Science Made Simple: What Is Exascale Computing?

Exascale computing is unimaginably faster than that. “Exa” means 18 zeros. That
means an exascale computer can perform more than 1,000,000,000,000,000,000
FLOPS, or 1 exaFLOP. That is more than one million times faster than ASCI Red’s
peak performance in 1996. Building a computer this powerful isn’t easy. When
scientists started thinking seriously about exascale computers, they predicted
these computers might need as much energy as up to 50 homes would use. That
figure has been slashed, thanks to ongoing research with computer vendors.
Scientists also need ways to ensure exascale computers are reliable, despite the
huge number of components they contain. In addition, they must find ways to move
data between processors and storage fast enough to prevent slowdowns. Why do we
need exascale computers? The challenges facing our world and the most complex
scientific research questions need more and more computer power to solve.
Exascale supercomputers will allow scientists to create more realistic Earth
system and climate models.
What CISA Incident Response Playbooks Mean for Your Organization
Most of the time, organizations struggle to exercise their incident response and
vulnerability management plans. An organization can have the best playbook out
there, but if it doesn’t exercise it on a regular basis, well, ‘If you don’t use
it, you lose it’. It needs to make sure that its playbooks have the proper scope
so that everyone from executives to everyone else within the organization knows
what they need to know… When I say ‘exercise’, it’s important that organizations
test their plans under realistic conditions. I’m not saying they need to unplug
a device or bring in simulated bad code. They just need to make sure everyone
tasked in the playbook knows what’s going on, understands what their roles are
and periodically tests the plans. They can take the lessons they’ve learned and
refine them. Incident response exercises don’t end with victory. They end with
lessons for the future. Ultimately, documents that sit on a shelf rarely get
read. To be high-performing, industry, government and critical infrastructure
organizations need to continue to test their technology, processes and
people.
Is Remix JS the Next Framework for You?

While the concept of a route is not new in any web framework really, the
definition of one begins in Remix by creating the file that will contain its
handler function. As long as you define the file inside the right folder, the
framework will automatically create the route for you. And to define the right
handler function, all you have to remember, is to export it as a default export.
... For static content, the above code snippet is fantastic, but if you’re
looking to create a web application, you’ll need some dynamic behavior. And that
is where Loaders and Actions come into play. Both are functions that if you
export them, the handler will execute before its actual code. These functions
receive multiple parameters, including the HTTP request and the URLs params and
payloads. The loader function is specifically called for GET verbs on
routes and it’s used to get data from a particular source (i.e reading from
disk, querying a database, etc). The function gets executed by Remix, but you
can access the results by calling the useLoaderData function.
3 Fintech Trends of 2022 as seen by the legal industry
User consent is the foundation of open banking, whilst transparency as to where
their data goes and who it is shared with is a necessary pre-condition of
customer trust. The fintech sector should avoid following in the footsteps of
the ad-tech industry, where entire ecosystems were built with a disregard for
individuals’ rights and badly worded consent requests. Here, data collected by
tracking technologies sunk into the ad-tech ecosystems without a trace, leaving
privacy notices so confusing and complex that even seasoned data protection
lawyers struggled to understand them. The full potential of open banking can
only happen if financial ecosystems are built on transparency which gives users
control over who can access their financial data and how it can be used. ...
Innovative fintech solutions will need to strike the right balance between the
need for regulatory compliance regarding consent, authentications, security and
transparency on the one hand, and seamless user experience on the other, in
particular when more complex ecosystems and relationships between various
products start emerging.
Short-Sightedness Is Failing Data Governance; a Paradigm Shift Can Rectify It

“While organisations understand that data governance is important, many in the
region feel that they have invested enough. And that's why data governance
implementations are failing because it's still seen largely as an expense,” says
Budge in an exclusive interview with Data & Storage Asean. “There's no doubt
that it is a significant expense but rightly so, given that so much of digital
transformation success is hinged on the proper deployment and consistent
execution of a data governance program. Essentially, data governance is not a
one-off investment—something you build and walk away—but requires actual ongoing
practice and oversight.” Budge adds: “Executives often see only the upfront
costs. For the short-sighted, the costs alone are reason enough to curtail
further investment. ...” This short-sightedness, though, is not the only reason
data governance is largely failing. Another pain point is what Budge describes
as “the lack of understanding of the importance of a sound data governance
strategy and the value that it can drive.”
Meta is developing a record-breaking supercomputer to power the metaverse

According to Meta, realizing the benefits of self-supervised learning and
transformer-based models requires various domains — whether vision, speech,
language, or for critical applications like identifying harmful content. AI at
Meta’s scale will require massively powerful computing solutions capable of
instantly analyzing ever-increasing amounts of data. Meta’s RSC is a
breakthrough in supercomputing that will lead to new technologies and customer
experiences enabled by AI, said Lee. “Scale is important here in multiple
ways,” said Lee. ... “Secondly, AI projects depend on large volumes of data —
with more varied and complete data sets providing better results. Thirdly, all
of this infrastructure has to be managed at the end of the day, and so space
and power efficiency and simplicity of management at scale is critical as
well. Each of these elements is equally important, whether in a more
traditional enterprise project or operating at Meta’s scale,” Lee said.
How AI Will Impact Your Daily Life In The 2020s
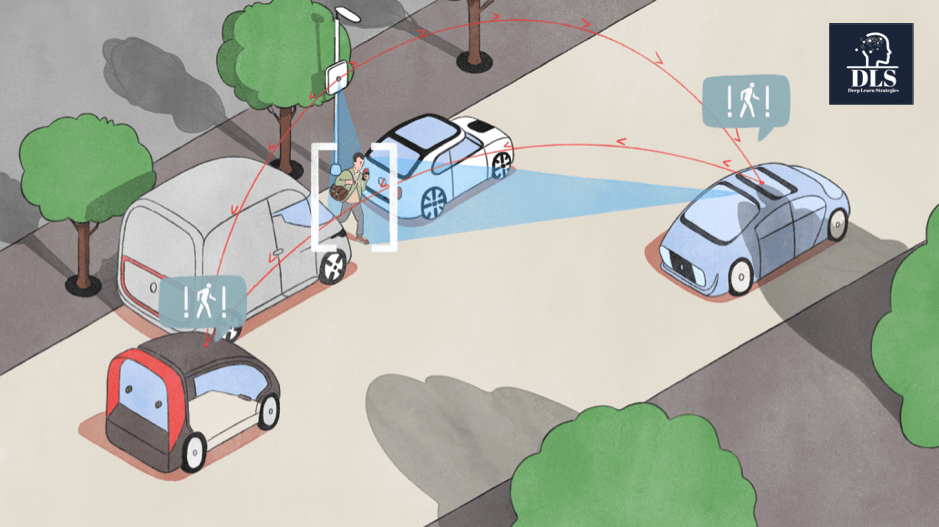
Every single sector of the economy will be transformed by AI and 5G in the
next few years. Autonomous vehicles may result in reduced demand for cars and
car parking spaces within towns and cities will be freed up for other usage.
It maybe that people will not own a car and rather opt to pay a fee for a car
pooling or ride share option whereby an autonomous vehicle will pick them up
take them to work or shopping and then rather than have the vehicle remain
stationary in a car park, the same vehicle will move onto its next customer
journey. The interior of the car will use AR with Holographic technologies to
provide an immersive and personalised experience using AI to provide targeted
and location-based marketing to support local stores and restaurants. Machine
to machine communication will be a reality with computers on board vehicles
exchanging braking, speed, location and other relevant road data with each
other and techniques such as multi-agent Deep Reinforcement Learning may be
used to optimise the decision making by the autonomous vehicles.
My New Big Brain Way To Handle Big Data Creatively In Julia

In 2022, 8-gigabytes of memory is quite a low amount, but usually this is not
such a big hindrance until the point where it would likely be a big hindrance
for someone else. Really what has happened is that Julia has spoiled us. I
know that I can pass fifty-million observations through something with no
questions, comments, or concerns from my processor in Julia, no problem. It is
the memory, however, that I am often running into the limits of. That being
said, I wanted to explore some ideas on decomposing an entire feature’s
observations into a “ canonical form” of sorts, and I started researching
precisely those topics. My findings in regards to ways to preserve memory have
been pretty cool, so I thought it might be an interesting read to look at what
all I have learned, and additionally a pretty nice idea I came up with myself.
All of this code is part of my project, OddFrames.jl, which is just a
Dataframes.jl alternative with more features, and I am almost ready to publish
this package.
Four Trends For Cellular IoT In 2022

No-code applied to cellular IoT management is an alternative to API, an
accessible route to automation for non-developer teams. According to Gartner,
41% of employees outside the IT function are customizing or building data or
technology solutions. The interest and willingness are there. The tools
increasingly so. Automation tools enable teams with minimal to no hand-coding
experience to automate workflows that would previously wait in a backlog for
the attention of a specialist developer. IoT needs scale; there can be no
hold-ups or bottlenecks in bringing projects to completion. Applying the
benefits of no-code to cellular IoT addresses this. There will always be a
high demand for skilled software developers to tackle complex development
projects. The transition to the cloud did not drop system administrators, and
no-code solutions will not replace specialist software developers; development
ability is still needed. The no-code opportunity is in repetitive tasks such
as activating an IoT SIM card. Using no-code, this workflow can easily be
automated and free up developer resources for more complex integrations.
Web3 – but Who’s Counting?

Regardless of the technology that eventually supports Web3, the key will be
distribution; data can’t be trapped in a single place. Let me give you an
example: data.world may seem like a Web 2.0 application. It’s collaborative,
users generate content in the form of data and analysis, which can be loaded
into our servers. That can feel like handing over control. However, unlike the
case for today’s data brokers — Facebook, Amazon, etc. — you didn’t give up
rights to your data; it is still yours to modify, restrict, or even delete at
your discretion. More technically, data.world is built on the Semantic Web
standards. This means that if you don’t want your data hosted by data.world,
that’s just fine. Host it under some other SPARQL endpoint, give data.world a
pointer to your data, and it will behave just the same as if it were hosted
with us. Deny access to that endpoint — or just remove it — and it’s gone.
This is not to say that data.world is the solution to Web3, here today; far
from it. We still don’t really know what Web3 will turn out to be. But one
thing is for certain — any Web3 platform will have to play in a world of
distributed data.
Quote for the day:
"Small disciplines repeated with
consistency every day lead to great achievements gained slowly over time."
-- John C. Maxwell
1 comment:
thnks
Post a Comment