Stop Using Microservices. Build Monoliths Instead.

Building out a microservices architecture takes longer than rolling the same
features into a monolith. While an individual service is simple, a collection of
services that interact is significantly more complex than a comparable monolith.
Functions in a monolith can call any other public functions. But functions in a
microservice are restricted to calling functions in the same microservice. This
necessitates communication between services. Building APIs or a messaging system
to facilitate this is non-trivial. Additionally, code duplication across
microservices can’t be avoided. Where a monolith could define a module once and
import it many times, a microservice is its own app — modules and libraries need
to be defined in each. ... The luxury of assigning microservices to individual
teams is reserved for large engineering departments. Although it’s one of the
big touted benefits of the architecture, it’s only feasible when you have the
engineering headcount to dedicate several engineers to each service. Reducing
code scope for developers gives them the bandwidth to understand their code
better and increases development speed.
DevOps at the Crossroads: The Future of Software Delivery

Even though DevOps culture is becoming mainstream, organizations are struggling
with the increasing tool sprawl, complexity and costs. These teams are also
dealing with a staggering (and growing) number of tools to help them get their
work done. This has caused toil, with no single workflow and lack of visibility.
At Clear Ventures, the problems hit close to home as 17 of the 21 companies we
had funded had software development workflows that needed to be managed
efficiently. We found that some of the companies simply did not have the
expertise to build out a DevOps workflow themselves. On the other hand, other
companies added expertise over time as they scaled up but that required them to
completely redo their workflows resulting in a lot of wasted code and effort. We
also noticed that the engineering managers struggled with software quality and
did not know how to measure productivity in the new remote/hybrid working
environment. In addition, developers were getting frustrated with the lack of
ability to customize without a significant burden on themselves.
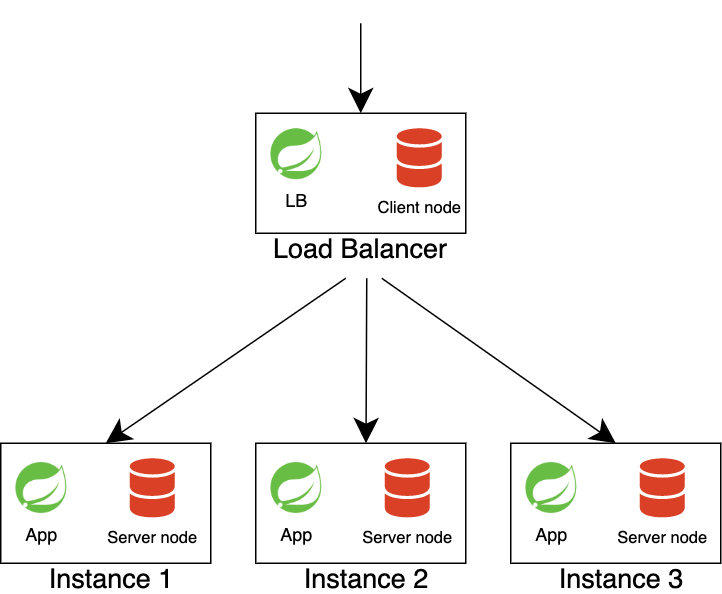
A stateful architecture was invented to solve these problems, where database and
cache are started in the same process as applications. There are several
databases in the Java world that we can run in embedded mode. One of them is
Apache Ignite. Apache Ignite supports full in-memory mode (providing
high-performance computing) as well as native persistence. This architecture
requires an intelligent load balancer. It needs to know about the partition
distribution to redirect the request to the node where the requested data is
actually located. If the request is redirected to the wrong node, the data will
come over the network from other nodes. Apache Ignite supports data collocation,
which guarantees to store information from different tables on the same node if
they have the same affinity key. The affinity key is set on table creation. For
example, the Users table (cache in Ignite terms) has the primary key userId, and
the Orders table may have an affinity key - userId.
Here’s Why You Should Consider Becoming a Data Analyst

Data analysts specialize in gathering raw data and being able to derive insights
from it. They have the patience and curiosity to poke around large amounts of
data until they find meaningful information from it — after which they clean and
present their findings to stakeholders. Data analysts use many different tools
to come up with answers. They use SQL, Python, and sometimes even Excel to
quickly solve problems. The end goal of an analyst is to solve a business
problem with the help of data. This means that they either need to have
necessary domain knowledge, or work closely with someone who already has the
required industry expertise. Data analysts are curious people by nature. If they
see a sudden change in data trends (like a small spike in sales at the end of
the month), they would go out of their way to identify if the same patterns can
be observed throughout the year. They then try to piece this together with
industry knowledge and marketing efforts, and provide the company with advice on
how to cater to their audience.
Siloscape: The Dark Side of Kubernetes

Good IT behavior starts with the user. As someone who has witnessed the impacts
of ransomware firsthand, I can attest to the importance of having good password
hygiene. I recommend using unique, differentiated passwords for each user
account, ensuring correct password (and data) encryption when static or in
transit and keeping vulnerable and valuable data out of plaintext whenever
possible. In the case of Kubernetes, you must ensure that you understand how to
secure it from top to bottom. Kubernetes offers some of the most well-written
and understandable documentation out there and includes an entire section on how
to configure, manage and secure your cluster properly. Kubernetes can be an
awesome way to level-up applications and services. Still, the importance of
proper configuration of each Kubernetes cluster cannot be overstated. In
addition to good hygiene, having a trusted data management platform in place is
essential for making protection and recovery from ransomware like Siloscape less
burdensome.
An Introduction to Hybrid Microservices
Put simply, a hybrid microservices architecture comprises a mix of the two
different architectural approaches. It comprises some components that adhere to
the microservices architectural style and some other components that follow the
monolithic architectural style. A hybrid microservices architecture is usually
comprised of a collection of scalable, platform-agnostic components. It should
take advantage of open-source tools, technologies, and resources and adopt a
business-first approach with several reusable components. Hybrid microservices
architectures are well-suited for cloud-native, containerized applications. A
hybrid microservices-based application is a conglomeration of monolithic and
microservices architectures – one in which some parts of the application are
built as a microservice and the remaining parts continue to remain as a
monolith. ... When using microservices architecture in your application
the usual approach is to refactor the application and then implement the
microservices architecture in the application.
The Inevitability of Multi-Cloud-Native Apps

Consistently delivering rapid software iteration across a global footprint
forces DevOps organizations to grapple with an entirely new set of technical
challenges: Leveraging containerized applications and microservices
architectures in production across multiple Kubernetes clusters running in
multiple geographies. Customers want an on-demand experience. This third phase
is what we call multi-cloud-native, and it was pioneered by hyperscale IaaS
players like Google, AWS, Azure and Tencent. The reality is, of course, that
hyperscalers aren’t the only ones who have figured out how to deliver
multi-cloud-native apps. Webscale innovators like Doordash, Uber, Twitter and
Netflix have done it, too. To get there, they had to make and share their
multi-cloud-native apps across every geography where their customers live. And,
in turn, to make that happen they had to tackle a new set of challenges: Develop
new tools and techniques like geographically distributed, planet-scale databases
and analytics engines, application architectures that run apps on the backend
close to the consumer in a multi-cloud-native way.
DeepMind is developing one algorithm to rule them all

The key thesis is that algorithms possess fundamentally different qualities when
compared to deep learning methods — something Blundell and Veličković elaborated
upon in their introduction of NAR. This suggests that if deep learning methods
were better able to mimic algorithms, then generalization of the sort seen with
algorithms would become possible with deep learning. Like all well-grounded
research, NAR has a pedigree that goes back to the roots of the fields it
touches upon, and branches out to collaborations with other researchers. Unlike
much pie-in-the-sky research, NAR has some early results and applications to
show. We recently sat down to discuss the first principles and foundations of
NAR with Veličković and Blundell, to be joined as well by MILA researcher
Andreea Deac, who expanded on specifics, applications, and future directions.
Areas of interest include the processing of graph-shaped data and
pathfinding.
Microservices Transformed DevOps — Why Security Is Next

Microservices break that same application into tens or hundreds of small
individual pieces of software that address discrete functions and work together
via separate APIs. A microservices-based approach enables teams to update those
individual pieces of software separately, without having to touch each part of
the application. Development teams can move much more quickly and software
updates can happen much more frequently because releases are smaller. This shift
in the way applications are built and updated has created a second
movement/change: how software teams function and work. In this modern
environment, software teams are responsible for smaller pieces of code that
address a function within the app. For example, let’s say a pizza company has
one team (Team 1) solely focused on the software around ordering and another
(Team 2) on the tracking feature of a customer’s delivery. If there is an update
to the ordering function, it shouldn’t affect the work that Team 2 is doing. A
microservices-based architecture is not only changing how software is created
Transitioning from Monolith to Microservices
While there are many goals for a microservice architecture, the key wins are flexibility, delivery speed, and resiliency. After establishing your baseline for the delta between code commit and production deployment completion, measure the same process for a microservice. Similarly, establish a baseline for “business uptime” and compare it to that of your post-microservice implementation. “Business uptime” is the uptime required by necessary components in your architecture as it relates to your primary business goals. With a monolith, you deploy all of your components together, so a fault in one component could affect your entire monolithic application. As you transition to microservices, the pieces that remain in the monolith should be minimally affected, if at all, by the microservice components that you’re creating. ... Suppose you’ve abstracted your book ratings into a microservice. In that case, your business can still function—and would be minimally impacted if the book ratings service goes down—since what your customers primarily want to do is buy books.
Quote for the day:
"The essence of leadership is not
giving things or even providing visions. It is offering oneself and one's
spirit." -- Lee Bolman & Terence Deal
No comments:
Post a Comment