Multi-User IP Address Detection
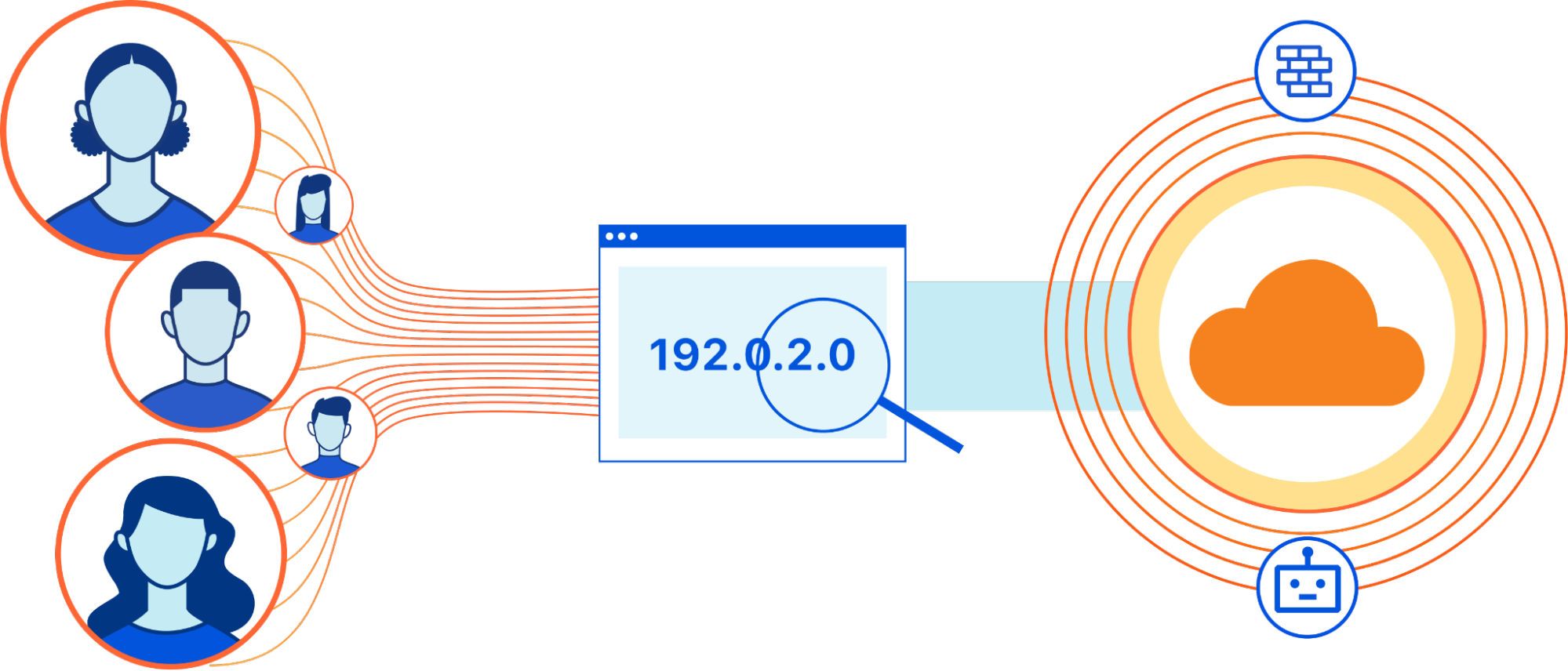
When an Internet user visits a website, the underlying TCP stack opens a
number of connections in order to send and receive data from remote servers.
Each connection is identified by a 4-tuple (source IP, source port,
destination IP, destination port). Repeating requests from the same web client
will likely be mapped to the same source port, so the number of distinct
source ports can serve as a good indication of the number of distinct client
applications. By counting the number of open source ports for a given IP
address, you can estimate whether this address is shared by multiple users.
User agents provide device-reported information about themselves such as
browser and operating system versions. For multi-user IP detection, you can
count the number of distinct user agents in requests from a given IP. To avoid
overcounting web clients per device, you can exclude requests that are
identified as triggered by bots and we only count requests from user agents
that are used by web browsers. There are some tradeoffs to this approach: some
users may use multiple web browsers and some other users may have exactly the
same user agent.
Critical infrastructure security dubbed 'abysmal' by researchers

"While nation-state actors have an abundance of tools, time, and resources,
other threat actors primarily rely on the internet to select targets and
identify their vulnerabilities," the team notes. "While most ICSs have some
level of cybersecurity measures in place, human error is one of the leading
reasons due to which threat actors are still able to compromise them time and
again." Some of the most common issues allowing initial access cited in the
report include weak or default credentials, outdated or unpatched software
vulnerable to bug exploitation, credential leaks caused by third parties,
shadow IT, and the leak of source code. After conducting web scans for
vulnerable ICSs, the team says that "hundreds" of vulnerable endpoints were
found. ... Software accessible with default manufacturer credentials allowed
the team to access the water supply management platform. Attackers could have
tampered with water supply calibration, stop water treatments, and manipulate
the chemical composition of water supplies.
What is a USB security key, and how do you use it?

There are some potential drawbacks to using a hardware security key. First of
all, you could lose it. While security keys provide a substantial increase in
security, they also provide a substantial increase in responsibility. Losing a
security key can result in a serious headache. Most major websites suggest
that you set up backup 2FA methods when enrolling a USB security key, but
there's always a small but real chance that you could permanently lose access
to a specific account if you lose your key. Security-key makers suggest buying
more than one key to avoid this situation, but that can quickly get expensive.
Cost is another issue. A hardware security key is the only major 2FA method
for which you have to spend money. You can get a basic U2F/WebAuthn security
key standards for $15, but some websites and workplaces require specialized
protocols for which compatible keys can cost up to $85 each. Finally, limited
usability is also a factor. Not every site supports USB security keys. If
you're hoping to use a security key on every site for which you have an
account, you're guaranteed to come across at least a few that won't accept
your security key.
Future-proofing the organization the ‘helix’ way

The leaders need a high level of domain expertise, obviously, but other skills
as well. As capability managers, these leaders must excel at strategic
workforce management, for example—not short-sighted resource attribution for
the products at hand, but the strategic foresight and long-term perspective to
understand what the workload will be today, tomorrow, three to five years from
now. They need to understand what skills they don’t have in-house and must
acquire or build. These leaders become supply-and-demand managers of
competence. They must also be excellent—and rigid—portfolio managers who make
their resource decisions in line with the overall transformation. The R&D
organization, for example, cannot start research projects inside a product
line whose products are classified as “quick return,” even if they have people
idle. It’s a different mindset. In fact, R&D leaders don’t necessarily
have to be the best technologists in order to be successful. They must be
farsighted and able to anticipate trends—including technological trends—but
ultimately what matters is their ability to build the department in a way that
ensures it’s ready to carry the demands of the organization going forward.
Robots Will Replace Our Brains

Over the years, despite numerous fruitless attempts, no one has come close to
achieving the recreation of this organ with all its intricate details; it is
challenging to fathom such an invention in the scientific world at this point,
considering the discoveries that surface every other day. As one research
director mentions, we are very good at gathering data and developing
algorithms to reason with that data. Nevertheless, that reasoning is only as
sound as the data, one step removed from reality for the AI we have now. For
instance, all science fiction movies conceive movies that depict only a mere
thin line that separates human intelligence from artificial intelligence. ...
A new superconducting switch is being constructed by researchers at the U.S.
National Institute of Standards and Technology (NIST) and updated that will
soon enable computers to analyze and make decisions just like humans do. The
conclusive goal is to integrate this switch into everyday life; from
transportation to medicine, this invention also contains an artificial
synapse, processes electrical signals just like a biological synapse does, and
converts it to an adequate output, just like the brain does.
Data Storage Strategies - Simplified to Facilitate Quick Retrieval of Data and Security

No matter what the reason for the downtime, it may be very costly. An
efficient data strategy goes beyond just deciding where data will be kept on a
server. When it comes to disaster recovery, hardware failure, or a human
mistake, it must contain methods for backing up the data and ensuring that it
is simple and fast to restore. Putting in place a disaster recovery plan,
although it is a good start and guarantees that data and the related systems
are available after a minimum of disruption is experienced. Cloud-based
disaster recovery, as well as virtualization, are now required components of
every disaster recovery strategy. They can work together to assure you that no
customer will ever experience more downtime than they can afford at any given
moment. By relying only on the cloud storage service, the company can
outsource the storage issue. By using online data storage, the business can
minimize the costs associated with internal resources. With this technology,
the business does not need any internal resources or assistance to manage and
keep their data; the Data warehousing consulting services provider takes care
of everything.
RISC-V: The Next Revolution in the Open Hardware Movement

You could always build your own proprietary software and be better than your
competitors, but the world has changed. Now almost everyone is standing on the
shoulders of giants. When you need an operating system kernel for a new
project, you can use Linux directly. No need to recreate a kernel from
scratch, and you can also modify it for your own purpose (or write your
drivers). You’ll be certain to rely on a broadly tested product because you
are just one of a million users doing the same. That would be exactly what
relying on an open source CPU architecture could provide. No need to design
things from scratch; you can innovate on top of the existing work and focus on
what really matters to you, which is the value you are adding. At the end of
the day, it means lowering the barriers to innovate. Obviously, not everyone
is able to design an entire CPU from scratch, and that’s the point: You can
bring only what you need or even just enjoy new capabilities provided by the
community, exactly the same way you do with open source software, from the
kernel to languages.
The Conundrum Of User Data Deletion From ML Models

As the name says, approximation deletion enables us to eliminate the majority
of the implicit data associated with users from the model. They are
‘forgotten,’ but only in the sense that our models can be retrained at a more
opportune time. Approximate deletion is particularly useful for rapidly
removing sensitive information or unique features associated with a particular
individual that could be used for identification in the future while deferring
computationally intensive full model retraining to times of lower
computational demand. Approximate deletion can even accomplish the exact
deletion of a user’s implicit data from the trained model under certain
assumptions. The deletion challenge has been tackled differently by
researchers than by their counterparts in the field. Additionally, the
researchers describe a novel approximate deletion technique for linear and
logistic models that is feature-dimensionally linear and independent of
training data. This is a significant improvement over conventional systems,
which are superlinearly dependent on the extent at all times.
9 reasons why you’ll never become a Data Scientist

Have you ever invested an entire weekend in a geeky project? Have you ever
spent your nights browsing GitHub while your friends were out to party? Have
you ever said no to doing your favorite hobby because you’d rather code? If
you could answer none of the above with yes, you’re not passionate enough.
Data Science is about facing really hard problems and sticking at them until
you found a solution. If you’re not passionate enough, you’ll shy away at the
sight of the first difficulty. Think about what attracts you to becoming a
Data Scientist. Is it the glamorous job title? Or is it the prospect of
plowing through tons of data on the search for insights? If it is the latter,
you’re heading in the right direction. ... Only crazy ideas are good ideas.
And as a Data Scientist, you’ll need plenty of those. Not only will you need
to be open to unexpected results — they occur a lot! But you’ll also have to
develop solutions to really hard problems. This requires a level of
extraordinary that you can’t accomplish with normal ideas.
Why Don't Developers Write More Tests?
If deadlines are tight or the team leaders aren’t especially committed to
testing, it is often one of the first things software developers are forced to
skip. On the other hand, some developers just don’t think tests are worth
their time. “They might think, ‘this is a very small feature, anyone can
create a test for this, my time should be utilized in something more
important.’” Mudit Singh of LambdaTest told me. ... In truth, there are some
legitimate limitations to automated tests. Like many complicated matters in
software development, the choice to test or not is about understanding the
tradeoffs. “Writing automated tests can provide confidence that certain parts
of your application work as expected,” Aidan Cunniff, the CEO of Optic told
me, “but the tradeoff is that you’ve invested a lot of time ‘stabilizing’ and
making ‘reliable’ that part of your system.” ... While tests might have
made my new feature better and more maintainable, they were technically a
waste of time for the business because the feature wasn’t really what we
needed. We failed to invest enough time understanding the problem and making a
plan before we started writing code.
Quote for the day:
"Leaders are readers, disciples want to be taught and everyone has gifts
within that need to be coached to excellence." -- Wayde Goodall
No comments:
Post a Comment