, where a profound sense of isolation and neurodivergence fueled his obsession with technology. He discovered a talent for breaking rules and bypassing systems, driven primarily by the thrill of unauthorized access rather than financial gain. Lacking a clear moral compass regarding digital boundaries, his exploits steadily escalated. This culminated in his leadership of a hacker group and a dangerous breach of a Dallas medical facility network. After he recklessly posted a video of the hack online, a security researcher used open source intelligence to identify him, leading to McGraw's arrest and an eleven year prison sentence. This lengthy incarceration forced a pivotal realization about the real world consequences of his actions and the severe impact on victims. Today, McGraw channels his skills toward positive outcomes. Instead of breaking into networks, he utilizes open source intelligence to identify online predators and protect children. Acting as a bridge between the underground hacker community and the legitimate security industry, he educates the public on safe computing practices and works to prevent attacks on critical infrastructure.Turning the Tables on Email Scammers With 'ScamBuster'
Is that QR code a trap? How to spot quishing scams before it's too late
 Quishing, or QR code phishing, is a growing modern scam where attackers trick
people into scanning malicious QR codes. These specific codes usually lead to
fraudulent websites designed to steal sensitive information like passwords,
credit card numbers, or personal data. Scammers often place fake QR codes over
legitimate ones on parking meters, restaurant menus, or public transit
stations. They also send them through emails or physical mail, pretending to
be from trusted sources like banks or delivery services. To protect yourself,
treat QR codes with the same caution as email links. Before scanning,
physically inspect the code; if it is printed on a sticker placed over another
code, avoid it. Use your phone's built-in camera app rather than a third-party
QR scanner, as native cameras usually display the destination URL before
opening it. Review the URL carefully for subtle misspellings or odd domain
names that mimic real brands. If a scanned code asks for login credentials or
payment information, stop and navigate to the official website manually
instead. Finally, keep your smartphone's operating system updated, as this
ensures you have the latest built-in security features. By staying observant
and verifying links, you can easily avoid these deceptive QR code scams.
Quishing, or QR code phishing, is a growing modern scam where attackers trick
people into scanning malicious QR codes. These specific codes usually lead to
fraudulent websites designed to steal sensitive information like passwords,
credit card numbers, or personal data. Scammers often place fake QR codes over
legitimate ones on parking meters, restaurant menus, or public transit
stations. They also send them through emails or physical mail, pretending to
be from trusted sources like banks or delivery services. To protect yourself,
treat QR codes with the same caution as email links. Before scanning,
physically inspect the code; if it is printed on a sticker placed over another
code, avoid it. Use your phone's built-in camera app rather than a third-party
QR scanner, as native cameras usually display the destination URL before
opening it. Review the URL carefully for subtle misspellings or odd domain
names that mimic real brands. If a scanned code asks for login credentials or
payment information, stop and navigate to the official website manually
instead. Finally, keep your smartphone's operating system updated, as this
ensures you have the latest built-in security features. By staying observant
and verifying links, you can easily avoid these deceptive QR code scams.
Your AI risk register is not an incident response plan
 Many organizations mistakenly treat a list of potential AI risks as an actual
plan for managing failures. While documenting risks creates helpful
visibility, a spreadsheet cannot investigate, contain, or resolve a problem
when an artificial intelligence system breaks down in a live environment. To
properly manage these systems, security teams need a practical response plan
that dictates exactly what to do when an issue occurs. Unlike traditional
security breaches involving unauthorized access or stolen data, AI failures
are often messier. They might look like a misleading summary, a flawed
recommendation, or a bad automated decision. Because of this, organizations
must define what counts as an AI incident and establish clear ways for
employees to report these events. Additionally, investigating these issues
requires evidence. Organizations must ensure that logs, prompt histories, and
system outputs are captured before moving AI tools into active use. Most
importantly, clear ownership is essential. Someone must have the explicit
authority to pause or restrict an AI system if it starts producing harmful or
unreliable results. Ultimately, security leaders must bridge the gap between
acknowledging potential problems and being operationally prepared to fix them
by creating a clear, realistic response playbook for their organizations to
follow.
Many organizations mistakenly treat a list of potential AI risks as an actual
plan for managing failures. While documenting risks creates helpful
visibility, a spreadsheet cannot investigate, contain, or resolve a problem
when an artificial intelligence system breaks down in a live environment. To
properly manage these systems, security teams need a practical response plan
that dictates exactly what to do when an issue occurs. Unlike traditional
security breaches involving unauthorized access or stolen data, AI failures
are often messier. They might look like a misleading summary, a flawed
recommendation, or a bad automated decision. Because of this, organizations
must define what counts as an AI incident and establish clear ways for
employees to report these events. Additionally, investigating these issues
requires evidence. Organizations must ensure that logs, prompt histories, and
system outputs are captured before moving AI tools into active use. Most
importantly, clear ownership is essential. Someone must have the explicit
authority to pause or restrict an AI system if it starts producing harmful or
unreliable results. Ultimately, security leaders must bridge the gap between
acknowledging potential problems and being operationally prepared to fix them
by creating a clear, realistic response playbook for their organizations to
follow.
Building AI Agents? Here Are Some Anti-Patterns to Avoid.
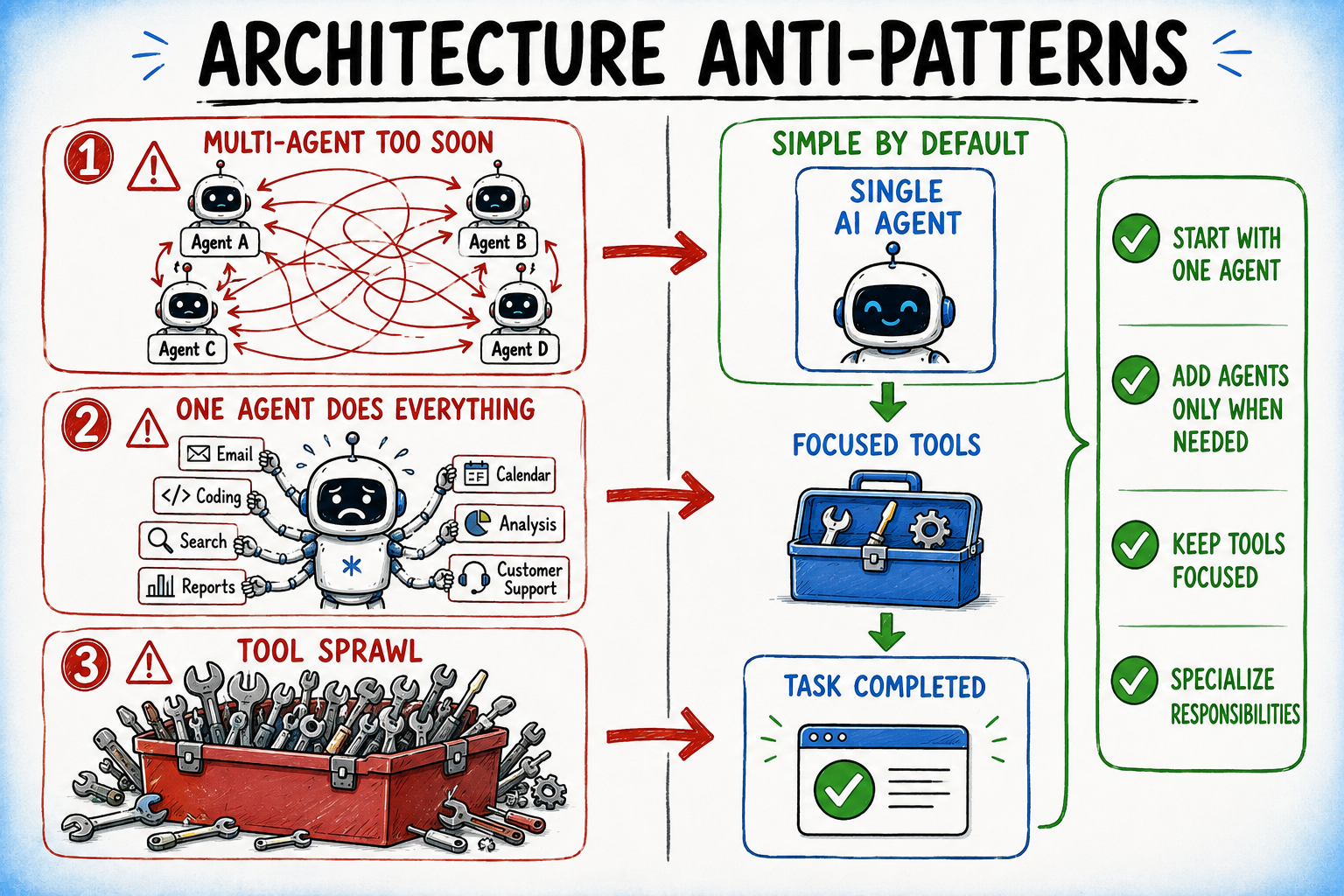 When building artificial intelligence agents, projects often fail not because
of the underlying models, but due to preventable structural and operational
mistakes. To build reliable systems, it is essential to start simple and scale
complexity only when necessary. A common error is adopting a complex,
multi-agent setup early when a single, well-scoped agent with clear
responsibilities would suffice. Similarly, overloading an agent with too many
tools or expecting it to handle every possible task makes it inefficient and
prone to errors. Instead, provide a minimal set of distinct tools and focus on
specialized tasks. Another key issue is hardcoding rigid logic rather than
building modular components that are easy to update. Furthermore, a solid
memory design is vital; agents need to recall past steps to navigate complex
tasks effectively. On the operational side, releasing agents without clear
visibility into their decision-making processes makes fixing problems
incredibly frustrating. It is also crucial to limit their ability to make
permanent changes without human oversight, carefully manage the information
they process over long tasks to avoid confusion, and rigorously test them
against unexpected scenarios before launch. By addressing these pitfalls, you
can create practical tools that consistently deliver the desired results in
everyday applications.
When building artificial intelligence agents, projects often fail not because
of the underlying models, but due to preventable structural and operational
mistakes. To build reliable systems, it is essential to start simple and scale
complexity only when necessary. A common error is adopting a complex,
multi-agent setup early when a single, well-scoped agent with clear
responsibilities would suffice. Similarly, overloading an agent with too many
tools or expecting it to handle every possible task makes it inefficient and
prone to errors. Instead, provide a minimal set of distinct tools and focus on
specialized tasks. Another key issue is hardcoding rigid logic rather than
building modular components that are easy to update. Furthermore, a solid
memory design is vital; agents need to recall past steps to navigate complex
tasks effectively. On the operational side, releasing agents without clear
visibility into their decision-making processes makes fixing problems
incredibly frustrating. It is also crucial to limit their ability to make
permanent changes without human oversight, carefully manage the information
they process over long tasks to avoid confusion, and rigorously test them
against unexpected scenarios before launch. By addressing these pitfalls, you
can create practical tools that consistently deliver the desired results in
everyday applications.
CIOs must rethink operating models to unlock AI at scale
 Many organizations face immense pressure to implement AI at scale, but their
current operational foundations often aren't ready. While AI technology is
advancing rapidly, businesses are struggling with a "readiness gap" caused by
issues like data quality, disjointed operating models, and a lack of proper
skills and governance. CIOs must rethink their operating models to close this
gap. This requires moving away from traditional, siloed technology playbooks
toward a tighter partnership between IT and business teams. AI thrives on
clarity, and organizations need to redesign their end-to-end workflows rather
than just bolting AI onto existing processes. Data readiness is a critical
first step; companies must focus on improving data quality, standardizing
procedures, and managing the new information generated by AI tools.
Furthermore, successful AI scaling requires executive sponsorship, clear
communication to address employee fears, and governance that is embedded
directly into the operating model rather than treated as an afterthought.
Transitioning from small proofs of concept to full production demands a
strategic shift in how teams work together. Ultimately, unlocking AI's
potential is a team effort that relies on intentional design, continuous
upskilling, and a strong, integrated foundation.
Many organizations face immense pressure to implement AI at scale, but their
current operational foundations often aren't ready. While AI technology is
advancing rapidly, businesses are struggling with a "readiness gap" caused by
issues like data quality, disjointed operating models, and a lack of proper
skills and governance. CIOs must rethink their operating models to close this
gap. This requires moving away from traditional, siloed technology playbooks
toward a tighter partnership between IT and business teams. AI thrives on
clarity, and organizations need to redesign their end-to-end workflows rather
than just bolting AI onto existing processes. Data readiness is a critical
first step; companies must focus on improving data quality, standardizing
procedures, and managing the new information generated by AI tools.
Furthermore, successful AI scaling requires executive sponsorship, clear
communication to address employee fears, and governance that is embedded
directly into the operating model rather than treated as an afterthought.
Transitioning from small proofs of concept to full production demands a
strategic shift in how teams work together. Ultimately, unlocking AI's
potential is a team effort that relies on intentional design, continuous
upskilling, and a strong, integrated foundation.Why SBOMs, signing, and provenance still don’t tell you if software is safe
While current software security practices like tracking components and
verifying origins are helpful, they are no longer enough to keep systems safe.
Tools that show what is inside a program or prove who made it do not answer
the most important question: what the code will actually do once it is
running. A program might have a verified source and a clean list of
ingredients, yet still attempt to steal passwords or expose private data. This
gap in security is becoming more urgent as artificial intelligence allows both
safe and harmful code to be written and changed faster than humans can review.
We cannot assume software is safe just because it comes from a known publisher
or looks familiar. Instead, we need to stop trusting software based only on
its identity or background. The next step is to evaluate how the code behaves
before allowing it to run. We must check if its actions, such as accessing
sensitive files or connecting to outside networks, are necessary and
appropriate for its purpose. By adopting a mindset where no code is trusted by
default, we can focus on verifying behavior rather than just origin, creating
a more reliable defense against modern threats.
























/articles/portable-systems-sovereignty/en/smallimage/Architecting-Portable-Systems-on-Open-Standards-for-Digital-Sovereignty-thumb-1773829386100.jpg)