Zscaler's Cloud-Based Cybersecurity Outages Showcase Redundancy Problem

Businesses also should ensure that they realize the cloud security and
reliability is a shared responsibility model. Cloud providers — including
cybersecurity services based in the cloud — are responsible for their
infrastructure, but companies should architect their cloud or hybrid
infrastructure to handle outages. Companies that know their cloud vendor's
architecture will be better prepared for outages, says CSA's Reavis. "It is
important to understand how the provider achieves redundancy in its
architecture, operating procedures including software updates, and its footprint
of global data centers," he says. "The customer should then understand how that
redundancy satisfies their own risk requirements and if their own architecture
takes full advantage of the redundancy capabilities." Business customers should
also regularly re-evaluate their technology landscape and risk profile. While
network and power failures — and natural disasters — used to dominate resilience
discussions, malicious threats such as ransomware and denial-of-service attacks
are often more likely to dominate discussions today, says Forrester's Maxim.
How Intuit’s Platform Engineering Team Chose an App Definition

An application definition is an operational runbook that describes in code
everything an application needs to be built, run and managed. ... “Our main
requirements for the app spec needed to be application-centric; there shouldn’t
be any leakage of cloud or Kubernetes resources into the application
specification. And it had to meet the deployment as well as the operational
needs of the application,” she said. “The two choices we had were the Open
Application Model, which suited our needs pretty well. Or we could go with a
templating style model where you had to provide a bunch of input parameters. But
there was also a lot of abstraction leaked into the application spec. So it was
easy for us to go with an application OAM-style specification.” At a high level,
the developer should be able to describe his intent, “This is the image that I
want; here are my sizing needs both horizontal and vertical. And I had a way to
override these traits, depending on my environment, and be able to generate the
Kubernetes resources.”
Into the Metaverse: Making the Case for a Virtual Workspace

“The ability to market and educate through the metaverse and VR is extremely
important because businesses are able to represent their products in a different
way and touch their consumers on a new level,” he says. “Additionally, consumers
will have social experiences that are frictionless, particularly as technology
improves.” As the technology becomes more intuitive to use, it’ll be easier for
consumers to get involved and discover things for the first time through the
metaverse. Edelson says from a marketing perspective, the metaverse allows
brands to implement creative marketing strategies that they could not
necessarily do if they had limited real estate or shelf space in a store. “From
a sales standpoint, the metaverse provides additional digital touchpoints and
KPIs,” he adds. “Businesses have the ability to judge and understand consumer
sentiment around how they are interacting with a virtual product or good,
providing key and valuable data.” He adds that TradeZing is a content-based
business, so the company examines and seeks content through a different medium
such as VR or the metaverse.
Geo-Distributed Microservices and Their Database: Fighting the High Latency
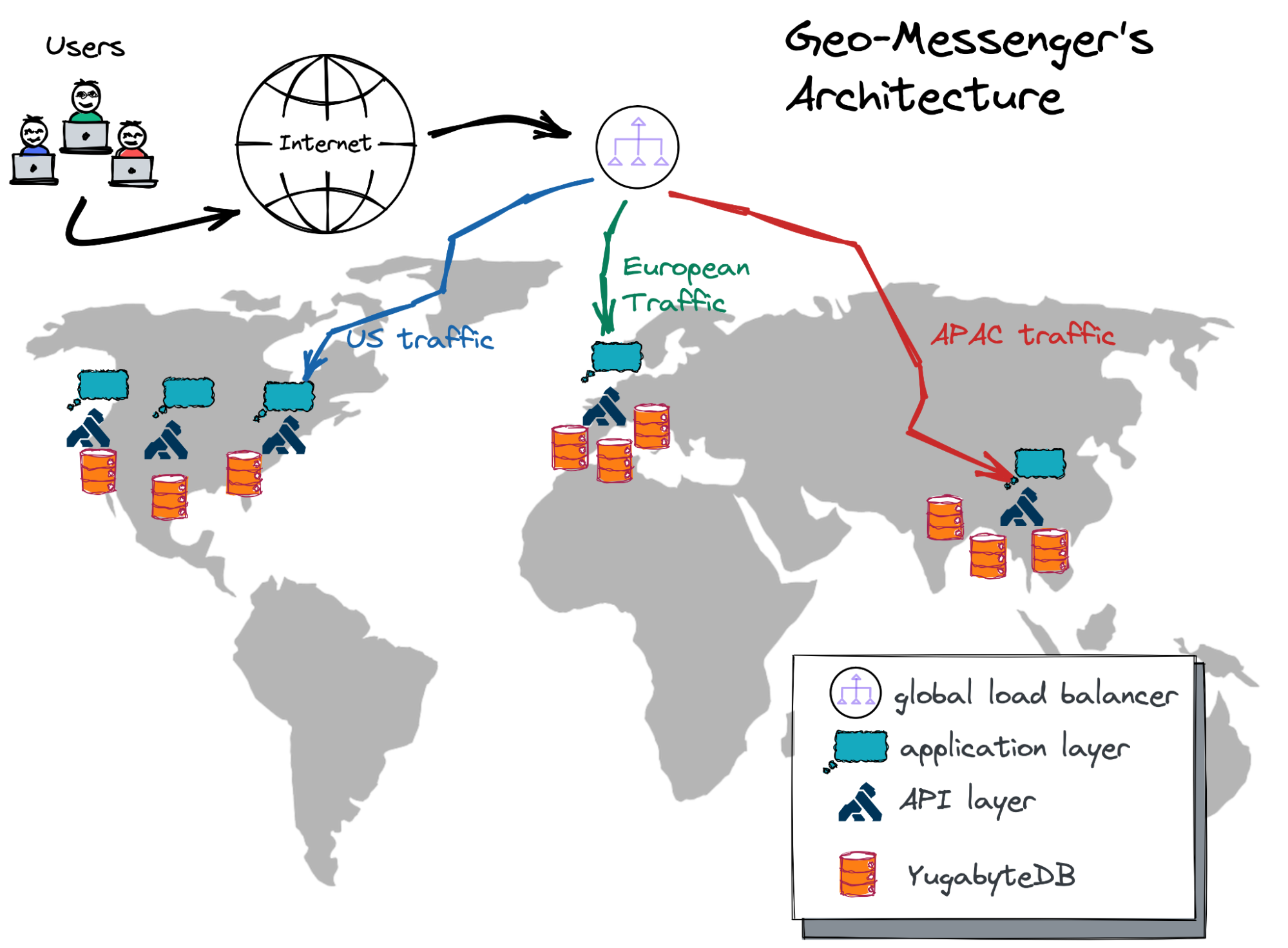
The microservice instances of the application layer are scattered across the
globe in cloud regions of choice. The API layer, powered by Kong Gateway, lets
the microservices communicate with each other via simple REST endpoints. The
global load balancer intercepts user requests at the nearest PoP
(point-of-presence) and forwards the requests to microservice instances that are
geographically closest to the user. Once the microservice instance receives a
request from the load balancer, it’s very likely that the service will need to
read data from the database or write changes to it. And this step can become a
painful bottleneck—an issue that you will need to solve if the data (database)
is located far away from the microservice instance and the user. In this
article, I’ll select a few multi-region database deployment options and
demonstrate how to keep the read and write latency for database queries low
regardless of the user’s location. So, if you’re still with me on this journey,
then, as the pirates used to say, “Weigh anchor and hoist the mizzen!” which
means, “Pull up the anchor and get this ship sailing!”
How to ensure 5G wireless network security

The RAN (Radio Access Network) is the actual antenna carrying the radio waves
at the 5G spectrum. As Scott Goodwin from DigitalXRAID says: “They are the very edge of the whole ecosystem, on cell towers placed
as close to end users as possible and act as a conduit from the radio world to
packet-switched or IP-based digital network.” The RAN presents unique
challenges, not least the risk of physical damage to antennas — not
necessarily deliberate, but potentially so. Consider, for example, how during
the height of the Covid epidemic, some individuals blamed 5G for exacerbating
Covid and tried to damage the masts. For organisations trying to ensure 5G
wireless network security, there isn’t much they can do to protect cell towers
— these are outside their control. But they will need contingency plans; they
will need to plan to ensure business continuity. In short, they will need to
understand the risks and plan accordingly. “I think that a lot of
organisations and enterprises have got to start to think in new ways about
business continuity,” says Belcher, “especially in light of what’s happened
over the last couple of years.”
Kent Beck: Software Design is an Exercise in Human Relationships
The first relationship is between the idea being explored and the behaviour
that will bring that idea into being. The relationship is bidirectional and
evolving - the idea defines the behaviour and the existence of the behaviour
can generate more ideas (now that I see this, what about that…). Underneath
the idea and behaviour is the structure of the system. This is the
architecture and it has a profound effect on the visible behaviour. The
structure of the system has a profound effect on the behaviour, and on the
ideas that get generated because the behaviour can change. Structure
influences behaviour, which results in new ideas requesting changes to
behaviour which can have an impact on structure, in a continuous loop. The
Tidy First? workflow causes us to pause and ask if the structure needs to be
changed or should we just implement the behaviour change. If the change needs
to impact the structure then Tidy the structure First - refactor the
underlying architecture as needed. Do NOT try to make structure and behaviour
changes at the same time, as that is where systems devolve in technical
debt.
When Is It Time to Stop Using Scrum?

Some indicators help Scrum teams understand whether their progress as a team,
as well as the product’s increasing maturity, justify inspecting their
original decision to use Scrum, for example:Increasing product maturity leads
to progress becoming more steady and less volatile; there are fewer
disruptions in delivering Increments. There are fewer match points to score,
and progress becomes more incremental—focusing on minor improvements—as the
“big features” are already available. The Scrum team experiences growing
difficulties in creating team-unifying Sprint Goals; there is a growing number
of Product Backlog items that cannot be clustered under one topic. Reduced
volatility results in an expanding planning horizon. At least, there is a
temptation to plan further ahead, which also suits the team’s stakeholder
relationship management. Stakeholders gain more trust in the team’s
capabilities, resulting, for example, in less engagement in Sprint Reviews.
Metaphorically speaking, the Scrum team moves from leaping forward to walking
steadily.
Edge computing: 5 must-have career skills

When the networking is good enough, then it’s good enough – remote compute and
storage isn’t as pressing of a need because the data is going back to a
centralized environment. But when low latency is a critical requirement – and
that’s one of the essential purposes for edge computing – organizations will
need to be able to deliver the necessary infrastructure resources on site. AI
workloads with large datasets, for example, or applications that require
near-real-time feedback loops may be better served on-site – which means they
need compute, storage, and other resources to run properly. Nelson notes that
edge infrastructure can require capabilities that fall outside of the typical
data center or cloud engineer’s experience. “Managing edge compute at scale
can be very different than traditional data center management,” Nelson.
“Thousands of devices across hundreds of sites with little to no onsite staff
can be daunting.” As Haff from Red Hat notes, you can’t usually send a help
desk pro out to the edge every time one of those devices needs maintenance.
Younger workers want training, flexibility, and transparency

Regardless of the root causes, younger workers are sending a clear signal to
leaders that they want more training and development, particularly in newer
technical and digital skills. And given the (likely permanent) shift to hybrid
work, they will need more career guidance, coaching, and mentoring—all of
which will require companies to rethink how they can best support remote and
hybrid workers and foster a strong learning culture through both in-person and
virtual channels. Notably, technical skills are teachable. But softer skills
like collaboration, communication, and conflict resolution often are not—and
the younger workforce will need to learn these firsthand, through interactions
with colleagues. The flow of skills can also move in the other direction,
through reverse-mentoring initiatives that empower younger workers to partner
with executives and guide them in areas such as technology or social issues.
Reverse-mentoring gives younger workers a voice, builds relationships across
generations, and sends a clear signal that younger workers have valuable
contributions to offer.
The Next Evolution of Virtualization Infrastructure

For applications that were still tied to the data center, alternatives like
OpenStack emerged to enable scale-out virtualization infrastructure for both
private cloud and many public cloud Infrastructure as a Service deployments.
Red Hat OpenStack continues to provide a leading distribution in this space,
powering enterprise private cloud and telco 4G network function virtualization
environments. The third age of virtualization was actually a move away from
the hypervisor and traditional VMs: the age of containers. Just as
virtualization had broken physical servers into many individual virtual
servers each running their own OS, by leveraging the power of the hypervisor,
so too had containerization divided a single Linux OS running on those virtual
machines, or directly on bare metal servers, into even smaller application
sandboxes with the power of namespaces, cgroups and the Docker packaging
format, now standardized through the Open Container Initiative. This enabled
pioneering developers to build and provision containerized microservices on
their local machines and promote them to test, stage and production
environments, consistently and on demand.
Quote for the day:
"Nobody in your organization will be
able to sustain a level of motivation higher than you have as their leader."
-- Danny Cox
No comments:
Post a Comment