Should we measure developer productivity?

If we concede that it is possible to measure developer productivity (a
proposition that I am not completely sold on), we then must ask whether we
should do that. The desire to do so is certainly strong. Managers want to know
who their best developers are, and they want metrics that will help them at
performance evaluation time. HR wants to be able to document performance
issues. CEOs want to know that the money they are spending is being used
effectively. Even if you use new tools to measure individual developer
productivity, those metrics will likely be gamed. Lines of code is considered
a joke metric these days. “You want lines of code? I’ll give you lines of
code!” Is number of commits per day or average time to first PR comment any
different? If you measure individual developers on these metrics, they will
most definitely improve them. But at what cost? Likely at the cost of team
productivity. An old CEO of mine used to say that software development is a
team sport. If individual developers are measured against each other on any
metric, they will start competing with each other, especially if money and
promotions are on the line.
Technology spending will rise next year. And this old favourite is still a top priority

White says huge macro-economic pressures around the globe are causing senior
executives to think much more carefully about how to get close to customers,
to boost growth, and to potentially take cost out of the business. She also
refers to pressures on supply chains. Executives have seen the disruptions
caused first by the pandemic and then Russia's invasion of Ukraine, and are
now looking for tools to respond flexibly to fluctuations in supply and
demand. The solutions to many of these challenges, says White, are likely to
come via technology. And for many businesses, the starting point for that
response is going to a continued investment in cloud computing. This focus
on on-demand IT might seem surprising. After a decade or more on the IT
agenda, and a couple of years of targeted investment due to the pandemic,
you'd be forgiven for assuming that a shift to cloud computing was
yesterday's news. ... However, the Nash Squared survey shows that interest
in the cloud is still very much today's priority. "It's still growing and
evolving as a market, with a quite young set of technologies and
capabilities," says White.
A modern approach to enterprise software development

Given the potential benefits that low-code tools offer in terms of enabling
people in the business to develop their own software to improve the
efficiency of the business processes with which they interact, the industry
is recognising the massive risk that this poses. Dyson’s Wilmot said the
business has concentrated on operational excellence focused on project
audits, adding that people and the process around low-code development are
crucial. He suggested that CIOs should decide: “Who will be your core
low-code coders in IT and in the business?” Wilmot also urged CIOs
considering the idea of opening up low-code development to business users
who would like to code, to ensure that processes are in place to prevent the
code they develop from “running wild”. Clearly there are numerous
opportunities to improve on how things work, especially in organisations
that have grown organically over time, where, to achieve a business
objective, employees need to use numerous systems that don’t talk to each
other. More often than not, data has to be rekeyed, which is both
error-prone and labour-intensive.
Three Ingredients of Innovative Data Governance

The first important feature of innovative data governance is providing a
data set that is statistically similar to the real data set without exposing
private or confidential data. This can be accomplished using synthetic data.
Synthetic data is created using real data to seed a process that can then
generate data that appears real but is not. Variational autoencoders (VAEs),
generative adversarial networks (GANs), and real-world simulation create
data that can provide a basis for experimentation without leaking real data
and exposing the organization to untenable risk. VAEs are neural networks
composed of encoders and decoders. During the encoding process, the data is
transformed in such a way that its feature set is compressed. During this
compression, features are transformed and combined, removing the details of
the original data. During the decoding process, the compression of the
feature set is reversed, resulting in a data set that is like the original
data but different. The purpose of this process is to identify a set of
encoders and decoders that generate output data that is not directly
attributable to the initial data source.
What’s Holding Up Progress in Machine Learning and AI? It’s the Data, Stupid

While companies are having some success in putting machine learning and AI
into production, they would be further along if data management issues
weren’t getting in the way, according to Capital One’s new report,
“Operationalizing Machine Learning Achieves Key Business Outcomes,” which
was released today. ... “There’s a real appetite to scale that thing
quickly,” he says. “And if you don’t step back and say, hey, the thing you
stood up in the sandbox, let’s actually make sure that you’re systematizing
it, making it widely available, putting metadata on top of it, putting
traceability and flows, and doing sort of all the foundational scaffolding
and infrastructure steps that are needed for this thing to be sustainable
and reusable. “That requires a ton of discipline and hygiene and potentially
waiting a bit before the thing that you want to scale up starts to see
impact in the marketplace,” Kang continues. “The temptation is always there.
So what ends up happening, through no ill intent, is these proof of concepts
start to see impact, and then and then all of a sudden you find yourself in
a place where there’s a bunch of data silos and a bunch of other data
engineering infrastructure challenges.”
Twitter's CISO Takes Off, Leaving Security an Open Question

Twitter made huge strides towards a more rational internal security model
and backsliding will put them in trouble with the FTC, SEC, 27 EU DPAs and a
variety of other regulators," he said — ironically, in a tweet. "There is a
serious risk of a breach with drastically reduced staff." Many others also
view the cuts and the exodus of senior executives — both voluntarily and
involuntarily — as severely crippling the social media giant's capabilities,
especially in critical areas such as security, privacy, spam, fake accounts,
and content moderation. "These are huge losses to Twitter," says Richard
Stiennon, chief research analyst at IT-Harvest. "Finding qualified
replacements will be extremely expensive." Kissner's exit is sure to add to
what many view as a deepening crisis at Twitter following Musk's takeover.
Among those that have been axed previously are CEO Parag Agarwal, chief
financial officer Ned Segal, legal chief Vijaya Gadde, and general counsel
Sean Edgett. Teams affected by Musk's layoffs reportedly include
engineering, product teams, and those responsible for content creation,
machine learning ethics, and human rights.
How to prepare for ransomware

We know that bad actors are motivated by financial gains, and we are
starting to see evidence where they are mining the exfiltrated data for
additional sources of potential revenue. For many years, the cyber security
community has been saying it’s not a case of “if” you’ll be attacked, but
“when”. That being the case, it is important to examine all these phases and
make sure that adequate time and effort is allocated to preparing to defend
against and prevent an incident, while also conducting the requisite
detection, response and recovery activities. IT security leaders should work
under the assumption that a ransomware attack will be successful, and ensure
that the organisation is prepared to detect it as early as possible and
recover as quickly as possible. The ability to quickly detect and contain a
ransomware attack will have the biggest impact on any outage or disruption
that is caused. The first and most common question is: should the ransom be
paid? Ultimately, this has to be a business decision. It needs to be made at
an executive or board level, with legal advice.
The unimon, a new qubit to boost quantum computers for useful applications
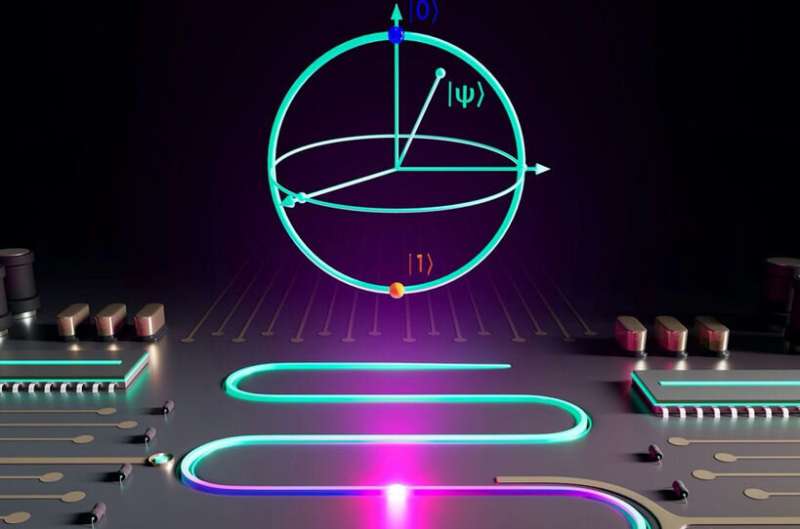
To experimentally demonstrate the unimon, the scientists designed and
fabricated chips, each of which consisted of three unimon qubits. They used
niobium as the superconducting material apart from the Josephson junctions,
in which the superconducting leads were fabricated using aluminum. The team
measured the unimon qubit to have a relatively high anharmonicity while
requiring only a single Josephson junction without any superinductors, and
bearing protection against noise. The geometric inductance of the unimon has
the potential for higher predictability and yield than the
junction-array-based superinductors in conventional fluxonium or quarton
qubits. "Unimons are so simple and yet have many advantages over transmons.
The fact that the very first unimon ever made worked this well, gives plenty
of room for optimization and major breakthroughs. As next steps, we should
optimize the design for even higher noise protection and demonstrate
two-qubit gates," added Prof. Möttönen.
Data privacy: why consent does not equal compliance

A serious blind spot for brands is caused by consent models. Many
organisations assume that obtaining consent from users to collect and
process their data ensures compliance. In reality, consent does not equal
compliance. Many brands operate under an illusion of compliance, when, in
fact, they are routinely leaking personal data across their media supply
chain and tolerating the unlawful collection and sharing of data by
unauthorised third parties. Research from Compliant reveals that there
are a number of ways in which brands are inadvertently putting themselves at
risk. For example, our analysis shows that of the 91 per cent of the EU
advertisers using a Consent Management Platform (CMP), 88 per cent are
passing user data to third-parties before receiving consent to do so. While
a properly implemented CMP is a useful tool for securing consent,
integrating them with legacy technologies and enterprise architectures is
clearly a problem. Another risk stems from “piggybacking”, where
unauthorised cookies and tags collect data from brand websites without the
advertiser’s permission. P
Machine learning: 4 adoption challenges and how to beat them

Machine learning algorithms may still behave unpredictably after training to
prepare for data analysis. This lack of clarity might be an issue when
leveraging AI in decision-making leads to unexpected outcomes. As the
Harvard Business School reported in its 2021 Hidden Workers: Untapped Talent
report, ML-based automated hiring software rejected many applicants due to
overly rigid selection criteria. That’s why ML-based analysis should always
be complemented with ongoing human supervision. Talented experts should
monitor your ML system’s operation on the ground and fine-tune its
parameters with additional training datasets that cover emerging trends or
scenarios. Decision-making should be ML-driven, not ML-imposed. The system's
recommendation must be carefully assessed and not accepted at face value.
Unfortunately, combining algorithms and human expertise remains challenging
due to the lack of ML professionals in the job market.
Quote for the day:
"Good leaders must first become good servants." -- Robert Greenleaf
No comments:
Post a Comment